Разбираем, чем подход Palantir отличается от традиционного enterprise‑ПО: интеграция данных, оперативная аналитика, управление изменениями и варианты развертывания.
В этой статье сравниваются два разных подхода к корпоративному ПО: платформенный подход Palantir и классические enterprise‑приложения (ERP/CRM/SCM, хранилища данных, BI‑системы и интеграционные инструменты). Речь не о том, «кто лучше», а о том, как по‑разному решаются одни и те же бизнес‑задачи — от сведения данных до принятия решений прямо в операционных процессах.
Материал помогает ответить на практические вопросы:
Статья рассчитана на руководителей и владельцев процессов (операции, производство, логистика), аналитиков, ИТ‑руководителей и архитекторов — всех, кто отвечает за то, чтобы данные превращались в управляемые решения, а не в бесконечные витрины и разрозненные дашборды.
Ни Palantir, ни «классика» не создают ценность сами по себе. Результат упирается в три вещи: качество и доступность данных, понятные процессы и контроль доступа (кто и что может видеть/менять, с каким аудитом).
Отдельно важно: скорость перехода «идея → рабочий инструмент» часто определяется не только платформой данных, но и тем, как быстро команда делает прикладные интерфейсы и workflow. Здесь может помочь подход vibe‑coding: например, в TakProsto.AI внутренние веб/серверные/мобильные приложения можно собрать из диалога, а затем экспортировать исходники и встроить в контур предприятия — это снижает порог для быстрого прототипирования операционных сценариев поверх существующих данных.
Под «традиционным enterprise‑софтом» обычно понимают набор крупных систем, каждая из которых закрывает свой класс задач. Это транзакционные платформы (ERP, CRM, SCM), хранилища и отчётность (DWH/BI), интеграционные прослойки (ETL/ESB), мастер‑данные (MDM), а также специализированные отраслевые решения и «самописные» сервисы вокруг них.
Во многих компаниях схема выглядит примерно так: внизу — операционные приложения, где фиксируются события (заказ, отгрузка, платёж, обращение в поддержку, производственная операция). Дальше — интеграции, которые переносят и преобразуют данные между системами. Выше — витрины данных и отчёты: агрегаты, дашборды, регламентные формы для руководства и подразделений.
В такой модели данные «путешествуют» по цепочке: источник → выгрузка → трансформация → загрузка → витрина → отчёт. Каждый шаг добавляет полезную обработку, но одновременно увеличивает задержку и число мест, где могут появиться разночтения.
Главная сложность проявляется не в первом запуске, а в изменениях. Новая бизнес‑логика (например, по‑новому считать маржинальность, иначе классифицировать клиента, добавить атрибуты к партии товара) требует правок сразу в нескольких слоях: в источнике, в ETL‑процессах, в модели DWH, в витринах и в отчётах.
Отсюда появляются типовые симптомы:
При всех ограничениях традиционный стек силён там, где нужны стандартизированные транзакции и регламентные процессы: бухгалтерский контур, закупки, склад, расчёты с клиентами, управление договорами. ERP/CRM хорошо поддерживают единые справочники, контроль полномочий и типовые сценарии.
Именно поэтому во многих компаниях «классический» подход остаётся базой: он обеспечивает стабильность, предсказуемость и соответствие процедурам — даже если аналитика и изменения сверху движутся медленнее, чем хотелось бы бизнесу.
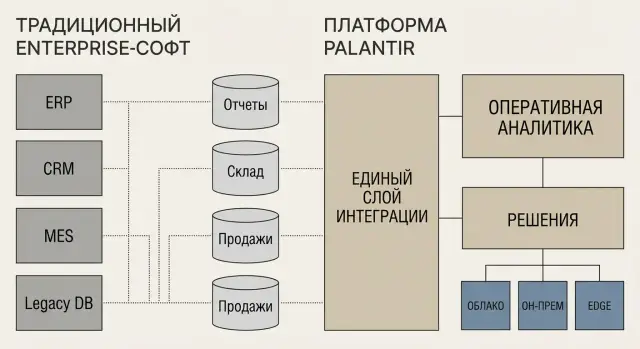
Под «подходом Palantir» обычно имеют в виду не очередное корпоративное приложение (CRM/ERP/BI), а платформенный слой, который «ложится» поверх существующих источников данных и рабочих процессов. Идея в том, чтобы не заменять все системы разом, а связать их и сделать данные и операции управляемыми в единой логике.
