Разбираем паттерны multi-tenant SaaS: изоляцию данных и ресурсов, масштабирование, миграции и то, как ИИ помогает генерировать и проверять архитектуры.
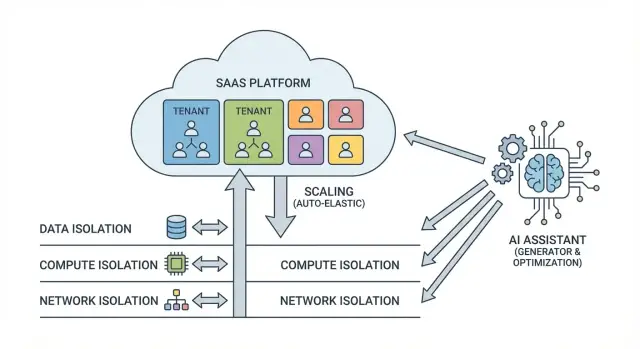
Multi-tenant SaaS (мультиарендный SaaS) — это модель, где один и тот же продукт и его инфраструктура обслуживают сразу много клиентов (арендаторов, tenants). У каждого арендатора — свои пользователи, настройки и данные, но приложение и операционная «кухня» общие.
Главная идея — экономия и управляемость за счёт стандартизации.
Во‑первых, снижение стоимости владения: вместо отдельных окружений на каждого клиента вы разделяете вычисления, хранение и поддержку. Это особенно заметно на ранних стадиях, когда важно не раздувать инфраструктуру.
Во‑вторых, быстрое масштабирование: добавление нового арендатора часто сводится к онбордингу и конфигурации, а не к развёртыванию нового «мини‑продукта».
В‑третьих, простое обновление: вы выкатываете новую версию один раз, а не обслуживаете множество разрозненных инсталляций. Это ускоряет выпуск функций и исправлений.
Утечки данных между арендаторами. Любая ошибка в запросах, кэшировании или логике авторизации может привести к тому, что один клиент увидит данные другого.
«Шумный сосед» (noisy neighbor). Один арендатор может нагрузить общие ресурсы и ухудшить качество сервиса для остальных.
Сложность миграций. Схемы данных и изменения функциональности нужно обновлять так, чтобы не нарушать работу разных сегментов клиентов и их конфигураций.
Практика обычно начинается с общей инфраструктуры и усиливает изоляцию по мере роста требований. Небольшим клиентам часто достаточно логической изоляции (например, через идентификатор арендатора в данных), а для крупных или регулируемых отраслей может потребоваться более жёсткое разделение — вплоть до отдельных баз данных или выделенных ресурсов.
Чтобы решение не было «на глаз», заранее зафиксируйте градации изоляции по тарифам и типам клиентов: базовая (shared) для большинства и усиленная (dedicated) для тех, кто платит за повышенный контроль.
Мультиарендность — это компромисс между экономией на общем инфраструктурном слое и ожиданиями клиентов по безопасности и предсказуемости сервиса. Удобно думать об изоляции как о трёх независимых «ручках»: данные, вычисления и сеть. Их можно усиливать по отдельности, не обязательно сразу «выделять всё каждому».
Логическая изоляция означает, что арендаторы делят один и тот же контур хранения, но доступ разделяется правилами: tenant_id в таблицах, ограничения на уровне запросов, политики доступа. Это дешевле и проще масштабировать, но требует дисциплины в разработке и проверок.
Физическая изоляция — когда у арендатора свой отдельный контур хранения (схема или база данных, иногда даже отдельный кластер). Это увеличивает стоимость и сложность операций (бэкапы, миграции, мониторинг), зато проще объяснить безопасность и ограничить «радиус поражения».
В общем пуле (общие сервисы, общие очереди, общие воркеры) легче утилизировать ресурсы, но выше риск noisy neighbor: один крупный клиент может «съесть» CPU/память/коннекты.
Выделенные воркеры или отдельные сервисы для части арендаторов дают предсказуемость по задержкам и SLA. Частый компромисс: общий API‑слой, но фоновые задачи и тяжёлые отчёты — в выделенных очередях/воркерах.
Сетевая изоляция добавляет барьеры поверх логики приложения: отдельные VPC/подсети, сегментация, правила east‑west трафика, отдельные endpoint’ы к хранилищам. Это помогает снизить риск бокового перемещения при инцидентах и лучше удовлетворяет требованиям аудиторов.
