Фуллстек‑фреймворки объединяют UI, сервер и данные. Разберём SSR, API‑роуты, серверные экшены, плюсы, риски и как выбрать подход.
Традиционно фронтенд — это всё, что работает в браузере: разметка, стили, интерактивность, отображение данных и пользовательские сценарии. Бэкенд — серверная часть: бизнес‑логика, базы данных, интеграции, авторизация в веб‑приложении, генерация ответов и контроль доступа.
Граница между ними обычно проходит по простому правилу: браузер «рисует и реагирует», сервер «решает и хранит».
Раньше разделение было не только архитектурным, но и организационным. Фронтенд и бэкенд жили в разных репозиториях, собирались разными инструментами и разворачивались на разных серверах. API выступал «контрактом» между командами, а обмен данными чаще всего сводился к JSON по HTTP.
Такое разделение упрощало ответственность: если сломалась форма — это фронтенд, если неверно рассчиталась цена — это бэкенд. Но оно же добавляло трение: больше согласований, больше сетевых переходов, больше мест для ошибок.
Пользователи привыкли к быстрым интерфейсам, мгновенным переходам и персонализированным страницам. Бизнесу важны SEO и стабильные показатели производительности веб‑приложений. Поэтому рендеринг перестал быть «только фронтом»: SSR и CSR (а также SSG) стали смешиваться в одном продукте, а оптимизация кэша и данных — частью UI‑разработки.
Фуллстек‑фреймворки (например, с серверными компонентами, API‑роутами и серверными экшенами) дают единый способ описывать маршрут, получение данных, рендеринг и обработку действий пользователя — часто в одном проекте или монорепозитории. Это похоже на встроенный BFF (backend for frontend): серверная логика находится «рядом» с интерфейсом и разворачивается как часть того же приложения.
В отличие от библиотеки, фреймворк задаёт правила: структуру проекта, соглашения по маршрутам, подход к SSR/CSR, кэшированию и интеграции с сервером. Именно поэтому говорят, что он «стирает границу» — не потому что фронтенд и бэкенд исчезают, а потому что их задачи всё чаще выполняются в одном стеке и в одной цепочке разработки.
Современные фуллстек‑фреймворки (вроде Next.js, Nuxt, SvelteKit, Remix) похожи не тем, что «умеют всё», а тем, как они организуют работу: проект становится единым приложением, где UI, данные и серверные обработчики живут в одной системе координат.
Часто исчезает привычное разделение на «frontend‑репо» и «backend‑репо». Команда ведёт один проект (иногда в монорепозитории), один набор зависимостей, единые соглашения по структуре папок и один пайплайн сборки/деплоя.
Это уменьшает трение: проще синхронизировать изменения, быстрее поднимать окружения и понятнее, где искать источник проблемы — в коде UI или в серверной логике.
Похожая логика встречается и в современных «vibe‑coding» платформах: когда вы описываете фичу в чате, а система собирает единый проект целиком (UI + сервер + данные), организационная граница между слоями тоже становится тоньше. Например, в TakProsto.AI можно быстро собрать веб‑приложение на React с бэкендом на Go и PostgreSQL, а затем при необходимости экспортировать исходники и продолжить разработку привычным способом.
Ещё один общий знаменатель — стремление разделять модели данных и контракты. Типы, схемы валидации, DTO и утилиты сериализации становятся «общими», а не продублированными. В итоге меньше расхождений между тем, что клиент ожидает, и тем, что сервер реально отдаёт.
Практический эффект: изменение поля в модели обычно требует правки в одном месте и автоматически подсвечивает все места использования.
Маршрутизация часто объединяет несколько уровней: страницу, загрузку данных и обработчик запроса можно держать рядом. Это сближает подход с BFF (backend for frontend): конкретная страница получает «свой» серверный код и «свои» эндпоинты без отдельного сервиса.
Фреймворки поставляются как «операционная система» для веб‑приложения: сборка, оптимизация, работа с переменными окружения, локальная разработка, адаптация под сервер/edge.
Побочный результат — меньше ручной склейки инструментов, но выше важность договорённостей внутри команды: где заканчивается UI и начинается доменная логика (об этом подробнее — в /blog/prakticheskie-rekomendatsii-kak-ne-poteryat-granitsy-vnutri-proekta).
