Сравниваем Palantir Foundry и классический BI: чем операционные системы принятия решений отличаются от отчетов, дашбордов и витрин данных.
Отчёты и дашборды отлично отвечают на вопрос «что произошло?». Но бизнес чаще упирается в другое: «что делать дальше — и кто именно должен это сделать, по каким правилам, с какими данными и в какой срок». Когда решения принимаются в цепочках поставок, в производстве, в кредитном риске или в операциях сервиса, одной визуализации недостаточно — нужна связка данных, правил, ответственности и действий.
Материал для руководителей, аналитиков, владельцев процессов и ИТ-команд, которые узнают знакомые симптомы: цифры в отчётах расходятся, данные обновляются слишком поздно, решения «тонут» в переписке, а внедрение изменений занимает недели.
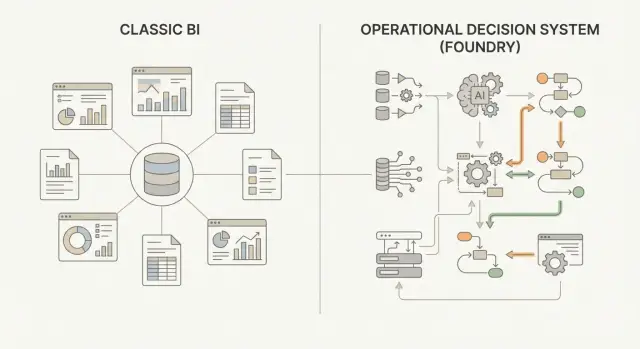
Традиционный BI — это в первую очередь слой отчётности и анализа поверх подготовленных данных: витрины, модели, метрики, визуализация. Palantir Foundry в таких обсуждениях чаще подразумевают как платформу, которая помогает не только анализировать, но и встраивать принятие решений в операционные процессы: от единой модели данных и контроля происхождения до запусков расчётов, согласований и исполнения.
Поэтому сравнивать их как «инструмент визуализации против инструмента визуализации» неверно. Правильнее сравнивать подходы: аналитика как наблюдение vs аналитика как управление.
Дальше разберём практические критерии выбора (актуальность данных, управление доступами, интеграции, стоимость владения) и сценарии, где «дашбордов мало», а ценность появляется только тогда, когда анализ превращается в конкретное действие.
Традиционный BI (Business Intelligence) — это класс инструментов для отчётности и анализа по историческим данным. Обычно в него входят витрины данных, OLAP-кубы, дашборды, KPI-метрики и регламентированные отчёты, которые помогают понять «что произошло» и «насколько мы попали в план».
На практике процесс часто строится так:
Подход хорошо работает, когда важно стандартизировать показатели, договориться о единой версии правды по KPI и регулярно отслеживать динамику.
Традиционный BI ценят за относительно быстрое внедрение (особенно для типовых кейсов), привычность для бизнеса и прозрачность метрик: видно, какие показатели считаются, по каким правилам и кто за них отвечает. BI также дисциплинирует данные: появляются справочники, единые определения, понятная периодичность обновлений.
Главное ограничение — разрыв между аналитикой и действием. Дашборд подсвечивает проблему, но дальше начинается ручная работа: выгрузить список, разослать письма, завести задачи, проконтролировать выполнение.
Второй барьер — задержки. Данные обновляются батчами (раз в день/неделю), из‑за чего решения принимаются по вчерашней картине.
Наконец, многие процессы «склеиваются» людьми и Excel: правила, исключения и согласования живут вне системы. Это плохо масштабируется и усложняет контроль.
Операционная система принятия решений (operational decision system) — это не «ещё одна витрина с графиками». Это связка данных + логики + процессов + контроля исполнения, которая помогает бизнесу не только понять, что происходит, но и сделать следующий шаг — согласованно, измеримо и повторяемо.
Данные: единая, актуальная картина по заказам, запасам, производству, клиентам, рискам — с понятными определениями и качеством.
Логика решений: правила, ограничения, оптимизационные расчёты, прогнозы, пороги алертов. Важно, что логика живёт рядом с данными и версионируется, а не прячется в Excel у отдельных команд.
Процессы: кто принимает решение, в какие сроки, какие шаги нужны дальше (согласование, создание заявки, изменение плана, назначение исполнителя).
Контроль выполнения: аудит действий, статусы, SLA, причины отклонений, измерение эффекта.
Ключевая идея — замкнуть цикл. Система не заканчивается на инсайте: она фиксирует, какое решение было предложено или принято, что реально сделали, какой получился результат, и использует это как обратную связь для улучшения правил и моделей.