Если классический enterprise‑софт часто решает одну функциональную область (финансы, склад, продажи) и хранит данные внутри себя, то платформенный подход начинается с вопроса: как собрать и согласовать данные из десятков систем так, чтобы ими могли пользоваться разные команды — аналитики, операционщики, безопасность — без постоянных «ручных» выгрузок.
В упрощённом виде подход раскладывается на несколько слоёв:
В качестве примеров платформ обычно упоминают Foundry (работа с данными и операциями), Gotham (аналитика для расследований и сложных кейсов), Apollo (управление развертыванием и обновлениями). Важно не название, а принцип: единый слой управления данными, моделями и доставкой изменений.
Ценность такого подхода сильнее проявляется там, где много разрозненных систем и сложные операции: производство, логистика, крупные проекты, безопасность, критическая инфраструктура. Там платформа помогает сделать данные не «побочным продуктом», а частью управления процессом.
В классическом enterprise‑софте интеграция часто начинается с «подключим ещё одну систему». Появляются коннекторы, выгрузки, промежуточные таблицы и цепочки ETL/ELT — и постепенно вырастает сеть point‑to‑point связей. Она работает, пока изменений мало. Но как только меняются источники, требования к отчётам или правила расчётов, стоимость поддержки растёт: нужно править десятки пайплайнов и согласовывать, где «истина».
Под «подходом Palantir» обычно подразумевают движение к единому интеграционному слою, где данные не просто собираются, а приводятся к общей модели с понятной семантикой. Это не отменяет коннекторы — наоборот, они остаются входными воротами — но основной эффект достигается на уровне общего представления данных и прозрачных преобразований.
В традиционных стэках разные типы данных нередко живут в разных «коробках»: таблицы — в хранилище, события — в стриминге, файлы — в файловом хранилище, геоданные — в GIS, журналы — в лог‑платформе. Дальше их «склеивают» под конкретный кейс.
Единый слой стремится делать наоборот: поддерживать таблицы, события/стриминг, файлы, геоданные и логи в единой системе связей, чтобы один и тот же объект (например, партия продукции или рейс) мог обогащаться данными из разных источников без ручных «швов» между командами и инструментами.
Ключевое отличие — единые определения: справочники, сущности, связи и бизнес‑правила фиксируются как часть модели. «Клиент», «заказ», «единица оборудования», «простой» получают согласованное описание, а не десяток трактовок в разных отчётах.
Когда преобразования данных и бизнес‑правила видны и версионируются, обсуждение смещается с «почему цифры не сходятся» на «какое правило верное и кто его владелец». Совместные модели (ИТ + бизнес) помогают быстрее менять логику расчётов и снижают риск скрытых преобразований в скриптах и витринах, которые понимает только один человек в команде.
Классический BI (business intelligence) чаще отвечает на вопрос «что произошло?» — через отчёты, дашборды и регламентные выгрузки. Это полезно для контроля и план‑факт анализа, но редко меняет ход процесса прямо сейчас.
Оперативная аналитика устроена иначе: она встраивается в поток работы и помогает отвечать «что делать дальше?» в моменте. Вместо того чтобы ждать еженедельный отчёт, команда получает подсказку, правило или алерт, а затем — конкретный следующий шаг в workflow.
Оперативная аналитика нужна там, где цена задержки высока: срывы поставок, простой оборудования, риск комплаенса, инциденты безопасности, дефицит ресурсов.
Чтобы это работало, обычно требуются:
Оценивать успех лучше прикладными метриками процесса: сокращение времени цикла (от события до решения), рост точности планов, снижение простоев, уменьшение ручных операций (склейки в таблицах, пересылок, сверок). Если аналитика не приводит к заметному изменению этих показателей, она остаётся «красивой отчётностью», а не инструментом управления.
Если классическое enterprise‑ПО часто строит данные «под отчёт» (таблицы, витрины, KPI), то операционный подход делает данные частью ежедневного процесса: кто-то отвечает за сущность, правила прозрачны, а изменения управляются как продукт.
Операционная модель отвечает на практичные вопросы: кто владеет справочником контрагентов, что считается «активным заказом», как быстро обновляются статусы, что делать при конфликте источников.