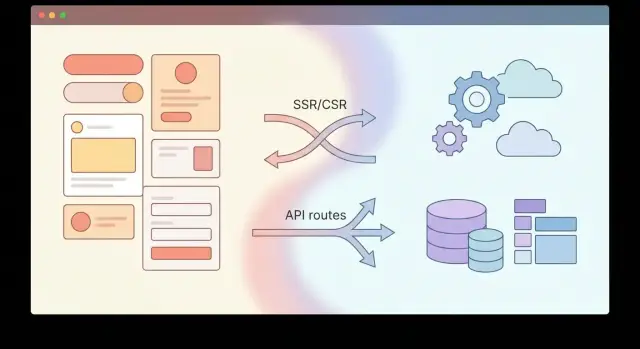
Ещё недавно рендеринг ассоциировался с браузером: фронтенд «рисует» интерфейс, бэкенд отдаёт данные. Современные фуллстек‑фреймворки смешали роли: одна и та же страница может частично собираться на сервере, частично — в браузере, а иногда — генерироваться заранее. Поэтому обсуждение рендеринга стало разговором не про «красивый UI», а про серверные ресурсы, кэширование и контроль доступа.
При SSR сервер формирует HTML для конкретного запроса. Пользователь быстрее видит «первый экран», а поисковые системы получают готовую разметку.
Но это уже зона ответственности бэкенда: серверу нужно сходить за данными, учесть куки/сессию, обработать ошибки и уложиться в бюджет времени. Плохой запрос к базе или медленный внешний API напрямую «ломает» скорость загрузки страницы.
После SSR браузер скачивает JS‑код и «подключает» интерактивность к уже показанному HTML. Это называется гидратацией.
Здесь появляется компромисс: чем больше логики и компонентов нужно гидратировать, тем выше вес бандла и вероятность лагов на слабых устройствах. Поэтому рендеринг — это не только про сервер, но и про то, сколько кода вы всё же отправляете на клиент.
SSG генерирует страницы на этапе сборки — идеально для документации, маркетинговых страниц и контента, который меняется редко. ISR (инкрементальная регенерация) добавляет «полу‑живой» режим: страница пересобирается по расписанию или по триггеру и отдаётся из кэша.
Это снова бэкенд‑вопрос: где хранится кэш, как его инвалидировать, и что считать «достаточно свежим».
CSR (рендер в браузере) уместен там, где главный сценарий — постоянные интеракции: сложные фильтры, канбан‑доски, редакторы, графики. В таких случаях выгоднее один раз загрузить приложение и дальше работать локально, подкачивая данные.
На практике многие проекты выбирают гибрид: SSR/SSG для входа и SEO, CSR — для «личного кабинета». Именно эта смесь и стирает границу фронтенда и бэкенда.
Современные фуллстек‑фреймворки всё чаще предлагают «бэкенд рядом с UI»: вы описываете страницу и тут же — обработчики, которые выполняются на сервере. В итоге граница «фронт рисует, бэкенд обрабатывает» становится менее заметной: один репозиторий, один роутинг, общие типы и единый стиль разработки.
Вместо отдельного сервиса с контроллерами вы создаёте API‑маршруты прямо в проекте приложения — часто в той же структуре, где лежат страницы. Это упрощает путь «форма → обработка»: отправка данных, их проверка, запись в базу и возврат результата живут рядом.
Такой подход удобен для BFF (backend for frontend): API проектируется под конкретный UI, а не как универсальная публичная платформа.
Следующий шаг — серверные экшены (или server functions). Вместо явного fetch на /api вы вызываете функцию, которая выглядит как обычная, но исполняется на сервере. Это снижает количество шаблонного кода (ручные URL, методы, сериализация), а данные и ошибки проще связывать с компонентом.
Когда обработка живёт на сервере, критичную валидацию легче держать «на правильной стороне»: проверять роли, цены, скидки, доступ к объектам и любые поля, которые пользователь может подменить в браузере. Клиентская проверка остаётся для удобства, но источником истины становится сервер.