BI обычно отвечает на вопросы «что и почему произошло?» через отчётность и дашборды. Операционная система решений отвечает на «что делать дальше и кто это сделает», управляя выполнением и снижая разрыв между аналитикой и операционной реальностью.
Это могут быть рекомендованные действия, приоритизация очереди (например, какие заказы отгружать первыми), перепланирование, алерты по отклонениям, задания для команд и автоматические изменения в рабочих системах — с прозрачной логикой и ответственностью.
Традиционный BI обычно строится «снизу вверх»: источники → ETL/ELT → хранилище → витрины/кубы → дашборды. Это хорошо работает, когда бизнес-вопросы стабильны и укладываются в заранее заданные разрезы. Но как только появляются сквозные процессы (например, «заказ → склад → доставка → возврат»), витрин становится много, они дублируют логику, а изменение одного шага тянет пересборку цепочки.
Если разложить архитектуру по слоям, различия становятся практичными:
В операциях важно, чтобы разные команды принимали решения на одной интерпретации фактов: одинаковые статусы, единые определения SLA, согласованные идентификаторы. Онтология снижает количество «локальных истин» в витринах и позволяет быстрее запускать новые сценарии без постоянной пересборки кубов и отчётов: вы расширяете модель и переиспользуете её в новых процессах, а не создаёте очередную витрину «под задачу».
Традиционный BI чаще строится вокруг периодического ETL: данные выгружаются по расписанию (ночью, раз в час), очищаются, складываются в витрины — и уже потом попадают в отчёты и дашборды. Это удобно для ретроспективы: «как мы сработали за неделю/месяц». Но в операционных задачах цена задержки быстро становится высокой.
Батчи работают, если решения не требуют мгновенной реакции: квартальная отчётность, контроль KPI, анализ отклонений. Слабое место — «окно слепоты» между обновлениями. В этот период система может показывать красивую картинку, но не текущую ситуацию: товар уже закончился, рейс уже сорван, оборудование уже в простое.
В операционных системах принятия решений важны:
Когда система не просто показывает метрику, а запускает действие (перераспределить запасы, сменить маршрут, открыть заявку), критично понимать происхождение цифр: откуда пришло значение, какой трансформацией получено, кто изменял правила. Прослеживаемость и контроль качества уменьшают риск «решений по ошибочным данным».
Запасы — ранний сигнал о дефиците и автоматическое пополнение; логистика — пересчёт ETA и переназначение рейсов при задержках; обслуживание — выявление аномалий и приоритизация заявок; риски — обновление лимитов/флагов при новых событиях. Здесь «почти реальное время» — не роскошь, а условие управляемости.
Когда BI используется как «витрина отчётности», цена ошибки часто ограничивается неверной интерпретацией показателя. В операционной системе принятия решений ошибка может превратиться в действие: поменять цену, остановить отгрузку, запустить закупку. Поэтому здесь важнее не только «кто видит», но и «кто меняет и кто утверждает» — с понятной историей изменений.
Lineage (происхождение) отвечает на вопрос: откуда взялась цифра в конкретном решении и через какие трансформации прошла.
В традиционном BI lineage нередко заканчивается на уровне ETL и витрины: можно найти источник поля, но сложнее восстановить цепочку «источник → расчёты → фильтры → итоговый KPI» в контексте конкретного пользователя и версии данных.
В Foundry‑подобном подходе lineage обычно строится сквозным: для любого набора данных, отчёта, правила или модели можно увидеть входные источники, шаги обработки, параметры, владельцев и дату изменения.
Для действий критично версионирование: решение должно быть воспроизводимым.
В BI отчёт можно пересчитать «по новой логике» — это неприятно, но терпимо. В операционном контуре нужно уметь доказать, почему вы сделали именно так: для внутреннего контроля, регуляторики и разборов инцидентов.
Важно разделять роли:
Типовые артефакты, которые делают доверие «осязаемым»: политики доступа (RBAC/ABAC), журналы аудита действий пользователей и сервисов, проверки качества данных (валидаторы, пороги, алерты), реестр наборов данных и владельцев, процедуры публикации и отката версий.
Традиционный BI часто заканчивается на «посмотрели дашборд, обсудили на планёрке, решили вручную». Это полезно для контроля, но плохо масштабируется: решения зависят от людей, теряются в переписках, не имеют SLA, а эффект сложно измерить.