В платформенном подходе (в т.ч. у Palantir‑подобных решений) это обычно фиксируется через:
Важно, что правила не «живут в головах» аналитиков и не расползаются по таблицам/скриптам — они становятся частью операционной модели.
Для операций качество данных — не абстракция. Нужны автоматические проверки: диапазоны, уникальность ключей, согласованность статусов, полнота обязательных полей.
Хорошая практика — сочетать профилирование (понимание распределений и аномалий) и валидации на входе/выходе: данные помечаются, блокируются или отправляются на разбор до того, как попадут в расчёты и процессы.
Чтобы решения можно было объяснить и повторить, нужен единый каталог: что это за показатель, из каких источников он собран и какой формулой рассчитан.
Lineage (происхождение) помогает ответить на вопросы «почему цифра изменилась?» и «какая таблица/правило сломало процесс?». А воспроизводимость означает, что расчёт можно повторить на том же наборе данных и получить тот же результат — критично для аудита и расследований.
Хаос начинается, когда одна и та же сущность называется по‑разному, а версии правил не различимы. Работают простые принципы:
В итоге модель данных перестаёт быть побочным артефактом интеграции и становится управляемым активом, на который можно опираться в реальных операциях.
Безопасность в «классическом» enterprise‑ПО часто строится вокруг приложений: у каждой системы свои роли, свои настройки доступа и свои журналы. Это работает, пока данных немного и границы понятны. Но когда один бизнес‑процесс «цепляет» десяток источников, появляются дыры: права разъезжаются, аудит собирается по частям, а принцип наименьших привилегий становится трудновыполнимым.
В традиционном подходе обычно доминирует RBAC (Role‑Based Access Control): роль «аналитик» или «оператор» получает набор прав внутри конкретного продукта. «Подход Palantir» чаще описывают как более гибкий слой политик поверх данных и действий, где к ролям добавляется ABAC (Attribute‑Based Access Control): доступ может зависеть от атрибутов пользователя, объекта и контекста (подразделение, регион, тип данных, уровень допуска, смена и т. п.).
На практике это упрощает реализацию принципа наименьших привилегий и сегментацию: можно ограничить не только «куда можно зайти», но и «какие именно данные и операции допустимы».
Классический BI и хранилища тоже поддерживают RLS/CLS (ограничения по строкам и колонкам), но эти правила нередко живут отдельно от прикладных интерфейсов. В платформенном подходе политики чаще связываются с единым слоем данных и применяются одинаково в аналитике и в операционных сценариях.
Дополнительно важны маскирование и псевдонимизация (например, скрыть часть номера документа), а также детальный аудит: кто открыл набор данных, какие фильтры применил, что экспортировал, какие изменения внёс.
Для безопасной совместной работы команд критична изоляция dev/test/prod и управляемые промо‑процедуры: кто может выкатывать изменения, как проходят согласования, как откатиться. Регуляторам обычно нужно заранее подготовить: политики доступа, матрицу ролей/атрибутов, журналы действий и администрирования, отчётность по инцидентам, процедуры управления изменениями и регулярный пересмотр прав.
Корпоративная «классика» исторически тяготеет к он‑прем: серверы в своём дата‑центре, редкие большие релизы, длинные окна обслуживания и зависимость от внутренних команд инфраструктуры. «Подход Palantir» чаще строится вокруг гибридности: часть компонентов может жить в облаке, часть — на площадке заказчика, а вычисления — ближе к источникам данных.
Облако удобно, когда важны скорость запуска, эластичность вычислений и частые обновления. Это хороший вариант для аналитических сценариев, где данные уже находятся в облачных хранилищах или их можно безопасно передавать.
Он‑прем выбирают, если данные нельзя выносить из периметра (регуляторика, коммерческая тайна), если есть строгие требования к изоляции или если интеграции завязаны на внутренние системы, которые сложно «вынести наружу».
Edge (на заводе, в порту, на объекте с нестабильной связью) нужен, когда важны задержки и автономность: решения должны работать даже без постоянного доступа к интернету. Здесь часто обрабатывают телеметрию, события оборудования и оперативные показатели прямо «на месте», а в центр отправляют агрегированные результаты.