У встроенного «бэкенда» есть рамки: таймауты и лимиты размера запросов, ограничения на выполнение тяжёлых задач, разное окружение (server/edge) и доступность библиотек. Ещё один практичный момент — наблюдаемость: логирование, трассировка и обработка ошибок должны быть настроены так же внимательно, как в отдельном API‑сервисе.
Фуллстек‑фреймворки всё чаще делают данные «частью рендера»: страница перестаёт быть набором компонентов, которые потом сходят в API, и превращается в единую цепочку — запрос → получение данных → сборка HTML → отображение UI. Для команды это удобно: меньше ручной склейки и меньше шансов, что интерфейс отрисуется «пустым», а затем резко обновится.
Когда данные подтягиваются до того, как страница попадёт в браузер (SSR/серверные компоненты), пользователь быстрее видит готовый контент, а не «скелетон» с крутилкой. Это особенно заметно на медленных сетях и на страницах, где важен первый показ: каталог, карточка товара, профиль.
Но вместе с удобством появляется новая ответственность: фронтенд‑код начинает решать когда и какие данные грузить, а также какими правами — то, что раньше относили к бэкенду.
Кэш теперь может жить в нескольких местах одновременно:
Фреймворк может скрыть часть решений за настройками, но смысл остаётся: тот, кто пишет страницу, фактически управляет тем, как долго данные считаются актуальными и сколько раз система пойдёт «в источник».
После действий пользователя (сохранение формы, лайк, покупка) нужно обновить UI. В современных подходах это часто делается через «переиспользование» той же цепочки: действие → пометить кэш устаревшим → перерендерить нужные части. Это снижает количество ручных синхронизаций состояния, но требует дисциплины: понимать, что именно вы инвалидируете — страницу целиком, конкретный запрос или фрагмент.
Сближение слоёв не отменяет классических ловушек:
Хорошая практика — явно описывать источники данных и точки кэширования, чтобы UI оставался предсказуемым и быстрым.
Фуллстек‑фреймворки сближают UI и сервер настолько, что авторизация перестаёт быть «делом бэкенда». Страницы, компоненты, API‑роуты и серверные экшены живут рядом — а значит, и решения по безопасности принимаются прямо в том месте, где пишется пользовательский поток.
Главное правило: всё, что можно проверить на сервере, лучше проверять на сервере. Cookies (особенно HttpOnly) и серверные сессии удобны тем, что токен не попадает в JavaScript и сложнее для кражи через XSS.
Если используются JWT или другие токены, фуллстек‑подход помогает валидировать их в серверных обработчиках (API‑роуты, server actions) до формирования ответа UI. Клиенту при этом не нужно «угадывать», залогинен пользователь или нет — сервер возвращает уже корректное состояние.
Современные фреймворки дают middleware/route hooks, которые выполняются до рендера маршрута. Там удобно:
Важно не превращать middleware в «свалку логики»: тяжёлые запросы к БД лучше оставить для серверных обработчиков конкретных страниц/эндпоинтов.
Роли в интерфейсе (скрыть кнопку, показать раздел) — это только удобство. Реальная авторизация должна быть серверной: любой пользователь может подделать запрос из консоли или через curl.
Хорошая практика — проверять права на уровне каждой операции: в API‑роуте или серверном экшене перед изменением данных. UI может лишь отражать результат: «доступ запрещён», «нужна подписка», «недостаточно прав».
Когда бэкенд «внутри» фронтенда, легко случайно утащить секреты в клиентскую сборку. Держите ключи API, приватные токены и строки подключения только в серверных переменных окружения и используйте их исключительно в серверном коде.
Полезная привычка: всё, что начинается с «секрет», должно быть недоступно компонентам, которые исполняются в браузере. Если сомневаетесь — считайте код клиентским и выносите работу с секретами в серверный слой фреймворка.
Фуллстек‑фреймворки делают место выполнения кода «плавающим»: один и тот же сценарий можно реализовать на клиенте, на сервере или вынести ближе к пользователю — в edge‑среду. Из‑за этого граница «фронт = браузер, бэкенд = сервер» становится условной: важнее понять, где именно выполняется логика и почему.
Клиентская логика хороша для интерактивности: мгновенные реакции, анимации, управление состоянием формы, оптимистичные обновления.
