Индексы ускоряют поиск, сортировку и JOIN, но требуют места и обслуживания. Разберём виды индексов, правила выбора и частые ошибки.
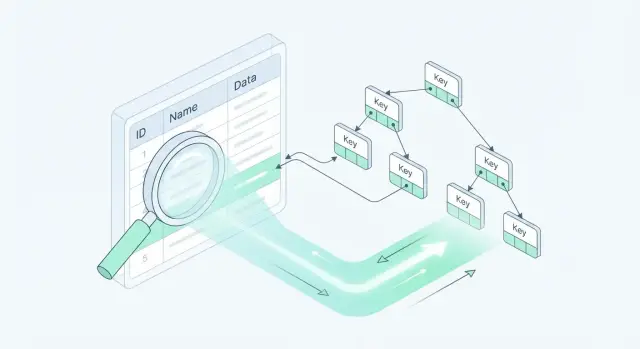
Индекс в базе данных — это отдельная структура, которая помогает находить строки быстрее, чем при просмотре всей таблицы. Проще всего представить индекс как «оглавление» или алфавитный указатель: вы сначала находите нужный ключ (значение), а уже потом быстро переходите к нужным страницам (строкам).
Если по нужному полю индекса нет, то при запросе вида WHERE поле = значение базе часто приходится делать полный проход по таблице — читать строку за строкой и проверять условие. На маленьких таблицах это почти незаметно, но когда строк сотни тысяч или миллионы, такой «просмотр всего списка» становится одной из главных причин медленных запросов.
Индекс позволяет избежать этого: вместо последовательного чтения база может сразу перейти к небольшому диапазону подходящих значений и извлечь только нужные строки.
Чаще всего индексы дают ускорение там, где базе нужно:
WHERE), особенно по точному совпадению или узкому диапазону.JOIN) по ключам — когда одна таблица быстро находит совпадения в другой.ORDER BY) и иногда группировать (GROUP BY) — если порядок в индексе совпадает с тем, что требуется запросу.Важно: индекс ускоряет именно чтение/поиск. Он не делает «всё быстрее» автоматически — но очень часто именно поиск и является узким местом.
Представьте распечатанный список сотрудников на 5 000 страниц. Если вам нужно найти Иванова, без алфавитного указателя вы будете перелистывать страницы, пока не встретите фамилию. Алфавитный указатель — это и есть индекс: вы открываете раздел на «И», находите «Иванов» и сразу переходите на нужную страницу. В базе данных происходит то же самое, только вместо страниц — строки, а вместо фамилий — значения в колонке.
Большинство «тормозов» в базе данных связано не с тем, что сервер «медленно считает», а с тем, что ему приходится слишком много читать. Чтение данных с диска (или даже из памяти, но большими объёмами) — это I/O, и именно оно часто съедает львиную долю времени запроса. Если запрос вынужден просмотреть миллионы строк, он почти неизбежно становится медленным.
Когда таблица большая, самый дорогой сценарий — полный просмотр (full scan): база перебирает строки, проверяет условие и отбрасывает неподходящие. Даже если проверка условия проста, стоимость перебора огромна: нужно прочитать много страниц данных, часто «впустую».
Индекс позволяет быстро найти, где лежат нужные строки, вместо того чтобы «листать» всё подряд.
Практический эффект обычно такой:
Именно поэтому индексация базы данных часто даёт прирост в разы и на порядки: вы сокращаете объём работы, а не ускоряете ту же самую работу.
Можно переписать SQL, убрать лишние поля в SELECT, уменьшить сетевую передачу, настроить кэш — всё это помогает. Но если база всё равно читает почти всю таблицу, потолок ускорения невысок. Индексы SQL обычно меняют сам характер выполнения запроса: от «прочитать всё» к «найти конкретное».
Индекс не спасёт, если причина медленная сама по себе:
В этих случаях сначала исправляют смысл запроса и модель данных — и только затем индексы дают максимальный эффект.
Когда вы запускаете запрос, база данных не «просто читает таблицу». Сначала она решает, как именно его выполнять: откуда брать строки, в каком порядке, какими методами фильтровать и соединять данные. Этот маршрут фиксируется в плане выполнения запроса.