Вместо редких «монолитных» релизов всё чаще разворачивают аналитические «приложения» и модели как отдельные артефакты: с понятными версиями, окружениями (dev/test/prod), проверками перед выпуском и возможностью выпускать обновления чаще, но меньшими порциями. Это снижает риск: обновили один сценарий — не затронули остальные.
На практике ценность дают не только варианты размещения, но и то, как система живёт после запуска: мониторинг качества данных и выполнения задач, журналирование и аудит, быстрые откаты при проблемах, а также разделение ролей (кто меняет логику, кто утверждает, кто выпускает в прод). Такой контур помогает масштабироваться от пилота к стабильной эксплуатации без хаоса в изменениях.
Пилоты в enterprise часто «не взлетают» не потому, что идея плохая, а потому что пилот делают как одноразовый проект. Быстро подключили пару источников, собрали витрину, показали дашборд — и упёрлись в реальность: новые интеграции требуют согласований, данные «по‑разному называются» в системах, права доступа настраиваются вручную, а владение результатом остаётся размытым.
Главные стоп‑факторы обычно три:
Когда это не решено, «пилот» превращается в витрину, а не в продукт, который живёт и улучшается.
Масштабирование становится возможным, когда команда начинает мыслить повторным использованием:
Для роста от пилота к продукту нужны устойчивые роли: ИТ обеспечивает инфраструктуру и интеграции; аналитики и инженеры данных формализуют модели; владельцы процессов задают цели и принимают результат; безопасность и комплаенс утверждают доступы и аудит; data owners отвечают за качество и определения.
Выбор 1–2 приоритетных кейсов с измеримым эффектом и понятными владельцами.
Инвентаризация данных и доступов: источники, ограничения, критичность, SLA.
Сборка минимального продукта: не «красивый отчёт», а рабочий контур принятия решений.
Стандартизация: модели, права, аудит, шаблоны интеграций, документация.
Промышленный релиз: мониторинг качества данных, поддержка, обучение пользователей.
Тиражирование на соседние процессы и подразделения за счёт повторного использования, а не переписывания.
Практический нюанс: на шагах 3–4 часто всплывает потребность быстро собирать «тонкие» операционные приложения (формы, статусы, согласования, журналы решений) для пользователей на местах. В таких случаях TakProsto.AI может закрывать именно прикладной слой: создать веб‑интерфейс на React, серверную часть на Go с PostgreSQL и при необходимости мобильный клиент на Flutter — без долгого цикла классического программирования, с экспортом исходников и возможностью развернуть в российском контуре.
Так пилот перестаёт быть демонстрацией и становится платформенным продуктом, который можно расширять предсказуемо по срокам и рискам.
Стоимость enterprise‑решений редко равна «цене лицензии». На практике бизнес платит за скорость изменений, устойчивость процессов и способность команды поддерживать систему годами.
У «классического» стека бюджет часто распадается на несколько строк: лицензии BI/ETL/ESB, отдельные базы и витрины, оркестрация, средства качества данных, мониторинг, MDM, а также серверы/облако, резервное копирование и отказоустойчивость. Плюс — услуги интегратора и внутренняя команда (аналитики, инженеры данных, администраторы).
У платформенного подхода типа Palantir часть этих компонентов закрывается единым продуктом и едиными практиками управления данными и доступами. Тогда инфраструктурные и лицензионные расходы могут выглядеть проще, но критично понимать, что именно входит в контракт: объёмы данных, число пользователей, среда развертывания, требования к изоляции и аудит.
Самые дорогие статьи часто не в счетах, а во времени людей и потерях от ошибок:
Чем больше таких швов, тем дороже любой новый кейс: добавили источник — переписали пайплайны, обновили витрины, перетестировали отчёты, пересобрали доступы.
Сравнение стоит вести не только по TCO (совокупная стоимость владения) и ROI, но и по экономике изменений:
Иногда платформа дороже на старте, но дешевле на горизонте 12–24 месяцев за счёт меньшего числа ручных операций и более быстрого вывода сценариев в прод.
Чтобы избежать сюрпризов, заранее уточните:
Что именно входит в цену: пользователи, среды (dev/test/prod), объёмы, коннекторы, аудит.
Кто и как поддерживает интеграции при изменениях источников.
Какие SLA по доступности, восстановлению, обновлениям и как они влияют на стоимость.