Чаще всего запрашивают: доказуемое разделение данных, управляемые ключи шифрования, минимизацию прав доступа, журналирование действий и возможность изолировать «критичных» арендаторов (хотя бы на уровне БД/вычислений). Важно заранее определить градации: базовый уровень для большинства и усиленный — для тех, кому нужна (и оплачивается) повышенная изоляция.
Этот вариант часто называют подходом «всё в одном»: у всех арендаторов одна и та же база данных и один общий набор таблиц, а принадлежность строк конкретному клиенту определяется полем tenant_id. По сути, вы строите один продукт и одно хранилище, но логически делите данные.
Подход хорошо подходит, если вы запускаете SaaS с нуля, хотите быстро выйти на рынок и ожидаете много небольших арендаторов с похожими сценариями и объёмами данных. Администрирование проще: одна схема, единые миграции, меньше вариативности.
Плюсы — простота и низкая стоимость владения: меньше баз, меньше операций, проще мониторинг и обновления.
Минусы — конкуренция за ресурсы и высокая цена ошибки. Один тяжёлый отчёт или неудачный запрос может замедлить работу для других (noisy neighbor). А неверное условие в запросе или баг в логике фильтрации может привести к утечке данных между арендаторами.
Ключевое правило: tenant_id должен присутствовать в индексах и ограничениях там, где это влияет на поиск и уникальность. Практический эффект:
UNIQUE (tenant_id, email) вместо глобального UNIQUE (email)).Также полезно договориться о стандарте в приложении: любые выборки из мультиарендных таблиц обязаны фильтроваться по tenant_id, а «исключения» оформляются явно и проходят отдельное ревью.
С одной базой сложнее «точечно» восстановить данные одного клиента. Поэтому заранее продумайте процедуры:
tenant_id (как часть поддержки и требований клиентов);Если вам важно быстрое восстановление отдельного арендатора по SLA, фиксируйте это требование заранее — позже может оказаться, что удобнее перейти на модель с отдельными схемами или базами.
Подход «одна база данных, отдельная схема (schema) на арендатора» выбирают, когда хочется балансировать между простотой управления инфраструктурой (одна БД) и более наглядной изоляцией на уровне структуры данных.
Схема на арендатора хорошо работает, если у клиентов есть отличия в наборе таблиц или темпах роста, но вы не готовы поднимать отдельную базу под каждого.
Практические плюсы:
Главная сложность — обновлять десятки/сотни схем синхронно.
Хорошая практика — делать миграции идемпотентными и раскатывать их поэтапно:
сначала изменения, совместимые со старой версией приложения (добавили колонку, но ещё не используем),
затем выкатываем код,
потом «чистим хвосты» (удаляем старое).
Также полезны «батчи» (миграция группами арендаторов) и отдельный сервис/джоб для миграций с повторными попытками и отчётностью по прогрессу.
Схема не является границей безопасности сама по себе: нужно строго настроить роли/права, запретить доступ «мимо приложения», аккуратно работать с search_path и подключениями.
Чем больше схем, тем выше операционная нагрузка: растёт время миграций, увеличивается число объектов для мониторинга, бэкапов и восстановления. Когда число арендаторов и частота релизов растут, схема на арендатора часто становится тяжёлой операционно — и тогда рассматривают tenant_id в общих таблицах или выделение отдельных баз для крупных клиентов.
Модель «отдельная база данных (БД) на арендатора» часто выбирают, когда цена ошибки высока: финансы, медицина, крупные B2B‑контракты, строгие требования к резидентности данных или аудитам. Вы получаете максимальную изоляцию: отдельные файлы данных, отдельные планы бэкапов/восстановления, проще доказать границы доступа и ограничить «соседей» по ресурсам.
Плюсы очевидны: проще выполнять запросы на удаление/экспорт данных конкретного клиента, точнее настраивать политики шифрования, легче делать «точечные» миграции.
Но за это платят эксплуатацией: больше объектов для мониторинга, больше бэкапов, больше секретов и ролей, выше риск упереться в лимиты СУБД и инфраструктуры (соединения, число инстансов/БД, IOPS).
Важно заранее посчитать не только стоимость хранения, но и стоимость «пустоты»: даже небольшая БД требует обслуживания, резервного копирования и регулярных проверок восстановления.