План выполнения — это список шагов, которые СУБД выполнит для вашего SQL. В нём видно, будет ли использован индекс, сколько строк ожидается прочитать, и где возникнет основная стоимость.
Практически: если запрос медленный, план часто объясняет почему — например, БД читает «почти всё», хотя вы ожидали точечный поиск.
Есть два типичных сценария:
WHERE для каждой.Например, запрос вида:
SELECT * FROM orders WHERE order_id = 123;
почти всегда выигрывает от индекса по order_id, потому что это «поиск одного значения», а не просмотр всего списка.
Оптимизатор сравнивает несколько вариантов планов и выбирает тот, где ожидается меньше работы. Он опирается на статистику: сколько уникальных значений в колонке, насколько распределены данные, сколько строк вернёт фильтр.
Если условие WHERE предполагает, что будет найдено слишком много строк (например, половина таблицы), то идти через индекс может быть даже дороже, чем прочитать таблицу последовательно.
Индекс могут не применить, если:
Поэтому полезная привычка — смотреть план выполнения и проверять, какой именно путь выбрала СУБД, а не только факт наличия индекса.
Индексы бывают разными — и важно понимать, какой тип зачем нужен.
Кластерный индекс определяет физический порядок хранения строк на диске (или, точнее, логический порядок страниц данных). Поэтому таблица может иметь только один кластерный индекс: данные нельзя «отсортировать» одновременно по двум разным признакам.
Некластерный индекс — отдельная структура: в нём хранятся значения ключа и ссылка на строку (или на кластерный ключ). Их может быть много, и они не меняют порядок хранения самой таблицы.
Самый распространённый тип — B-tree индекс (в большинстве SQL СУБД это вариант по умолчанию). Он хорош, когда запросы используют:
WHERE status = 'paid');WHERE created_at >= ... AND created_at < ...);ORDER BY created_at DESC LIMIT 50).Именно поэтому B-tree чаще всего даёт максимальную практическую пользу.
Хеш-индекс ускоряет строгое равенство по ключу (поиск «точно такого значения»). Но у него есть ограничения: он не помогает для диапазонов, сортировок и условий вроде > / <. Поэтому для дат, сумм, «последних событий» и любых сравнений обычно выбирают B-tree.
Покрывающий индекс — это индекс, который содержит все поля, нужные запросу (в ключе или как включённые колонки, если СУБД поддерживает). Тогда база может ответить «прямо из индекса», не читая строки таблицы. Это уменьшает I/O и часто резко ускоряет частые отчётные запросы.
Уникальный индекс гарантирует отсутствие дублей (например, для email или order_number). Это одновременно про скорость (быстрый поиск) и про качество данных: база сама не даст записать повторяющееся значение, снижая риск логических ошибок в приложении.
Индекс помогает быстрее находить нужные строки. Поэтому ключевой вопрос — насколько хорошо выбранное поле «сужает» поиск.
Селективность — это доля строк, которая проходит условие.
Практическое правило: чем меньше строк вы ожидаете получить по условию, тем выше шанс, что индекс «выстрелит».
Поля вроде status (3–5 вариантов), is_active (0/1), gender и подобные обычно имеют низкую селективность. Фильтр WHERE is_active = true может выбирать половину таблицы — и чтение через индекс превращается в длинный проход по индексу плюс множество обращений к таблице. Нередко проще и быстрее сделать последовательное чтение (полный скан).
Исключение — когда «редкое» значение действительно редкое. Например, is_blocked = true встречается в 0.01% строк — тогда индекс может быть очень полезен.
Кардинальность — это количество уникальных значений в столбце. Обычно высокая кардинальность (например, email, номер заказа) означает лучшую селективность.
Но важна не только уникальность, а распределение. Если 90% строк имеют одно и то же значение, а остальные 10% распределены между тысячами значений, индекс будет полезен только для «редкого хвоста», но почти бесполезен для «популярного» значения.
Оптимизатор решает, использовать индекс или нет, опираясь на статистику: сколько строк в таблице, насколько часто встречаются значения, как они распределены. Если статистика устарела (данные сильно изменились), план выполнения может стать неоптимальным: индекс не используется там, где нужен, или используется там, где только мешает.