Как считается стоимость расширения: новый завод/филиал, новый домен данных, рост пользователей.
Как измеряется успех пилота: метрики времени на изменение, качества данных и эффекта для бизнеса.
Такой список переводит разговор из «сколько стоит лицензия» в «сколько стоит результат и скорость изменений».
Выбор между платформенным подходом и «классическими» enterprise‑системами обычно упирается не в бренд, а в характер вашей работы с данными и скорость изменений в операциях. Ниже — практичные критерии, которые помогают принять решение без лишней теории.
Платформа уровня Palantir (как способ организации единого слоя данных + инструментов для операционных сценариев) чаще всего выигрывает, если одновременно выполняются несколько условий:
Классический стек (ERP/CRM + DWH + BI + ETL/ESB) часто рациональнее, если:
Данные: какие сущности нужно связать (заказ—партия—станок—смена—поставщик)? Нужна ли трассируемость «почему система предложила это решение»?
Безопасность и аудит: требуется ли детальный контроль доступа на уровне объектов/атрибутов и полная история действий пользователей?
Развертывание: обязателен ли он‑прем, edge, изолированные контуры, или допустимо облако?
Интеграции: сколько систем, как часто они меняются, есть ли ограничения на доступ к ним?
Навыки команды: кто будет владеть моделью данных и сценариями — ИТ, аналитики, операционные роли? Как устроите поддержку 24/7 для критичных процессов?
Чтобы PoC был честным, приносите не «идеальные» данные, а реальные:
Если по итогам вы видите, что ценность появляется только при объединении многих источников и быстром изменении логики — это сигнал в сторону платформенного подхода. Если эффект достигается простыми витринами и отчётами — «классика» может быть быстрее и дешевле.
А если узкое место — не столько данные, сколько скорость сборки прикладных инструментов для процесса (workflow, согласования, операционные панели), имеет смысл параллельно оценить TakProsto.AI: платформа позволяет быстро собрать такие приложения через чат, поддерживает деплой/хостинг, снапшоты и откат, а также работает в российском контуре с локализованными и opensource‑моделями без передачи данных за рубеж.
Если у вас десятки разрозненных систем и нужно быстро связывать данные между доменами (заказ—партия—поставка—оборудование), платформенный подход обычно даёт выигрыш за счёт единого логического слоя и семантики.
Если задачи в основном про регламентные транзакции и периодическую отчётность (финансы, закрытие месяца), «классический» стек (ERP/CRM + DWH + BI + ETL) часто проще и дешевле.
В «классике» данные часто проходят цепочку источник → ETL/ELT → DWH → витрина → BI. Это хорошо работает, но изменения затрагивают много слоёв.
В платформенном подходе акцент на едином логическом представлении данных (data fabric) и согласованных моделях: коннекторы остаются, но «истина» и правила фиксируются на уровне общей семантики, а не в десятках разрозненных витрин.
Классический BI чаще отвечает на вопрос «что произошло?» через отчёты и дашборды, обычно с задержкой (например, раз в сутки).
Оперативная аналитика встроена в процесс и помогает решать «что делать дальше?» в моменте. Обычно нужны:
Семантика — это согласованные определения сущностей и показателей: что такое «активный клиент», «простой», «маржинальность», какие связи между объектами и какие бизнес-правила применяются.
Практический эффект: меньше споров «почему цифры не сходятся», легче вносить изменения и проще масштабировать решения на разные подразделения без дублирования логики.
Типовой риск — пилот делают как одноразовую витрину: подключили пару источников, собрали дашборд, но не оформили модели, права, владение и процесс изменений.
Чтобы пилот масштабировался, заранее заложите:
Минимальный практичный набор:
В классическом подходе безопасность часто «привязана» к приложениям: роли и журналы отдельно в каждой системе. При сквозных процессах это усложняет единый аудит.
Практики, которые стоит требовать независимо от подхода:
Выбор зависит от ограничений и требований к задержкам:
Смотрите не только на лицензии и инфраструктуру, но и на экономику изменений:
В классическом стеке скрытые затраты часто возникают из-за множества пайплайнов, ручных сверок и дублирования логики в витринах/отчётах.
Чтобы PoC был честным и полезным:
Если ценность появляется только при объединении многих источников и частых изменениях правил — это сильный аргумент в пользу платформенного подхода.