На практике выигрывает гибридный подход: малые и средние арендаторы живут в shared‑пуле, а крупным выдаётся dedicated‑БД. Это позволяет:
Заранее зафиксируйте бюджеты: максимальное число БД, допустимое количество одновременных соединений на пул, частоту бэкапов, RPO/RTO и стоимость восстановления. Проверьте, как меняется цена при росте числа арендаторов и при пиковых нагрузках. Полезно привязать лимиты к тарифам и описать их в /pricing.
Безболезненный «upgrade» — это управляемый процесс:
заморозка схемы и версий миграций (чтобы данные и приложение совпадали);
создание dedicated‑БД по шаблону, выдача ролей/секретов;
копирование данных (snapshot/логическая репликация), валидация объёма и контрольных сумм;
переключение трафика (feature flag/маршрутизация по tenant), короткое окно записи или dual‑write;
пост‑контроль: метрики ошибок, задержки, целостность, план отката.
Ключ к снижению рисков — автоматизация шагов и заранее отрепетированные сценарии восстановления.
Даже если база данных настроена идеально, мультиарендность часто «ломается» на уровне приложения: запросы выполняются без tenant_id, фоновые задачи теряют контекст, а конфигурация смешивается между клиентами. Поэтому важно сделать «контекст арендатора» обязательной частью любого входа и любого выполнения кода.
В HTTP API tenant_id обычно выводят из: поддомена (acme.example), JWT/Access Token (claim) либо заголовка (например, X-Tenant-Id). Главное — выбрать один канонический источник и валидировать его на границе.
Для очередей и фоновых задач правило то же: tenant_id должен быть частью полезной нагрузки сообщения и/или метаданных (headers). При постановке задачи в очередь сохраняйте tenant_id вместе с user_id, idempotency key и версией схемы, чтобы обработчик не «догадывался» о контексте по косвенным признакам.
Сделайте защиту по умолчанию: если tenant_id не установлен — запрос отклоняется. Это удобно реализовать через middleware (веб) и через базовый класс/декоратор (фоновые воркеры). На уровне ORM добавьте глобальный фильтр по tenant_id и запретите «сырые» запросы в обход репозиториев без явного разрешения.
Храните настройки по арендаторам отдельно от бизнес‑данных: планы, лимиты, включенные фичи, интеграции, ключи. Хорошая практика — единый Config Service/таблица с версионированием и кэшем, чтобы изменения вступали в силу предсказуемо и не влияли на других клиентов.
Добавьте авто‑тесты, которые создают два арендатора и прогоняют одинаковые сценарии: чтение, поиск, экспорт, фоновые задачи. Полезны property‑based тесты (случайные данные) и негативные проверки: «запрос без tenant_id должен падать».
В staging включайте аудит: логируйте tenant_id на каждом запросе к данным и поднимайте алерт, если он пустой или неожиданно меняется в рамках одного запроса.
Мультиарендность усиливает цену ошибки: одна неверная настройка может открыть данные чужому арендатору. Поэтому безопасность лучше строить слоями: ограничение доступа в самой БД, защита данных «на диске» и «в пути», плюс строгие права для сервисов и прозрачный аудит.
RLS (например, в PostgreSQL) полезен, когда арендаторы делят одни и те же таблицы, а фильтрация по tenant_id должна быть гарантирована на уровне базы. Это снижает риск «забыли добавить WHERE» в одном из запросов.
Типичные ошибки:
tenant_id, которую может подменить клиент. Контекст арендатора должен приходить из проверенного источника (токен/сессия), а в БД — устанавливаться сервером.BYPASSRLS или выдавать доступ к таблицам «напрямую». Лучше работать через ограниченные роли и/или представления.Шифрование «на диске» (TDE/шифрование томов) — базовая гигиена, но для сильной изоляции часто добавляют прикладное шифрование чувствительных полей.
Практика, которая хорошо масштабируется:
Каждый сервис должен иметь минимально необходимые права: отдельные роли для чтения/записи, запрет админских операций из приложения, временные креденшелы, ротация секретов. Секреты храните в менеджере секретов, а не в переменных окружения в открытом виде.
Журналы должны отвечать на вопросы «кто, что, когда, откуда и для какого арендатора». Минимум: события входа, смена прав, доступ к чувствительным данным, экспорт/удаление, ошибки авторизации и срабатывания политик RLS.