Операционная система принятия решений (в духе Foundry‑подхода) делает следующий шаг: аналитика не просто показывает картинку, а запускает управляемый процесс — с назначением ответственных, сроками, правилами согласования и фиксацией результата.
Ключевая разница — в оркестрации. Система может:
Отдельная практичная деталь: чтобы перейти от «идеи в отчёте» к реальному рабочему месту (очереди задач, карточки кейсов, формы согласований), часто нужно быстро собирать небольшие внутренние приложения. Для этого команды нередко используют платформы вроде TakProsto.AI: через чат можно собрать веб‑интерфейс и серверную часть (React + Go + PostgreSQL), добавить роли, статусы, аудит, а затем итеративно доработать процесс в «planning mode» со снапшотами и откатом. Такой путь особенно удобен, когда важно быстро проверить гипотезу операционного контура и при необходимости выгрузить исходники в свой контур.
Типовой цикл выглядит так:
В итоге вместо «инсайтов в отчёте» появляется воспроизводимый производственный процесс, где аналитика — часть операционного контура, а не отдельная витрина наблюдения.
Многие BI‑инструменты отлично отвечают на вопрос «что произошло?» — и частично «почему?». Но когда бизнесу нужно решить «что делать дальше прямо сейчас», на первый план выходят модели и оптимизация, встроенные в операционный контур. В Palantir Foundry (и в целом в классе операционных систем решений) ценность моделей определяется не точностью в ноутбуке, а тем, как они превращаются в повторяемое действие в процессе.
Описательная: показатели, дашборды, отчётность.
Диагностическая: разбор причин (срезы, корреляции, сегменты).
Предиктивная: прогноз спроса, риска, сроков, отказов.
Предписывающая: рекомендация действия — что заказать, кому позвонить, какой лимит поставить, какую смену усилить.
Традиционный BI обычно силён в первых двух пунктах. Предиктив и предписание часто остаются «витриной идей»: модель посчитали, график показали — а дальше решение принимают вручную.
Если прогноз не встроен в рабочий поток, он превращается в консультацию «на стороне». Операционная система решений связывает: данные → расчёт → рекомендацию → исполнение → обратную связь. Тогда модель перестаёт быть отчётом и становится механизмом управления: например, создаёт задачу, меняет приоритет, запускает проверку или предлагает вариант плана.
Чтобы модели работали стабильно, важны управленческие критерии:
Во многих сценариях лучше работают правила и ограничения: понятные пороги, приоритеты, логика «если‑то», согласованная с бизнесом. Их легче объяснить, проще поддерживать и быстрее внедрять.
Оптимальный подход — начинать с правил, затем добавлять прогнозы там, где они дают измеримый эффект, и только потом переходить к оптимизации и рекомендациям, когда процесс уже готов принимать решения автоматически или полуавтоматически.
Дашборды и отчётность хорошо отвечают на вопрос «что произошло». Но во многих операционных процессах важнее «что сделать прямо сейчас» — и чтобы решение сразу превращалось в действие в системе. Ниже — типовые случаи, где традиционный BI часто не закрывает цикл полностью.
Входные данные: продажи по каналам, остатки по складам и магазинам, сроки поставок, ограничения по логистике, промо‑календарь.
Решение: сколько и куда пополнять, какие позиции ускорять/замораживать.
Действие: автоматическое создание заявок/перемещений, уведомления закупке, пересчёт целевых уровней запасов.
Метрика эффекта: снижение out‑of‑stock, оборачиваемость, сокращение списаний.
Скорость и качество: реакция — часы, данные должны быть согласованы по номенклатуре и единицам измерения.
Входные данные: GPS/телематика, статусы заказов, загрузка персонала, SLA, погодные условия.
Решение: приоритизация заявок, маршрут и назначение исполнителя.
Действие: переназначение задач, пересбор маршрута, отправка клиенту ETA.
Метрика эффекта: соблюдение SLA, стоимость на заказ, время простоя.
Скорость и качество: реакция — минуты, критична актуальность статусов и единый справочник адресов.
Входные данные: транзакции, логи систем, изменения справочников, права доступа.
Решение: что является отклонением, какой риск и приоритет проверки.
Действие: блокировка операции, запуск расследования, запрос подтверждений.
Метрика эффекта: предотвращённый ущерб, доля ложных срабатываний, время до реакции.
Скорость и качество: реакция — от секунд до часов, важны полнота и происхождение данных.
Входные данные: заказы, доступность оборудования, графики персонала, качество сырья, техкарты.
Решение: оптимальный план выпуска и переналадок с учётом ограничений.