Но у клиента есть жёсткие лимиты: нельзя безопасно хранить секреты, есть зависимость от мощности устройства, сети и расширений/блокировщиков. Любые тяжёлые вычисления или «умные» фильтры по большим данным быстро превращаются в тормоза и лишний трафик.
Сервер подходит для всего, что требует доверенной среды: работа с базой данных, интеграции с платежами, проверка прав, генерация персонализированного контента.
Цена — задержка сети и стоимость инфраструктуры. Поэтому современные подходы (SSR/серверные компоненты, API‑роуты, серверные экшены) пытаются сократить лишние круги: вызывать нужную логику там же, где рендерится часть UI.
Edge удобен для задач, где важна минимальная задержка: гео‑редиректы, A/B‑эксперименты, лёгкая персонализация, валидация токена и установка cookie, кэширование фрагментов.
Что лучше переносить на edge:
Что обычно оставляют на сервере:
Граница ответственности смещается от «папок» к правилам: какие данные и секреты где допустимы, какие SLA по задержкам, какие зависимости разрешены в edge runtime.
Практичный подход — явно помечать слои (client/server/edge) на уровне модулей и контрактов, а также держать единые политики доступа (например, в middleware) и единые функции‑«шлюзы» к данным. Тогда даже в монорепозитории не возникает ощущения, что всё можно делать «где угодно».
Фуллстек‑фреймворки действительно сближают слои, но на формах, загрузке файлов и фоновых задачах хорошо видно: часть «бэкендовой» ответственности никуда не исчезает. Просто она становится ближе к UI и чаще живёт в одном репозитории.
Серверные экшены и типизированные схемы валидации позволяют описать правила один раз и использовать их и при отправке формы, и на сервере. Это снижает риск ситуации «на клиенте прошло, на сервере упало». Но важно помнить: клиентская проверка — для удобства, серверная — обязательна.
Когда форма вызывает серверную логику напрямую, становится проще протянуть в интерфейс корректные статусы: «сохранено», «в процессе», «нужно исправить поля». Хорошая практика — разделять:
Это уже не «чисто фронт»: вы проектируете контракт между обработчиком на сервере и UI‑состояниями.
Фреймворк может дать удобный маршрут/экшен, но хранение файлов, антивирусная проверка, ограничение типов/размеров, выдача временных ссылок — это инфраструктура (S3‑совместимое хранилище, CDN, политики доступа). Аналогично с тяжёлыми операциями: генерация отчётов, обработка изображений, рассылки.
Как только операции выходят за рамки быстрого HTTP‑запроса, нужны очередь и воркеры, ретраи, дедупликация, планировщик. Здесь граница остаётся: UI инициирует задачу и показывает прогресс, а выполнение живёт отдельно (очереди/cron/воркеры), даже если код рядом в монорепозитории.
Сближение фронтенда и бэкенда в современных фуллстек‑фреймворках — это не про «один человек делает всё», а про то, что команда начинает работать с продуктом как с единой системой: UI, данные и серверная логика проектируются вместе. В результате уменьшается трение на стыках и быстрее появляется ценность для пользователя.
Когда API‑роуты, серверные экшены и UI живут в одном проекте, многие решения принимаются «на месте»: не нужно неделями согласовывать контракты, ждать отдельный релиз бэкенда или держать временные заглушки.
Это особенно заметно в задачах «привязать кнопку к действию»: форма → валидация → сохранение → обновление интерфейса. Чем меньше ручных стыковок, тем меньше ошибок и недопонимания.
Компоненты интерфейса, которые знают, какие данные им нужны, проще стандартизировать. Дизайн‑система становится не только набором кнопок и полей, но и набором устойчивых паттернов: таблица с пагинацией, карточка сущности, форма редактирования.
Когда эти паттерны живут рядом с запросами и кэшем, меньше дублирования: одинаковые правила форматирования, одинаковые состояния загрузки и ошибок, единые требования к доступности.
Для MVP часто важнее проверить гипотезу, чем построить идеальную многоуровневую архитектуру. Фуллстек‑подход позволяет собрать «вертикальный срез» фичи целиком: экран + серверное действие + минимальная модель данных.