Полезно заранее определить сроки хранения, неизменяемость (WORM/append‑only) и быстрый поиск по tenant_id — это заметно ускоряет расследования и ответы на запросы соответствия.
Когда продукт растёт, мультиарендность быстро упирается не в «как хранить данные», а в «как стабильно выполнять запросы при разной нагрузке арендаторов». Ниже — практичные приёмы, которые помогают держать стоимость и задержки под контролем.
Самый понятный способ масштабировать хранение — разделять арендаторов по шардам (нескольким БД/кластерам), выбирая шард по tenant_id.
tenant_id, но нужно следить за консистентностью маршрутизации.Компромисс почти всегда один: чем проще распределение, тем сложнее точечная оптимизация под «тяжёлых» клиентов.
Внутри шарда помогает партиционирование таблиц: по времени (события, логи, транзакции) и/или по tenant_id. «Горячие» данные держите в быстрых таблицах/индексах, а «холодные» — выносите в архивные партиции с более редким обслуживанием. Это ускоряет типовые запросы и делает дешевле хранение.
Даже идеальная схема данных не спасёт, если арендаторы «съедят» соединения.
Общий кеш эффективнее по объёму, но риски выше: ошибки ключей могут привести к утечкам данных между арендаторами. Кеш «по арендатору» проще и безопаснее (ключи с префиксом tenant_id, отдельные пространства/неймспейсы), но дороже.
Практика: кешируйте «неопасные» общие справочники общим кешем, а всё, что связано с пользовательскими данными, — строго с привязкой к арендатору и с понятной стратегией инвалидации (TTL + событие обновления).
Multi-tenant даёт экономию и скорость развития, но приносит классическую проблему noisy neighbor: один арендатор (или отдельный «тяжёлый» сценарий) начинает потреблять непропорционально много ресурсов и ухудшает опыт остальных. Важно не только «поймать» соседа, но и сделать так, чтобы система предсказуемо держала качество сервиса.
Обычно это выглядит как внезапные пики времени ответа, рост ошибок 5xx, «провалы» фоновых задач и очередей, а также деградация только части клиентов (например, в одном регионе или на одном шарде).
Частые причины:
Практика №1 — заранее ввести измеримые квоты и обеспечить их техническое исполнение, а не только прописать в договоре. Типичные лимиты:
Важный нюанс: лимиты должны быть привязаны к tenant_id (или другому признаку арендатора), иначе вы ограничите «всех сразу», а не источник проблемы.
Фоновые работы лучше организовывать через очереди с управлением справедливостью:
Так вы сохраняете предсказуемость: премиальные клиенты получают приоритет, а бесплатные — не ломают общий SLA.
Когда перегрузка уже случилась, нужен заранее продуманный план деградации (graceful degradation). Обычно первыми отключают или ограничивают:
Необязательные фоновые функции: пересчёты, превью, рекомендации.
Тяжёлые пользовательские операции: экспорт, сложные отчёты, массовые действия.
Менее важные интеграции и вебхуки (с буферизацией в очередь), чтобы не терять события.
Ключевой принцип: сохраняйте «ядро» продукта (вход, основные CRUD‑операции, платежи), а всё остальное переводите в режим ограничений — лучше немного медленнее и предсказуемо, чем нестабильно для всех.
Жизненный цикл арендатора — это не только «создали аккаунт и пошли работать». Это цепочка повторяемых операций: подготовка хранилища, выдача доступов, настройка лимитов, обновления схем и корректное удаление. Чем меньше ручных шагов, тем ниже риск ошибок и утечек.
Хорошая практика — оформлять онбординг как детерминированный workflow (с логированием и возможностью повторного запуска). Обычно он включает:
Важно иметь идемпотентность: если процесс оборвался на середине, повторный запуск не должен дублировать ресурсы.
IaC делает окружения воспроизводимыми: одно и то же описание создаёт одинаковые ресурсы для всех арендаторов. Это упрощает проверки изменений (code review), откаты и аудит.
Практически полезно разделять «общую» инфраструктуру и «per‑tenant» сущности, чтобы изменения не затрагивали всех сразу.
Выберите стратегию версионирования схем (например, миграции по порядку с фиксированными версиями). Продумайте, как миграции применяются:
Откат — это не только «вниз» по миграциям: часто безопаснее делать forward‑fix (новая миграция, исправляющая проблему), особенно при преобразовании данных.