Действие: выпуск сменных заданий, резервирование материалов, пересчёт плана при сбое.
Метрика эффекта: OEE, выполнение плана, снижение переналадок.
Скорость и качество: реакция — часы, нужны единые версии нормативов и статусов оборудования.
Входные данные: контрагенты, платежи, лимиты, результаты проверок, регламентные правила.
Решение: можно ли проводить операцию, какие проверки обязательны.
Действие: стоп/разрешение, маршрутизация на согласование, аудитный след.
Метрика эффекта: число нарушений, время согласования, качество аудита.
Скорость и качество: реакция — минуты/часы, требуется строгая управляемость данных и доступов.
Выбор упирается не в «круче/моднее», а в характер решений, которые бизнес принимает на данных. Начните с простых вопросов‑критериев — они быстро проясняют картину.
BI обычно достаточно, если основной запрос — отчётность и мониторинг KPI: регулярные дашборды, сверка план‑факт, анализ отклонений, редкие управленческие решения. Процессы простые, данные обновляются по расписанию, а действия выполняются вручную — и это приемлемо.
Операционная система становится оправданной, когда решений много и они взаимосвязаны: десятки/сотни решений в день, разные команды работают в одном процессе, требуется единая модель данных и контроль того, «кто, когда и почему» изменил параметры. Особенно важно, если нужно быстро пересчитывать планы при изменениях (спрос, поставки, ограничения мощностей) и сразу оркестрировать действия.
| Низкая скорость требований | Высокая скорость требований | |
|---|---|---|
| Низкая сложность процесса | BI | BI + точечная автоматизация |
| Высокая сложность процесса | BI + регламенты/согласования | Операционная система решений |
Если вы регулярно оказываетесь в правом нижнем квадранте, «дашбордов мало»: нужна система, которая связывает данные, правила/модели и выполнение действий в одном контуре.
Переход от «посмотрели дашборд» к системе, которая помогает принимать решения в процессе, лучше делать поэтапно. Цель — быстро доказать ценность, а затем закрепить её в операционной модели.
Пилот выбирают там, где эффект измерим и есть понятный владелец процесса (например, планирование запасов, приоритизация заявок, контроль простоев). На пилоте важно собрать не «всё и сразу», а минимально достаточный контур:
Добавляют соседние участки процесса, подключают дополнительные источники, формализуют правила и рекомендации, выстраивают регулярные релизы. Здесь обычно впервые появляется необходимость в стандартах качества данных и управлении изменениями.
Фиксируют SLA на данные и решения, вводят мониторинг качества, аудит, управление доступами, регламенты поддержки и обучение новых пользователей.
Частые проблемы: «грязные» справочники, сопротивление изменениям, отсутствие владельца процесса.
Снижают риски через единые определения показателей, контроль качества (правила, алерты, ответственные) и обучение пользователей с привязкой к реальным задачам — не к интерфейсу, а к решениям, которые теперь принимаются быстрее и одинаково по всей организации.
Сравнивать Foundry и традиционный BI по цене лицензии — почти всегда ошибка. Бизнес‑эффект здесь возникает не от «красивых графиков», а от того, что решения принимаются быстрее, единообразно и с контролем качества данных.
Выбирайте метрики, которые напрямую связаны с деньгами и операционными рисками:
Важно заранее зафиксировать базовую линию («как было») и определить, кто владелец метрики — тогда ROI считается не «в целом по компании», а по конкретным процессам.
Чтобы не приписать платформе чужой результат, используйте простые практики: контрольные группы/филиалы, сравнение «до/после» на одинаковых периодах, учёт крупных изменений (новые тарифы, смена поставщика, кампании) отдельными факторами. В идеале — запускать пилот на ограниченном контуре и масштабировать только после подтверждения эффекта.
В BI основной объём затрат — сопровождение витрин и отчётов (изменения в источниках, правки формул, согласование версий). В Foundry значимая часть TCO уходит на сопровождение процессов и моделей: мониторинг качества данных, обновление правил, контроль дрейфа, поддержка оркестрации.
Соберите минимальный набор, без которого цифры будут спорными: каталог данных, регламенты (доступы, ответственность, сроки обновления), мониторинг качества (полнота, свежесть, аномалии) и журнал изменений. Это превращает «экономику проекта» в управляемую систему, а не в разовый расчёт.
Традиционный BI и Palantir Foundry решают разные задачи, поэтому «кто лучше» зависит не от красоты дашбордов, а от того, что именно нужно бизнесу: просто видеть картину или системно влиять на неё.