В такой логике полезны инструменты, которые ускоряют путь «идея → работающий прототип». Например, TakProsto.AI позволяет собрать прототип веб‑ или мобильного приложения через диалог, а затем (если гипотеза подтвердилась) перейти к доработке в команде с экспортом исходного кода, снапшотами и откатом.
Когда запрос пользователя проходит через одну цепочку (от сервера до UI), проще настроить единый контекст: корреляционные ID, трассировку, структурные логи. При корректной настройке команда быстрее отвечает на вопросы «почему медленно?» и «где сломалось?» — без ручного сопоставления логов из разрозненных сервисов.
Сближение фронтенда и бэкенда ускоряет разработку, но повышает цену ошибки: границы ответственности становятся неочевидными, а технические решения — более «липкими».
Когда один и тот же фреймворк отвечает и за рендеринг, и за загрузку данных, один баг легко «прыгает» между слоями.
Например, пользователь видит пустой блок: это может быть ошибка в SSR, неверный ключ кэша, падение серверного экшена или несовпадение схемы данных. Логи часто разбросаны по разным средам (браузер, сервер, edge), а воспроизведение зависит от того, где именно выполнился код.
Удобство совместного кода провоцирует расползание бизнес‑логики по UI: проверки, правила ценообразования, расчёты доступов и статусов оказываются в компонентах и хендлерах форм.
Это ускоряет первый релиз, но усложняет поддержку: правила дублируются, а изменение процесса требует правок в нескольких местах. Практичный симптом — «умные» компоненты, которые и рисуют, и запрашивают, и валидируют, и принимают решения.
Серверные компоненты, API‑роуты и серверные экшены часто завязаны на конкретные рантаймы, ограничения edge, способ работы с файловой системой и переменными окружения. Переезд на другой хостинг или вынос части логики в отдельный сервис может внезапно потребовать переработки архитектуры.
Важно договориться, где какие тесты живут:
Без этого тесты превращаются в хаотичный набор, который либо ничего не ловит, либо постоянно ломается.
Фуллстек‑фреймворк лучше всего работает там, где продукт можно «вести одной командой» и где тесная связка UI, данных и рендеринга даёт выигрыш в скорости разработки. Но он не обязан быть универсальным ответом: иногда границы между слоями стоит вернуть обратно — осознанно и по сигналам.
Если команда небольшая, фуллстек‑подход реально ускорит поставку: меньше договорённостей между фронтом и бэком, быстрее прототипы, проще внедрять изменения «от кнопки до запроса». Особенно это удобно для продуктов на ранней стадии, внутренних сервисов, админок и приложений, где основной риск — не масштаб, а время.
Если продукт про контент и SEO, делайте упор на SSR/SSG: серверный рендеринг и генерация страниц упрощают индексацию, улучшают метрики скорости первой отрисовки и позволяют выстроить предсказуемую цепочку «запрос → данные → HTML».
Если нужен сложный домен и много интеграций (платежи, биллинг, документооборот, несколько внешних поставщиков данных), лучше выделяйте отдельный сервисный бэкенд. Так проще удерживать архитектуру: доменная логика, очереди, ретраи, аудит, права доступа и интеграционные контракты живут в одном месте и не «растекаются» по UI.
Есть понятные триггеры, после которых монолитный фуллстек начинает мешать:
Практичный компромисс — оставить фуллстек‑фреймворк как BFF (backend for frontend), а ядро домена вынести в отдельный сервис. Так вы сохраняете скорость на уровне интерфейса, но возвращаете границы там, где они критичны.
Фуллстек‑фреймворк удобен тем, что «всё рядом»: компоненты, загрузка данных, API‑роуты, серверные экшены. Но именно из‑за близости быстро появляется «спагетти», когда бизнес‑правила случайно расползаются по UI, а запросы к данным — по случайным файлам.
Зафиксируйте в README и в ревью‑правилах простую модель: где живёт доменная логика (правила расчётов, статусы, ограничения), а где только UI (рендер, форматирование, реакции на события).
Практика: всё, что влияет на корректность данных, должно выполняться на сервере. Клиент может улучшать UX, но не быть «истиной».