Деактивация должна запускать гарантированную очистку: данные, индексы/схемы/БД, ключи и секреты, фоновые задачи, файлы в хранилищах и сетевые правила.
Полезно иметь чек‑лист «сборщика» (garbage collector) и отчёт об удалении, чтобы подтвердить, что ресурсы действительно освобождены.
Мультиарендность усложняет эксплуатацию: один и тот же инцидент может затронуть всех, а может «болеть» только у одного арендатора. Поэтому наблюдаемость здесь должна быть не просто «по сервисам», а ещё и «по арендаторам», чтобы быстро отвечать на вопросы: кого затронуло, почему и сколько это стоило.
Начните с минимального набора, который даёт управляемость:
tenant_id;tenant_id;В логах держите единый формат событий и обязательно добавляйте tenant_id, environment, версию приложения, а также причину отказа (например, quota_exceeded vs validation_error).
Распределённая трассировка полезна только если можно связать фронт, API, фоновые задачи и БД в одну цепочку. Пробрасывайте correlation_id (или trace_id) во все сервисы, а tenant_id — как атрибут спана. Тогда расследование noisy neighbor превращается из догадок в измерения: где именно возник «затор» и на каком шаге.
Делайте два уровня контроля:
Важно не утонуть в алертах: используйте бюджет ошибок и пороги по трендам, а не по единичным всплескам.
С самого начала считайте потребление «единиц» (запросы, активные пользователи, объём хранения, фоновые задачи, egress). Эти отчёты нужны не только для счёта, но и для квот, ограничений и честного управления ресурсами.
Если у вас есть страница /billing, данные для неё должны рождаться из тех же метрик, что и для эксплуатации — так меньше расхождений и спорных ситуаций.
ИИ в архитектуре мультиарендного SaaS полезен не как «автопилот», а как ускоритель мышления: он помогает быстро перебрать варианты, зафиксировать решения и снизить риск пропусков в безопасности и эксплуатации.
Во‑первых, для генерации нескольких архитектурных опций под конкретные ограничения: бюджет на инфраструктуру, требования к изоляции (общая БД vs отдельные схемы/БД), география и регионы, требования по восстановлению.
Хорошая практика — задавать ИИ «рамки» (например, «PostgreSQL + RLS, 2 региона, SLO 99.9%, отдельные ключи шифрования на арендатора») и просить сравнение с явными компромиссами по стоимости, сложности миграций и рискам noisy neighbor.
ИИ отлично справляется с рутиной: черновики диаграмм (контекст арендатора, потоки данных), чек‑листы онбординга, наброски IaC и политик доступа, шаблоны runbook’ов для инцидентов.
Важно воспринимать это как «первую версию», которую команда доводит до стандарта. Полезно хранить итоговые артефакты рядом с репозиторием и обновлять их через ревью (например, в /docs/architecture).
Когда нужно быстро проверить гипотезу по мультиарендности (например, выбрать между tenant_id в общих таблицах и отдельными схемами), удобно начинать с прототипа, который можно итеративно менять без тяжёлого «ручного» программирования. В TakProsto.AI это можно сделать в формате чата: описать требования к изоляции, лимитам и онбордингу — и получить каркас веб‑приложения (React), бэкенда (Go) и PostgreSQL‑модели.
Дальше полезны режим планирования (чтобы зафиксировать решения и компромиссы), снапшоты с откатом (чтобы безопасно пробовать миграции/изменения RLS) и экспорт исходников — когда прототип созрел и его нужно забрать в привычный пайплайн. Отдельный плюс для B2B‑сценариев в РФ — данные и окружения размещаются на серверах в России и не требуют передачи данных за рубеж.
Попросите ИИ составить список угроз и точек отказа: утечки между арендаторами, ошибки в RLS, неожиданные пути обхода авторизации, слабые места миграций схем, проблемы с бэкапами/восстановлением на уровне арендатора. Это помогает сформировать план тестов и «красные флаги» для ревью.
Чтобы ИИ не навредил, нужны правила: утверждённые шаблоны, запрет на небезопасные паттерны, обязательное ревью человеком, автоматические тесты (включая негативные на изоляцию), валидация IaC и политик доступа перед деплоем.
ИИ ускоряет работу, но ответственность за архитектурные решения остаётся у команды.
Лучший способ понять возможности ТакПросто — попробовать самому.