Цель. BI в первую очередь отвечает на вопрос «что произошло и где отклонение», а операционная система принятия решений — «что делать дальше и как это выполнить в процессе».
Архитектура. В BI часто доминируют витрины/кубы под отчётность. В Foundry акцент на сквозной модели данных, которая может одновременно обслуживать аналитику, правила, прогнозы и операционные приложения.
Процесс. BI обычно заканчивается просмотром отчёта. Операционная система встраивает аналитику в рабочий контур: назначение задач, маршрутизация, согласования, контроль исполнения.
Контроль и доверие. Для решений критичны происхождение данных, аудит, роли и воспроизводимость расчётов — чтобы спор был не «чьим цифрам верить», а «какое действие оптимально».
Эффект. BI измеряют качеством отчётности и скоростью подготовки. Систему решений — сокращением цикла «сигнал → действие», снижением потерь, ростом выручки/маржи, соблюдением SLA.
Выберите 1–2 процесса, где «дашбордов мало» и есть измеримые метрики: например, управление запасами, планирование производства, логистика, обработка обращений, контроль качества. Зафиксируйте базовую линию и целевые показатели (время реакции, доля просрочек, стоимость ошибки, уровень сервиса).
Назначьте владельца процесса (кто отвечает за результат) и владельца данных (кто отвечает за определения, качество и доступы). Без этих ролей любая платформа превращается в набор разрозненных инициатив.
Если вы хотите обсудить, какой сценарий лучше подходит под Foundry, а где достаточно BI, логичный формат — короткая диагностика и демонстрация на одном выбранном процессе, с заранее согласованными метриками и границами пилота. При этом прототип операционного «рабочего места» (задачи, согласования, статусы, аудит) можно собрать быстрее, чем в классической разработке: например, в TakProsto.AI — через чат, с развёртыванием и хостингом на серверах в России и возможностью экспорта исходного кода для дальнейшей поддержки в вашем контуре.
Традиционный BI в основном отвечает на вопросы «что произошло?» и «почему так вышло?» через витрины данных, метрики и дашборды.
Подход класса Foundry (операционная система принятия решений) закрывает следующий шаг: «что делать дальше, кто делает, по каким правилам и в какие сроки», связывая данные, логику решений и исполнение в одном контуре.
BI обычно достаточно, если:
Если вам нужно управлять операциями «здесь и сейчас» (много решений в день, есть SLA и цена ошибки высока), одного BI чаще не хватает.
Это связка:
Главная ценность — замкнутый цикл «данные → решение → действие → результат → улучшение правил/моделей».
Потому что «красивый, но вчерашний» дашборд может провоцировать неверные действия. Для операционных сценариев важны:
Практический шаг: определите для каждого решения допустимую задержку данных и от нее проектируйте интеграции.
Витрины часто дублируют логику «под конкретный отчет», и при сквозных процессах это множит расхождения.
Единая семантическая модель/онтология полезна, когда нужно, чтобы разные команды работали с одинаковыми определениями статусов, SLA, идентификаторов и правил. Тогда вы расширяете модель и переиспользуете ее в новых сценариях, а не создаете очередную витрину.
Lineage (происхождение) помогает ответить: откуда взялась цифра в конкретном решении и через какие шаги обработки прошла.
В операционном контуре это нужно, чтобы:
Минимум на старте: журнал изменений, владельцы наборов данных и прозрачные правила публикации/отката.
В операционных системах важно разделять:
Практичный набор контроля: RBAC/ABAC, аудит действий пользователей и сервисов, версионирование правил/моделей, процедуры публикации и отката, плюс проверки качества данных (полнота/свежесть/аномалии) с ответственными.
BI часто заканчивается на «увидели проблему → обсудили → сделали вручную». Это плохо масштабируется и сложно измерять.
Операционный подход строит цепочку:
Так появляется управляемый процесс вместо переписок и выгрузок.
Не всегда. Во многих кейсах лучше стартовать с простых правил и ограничений:
Далее добавляйте прогнозы там, где они дают измеримый эффект, и только после этого переходите к оптимизации. Обязательно задайте частоту пересчета, мониторинг дрейфа и владельца модели.
Не сравнивайте только цену лицензии: эффект часто появляется из сокращения цикла «сигнал → действие».
Полезные метрики для ROI:
Чтобы отделить эффект от сезонности, используйте «до/после» на сопоставимых периодах и по возможности контрольные группы. Для честного расчета заранее зафиксируйте базовую линию и владельца метрики.