Разложите проект на понятные зоны и запретите «обходные тропы» импортами:
data/access — доступ к БД/внешним API, без знаний про UIservices — бизнес‑операции (use‑cases), транзакции, правилаpages/components — экран и компоненты, без прямых запросов в БДЕсли используете монорепозиторий, закрепите границы линтером (например, правилами импортов) и код‑ревью.
Секреты (ключи, токены, DSN) — только на сервере и только через переменные окружения.
Валидация входных данных — на сервере всегда, даже если есть клиентская. Любой API‑роут/экшен должен проверять права доступа так, будто его вызывает злоумышленник.
Если продукт работает с чувствительными данными, отдельно зафиксируйте требования к размещению и обработке: где находятся серверы, какие модели используются, куда уходят логи и трассы. Это особенно актуально для российского рынка — и здесь может быть полезно, что TakProsto.AI работает на серверах в России, использует локализованные и опенсорс‑модели и не отправляет данные за пределы страны.
Перед релизом пройдитесь по короткому списку: метрики производительности, централизованные логи, единая стратегия обработки ошибок, понятные TTL/инвалидация кэша, алерты на рост 4xx/5xx. Это помогает сохранить управляемость, даже когда «фронт» и «бэк» в одном репозитории.
Это не означает, что слои «исчезают». Речь о том, что в одном проекте и одном стеке вы делаете и UI, и серверные обработчики (API‑роуты, server actions), и загрузку данных для SSR/SSG. В результате решение задач распределяется не по репозиториям, а по месту выполнения кода (client/server/edge) и по правилам безопасности/данных.
Библиотека обычно отвечает за один слой (например, UI) и оставляет вам выбор инструментов вокруг. Фуллстек‑фреймворк задаёт соглашения: роутинг, SSR/CSR/SSG, кэширование, окружения, API‑роуты/серверные функции и деплой. Это ускоряет интеграцию, но повышает зависимость от правил фреймворка.
SSR полезен, когда важны быстрый «первый экран» и SEO: каталог, карточки, контентные страницы.
Проверьте заранее:
Если страница персонализирована, учитывайте куки/сессию и влияние на кэширование.
Гидратация — это момент, когда показанный после SSR HTML становится интерактивным за счёт загрузки и выполнения JS в браузере.
Практика:
API‑роуты — это привычные HTTP‑эндпоинты внутри проекта рядом со страницами.
Серверные экшены/функции позволяют вызывать серверную логику как функцию, уменьшая шаблонный код (URL, сериализация). Но правила остаются «бэкендовыми»: валидация, авторизация, лимиты, таймауты, логирование.
Для публичных интеграций чаще удобнее явные API‑эндпоинты; для действий формы в конкретном UI — server actions.
Всегда держите «истину» на сервере:
Кнопки и скрытие элементов в UI — это лишь UX, не защита.
Кэш может быть в браузере, на сервере и на CDN/edge одновременно. Чтобы избежать «магии»:
Сигнал проблемы — неожиданные «водопады» и расхождения данных между частями UI.
Клиент — для интерактивности и мгновенных реакций, но без секретов и с ограничениями устройства.
Сервер — для доверенной логики: БД, платежи, права, персонализация.
Edge — для задач с минимальной задержкой и лёгкими вычислениями: редиректы, простая проверка сессии, A/B, тонкая персонализация. Не переносите на edge тяжёлые запросы к основной БД и сложные интеграции, если runtime ограничен.
Загрузка файлов, антивирусная проверка, ограничения размера/типа, выдача временных ссылок и хранение (S3‑совместимое, CDN) — это всё равно инфраструктура.
Если операция дольше обычного HTTP‑запроса (отчёты, обработка изображений, рассылки), выносите выполнение в фон:
Фреймворк может упростить «точку входа», но не заменяет эту архитектуру.
Обычно подходит, если важны скорость разработки, цельный UX и одна команда ведёт продукт (MVP, админки, контент+SEO).
Лучше разделять, если:
Компромисс: оставить фреймворк как BFF, а доменное ядро вынести в отдельный сервис. Чтобы не потерять границы внутри проекта, зафиксируйте правила слоёв и импортов (подробнее: /blog/prakticheskie-rekomendatsii-kak-ne-poteryat-granitsy-vnutri-proekta).