Поэтому после крупных загрузок данных и заметных изменений распределения важно обновлять статистику — иначе даже хороший индекс может не дать ожидаемого ускорения.
Составной индекс — это индекс сразу по нескольким колонкам. Он особенно полезен, когда запросы почти всегда фильтруют данные по комбинации условий, и одного столбца «мало», чтобы быстро сузить поиск.
Если вы ищете заказы по user_id и одновременно по статусу или дате, отдельный индекс на user_id может находить слишком много строк (особенно у активных пользователей). Составной индекс позволяет сузить выборку раньше.
Порядок колонок в составном индексе критичен: база данных строит структуру так, что сначала упорядочены значения первого поля, внутри них — второго и т. д.
Практическое правило: первым ставьте то, что чаще участвует в фильтрации и лучше «отсекает» строки (высокая селективность). При этом, если вы почти всегда фильтруете по одному полю, а второе используется редко, иногда лучше оставить индекс одноколоночным, а второе поле индексировать отдельно.
Составной индекс работает по принципу левого префикса: индекс (A, B, C) эффективно помогает, когда запрос использует A, или A и B, или A и B и C. А вот условие только по B (без A) обычно не сможет полноценно использовать этот индекс.
WHERE user_id = ? ORDER BY created_at DESC часто выигрывает от индекса (user_id, created_at): сначала быстро выбираются строки пользователя, затем они уже «лежат» в нужном порядке.order_id и дополнительно фильтруете по status, индекс (order_id, status) может сократить количество строк, которые участвуют в JOIN.Один широкий индекс не всегда заменяет два узких. Если у вас есть два разных шаблона запросов — например, одни фильтруют по user_id, другие по status — два отдельных индекса могут дать больше пользы и меньше «побочных эффектов» при вставках/обновлениях, чем один составной, который подходит лишь частично.
Индекс особенно полезен там, где запросу нужно найти совпадения между таблицами, отсортировать данные или сгруппировать их. В этих случаях база данных либо быстро «прыгает» к нужным строкам, либо вынуждена читать большие объёмы и потом долго обрабатывать.
В типичном JOIN вы соединяете таблицы по user_id, order_id, product_id и т. п. Если на колонке соединения есть индекс (часто это первичный ключ на одной стороне и внешний ключ на другой), движок может быстро находить пары строк без полного перебора.
Практическое правило: индекс нужен на колонке, по которой ищут соответствия. Особенно важно индексировать внешний ключ в «большой» таблице (например, orders.user_id), иначе соединение часто превращается в дорогое сканирование.
Сортировка — одна из самых «тяжёлых» операций. Если индекс уже хранит данные в нужном порядке, СУБД может вернуть строки в отсортированном виде без отдельной сортировки.
Пример: запрос вида WHERE user_id = ? ORDER BY created_at DESC. Индекс (user_id, created_at) позволяет и отфильтровать по пользователю, и сразу получить правильный порядок.
С GROUP BY похожая логика: индекс по полю группировки помогает быстрее проходить данные «группами», снижая объём промежуточной работы.
Пагинация через OFFSET 100000 заставляет базу «пропустить» множество строк, даже если вам нужно 20 записей.
Индекс помогает, но лучше использовать keyset pagination: WHERE created_at < ? ORDER BY created_at DESC LIMIT 20. Тогда СУБД берёт «следующую страницу» через индекс, без дорогостоящих пропусков.
Фильтры по времени (created_at BETWEEN ...) — частый сценарий для логов, заказов, событий. Индекс по created_at (или составной, если есть дополнительный фильтр вроде user_id) позволяет быстро взять нужный диапазон, вместо чтения всей таблицы.
Нюанс: индекс помогает сильнее всего, когда вы сначала сужаете выборку (WHERE), а затем сортируете/группируете по тем же полям или в совместимом порядке.
Индекс ускоряет чтение, потому что база данных перестаёт «перелистывать» всю таблицу. Но у этой скорости есть цена: индекс — это отдельная структура данных, которую нужно хранить, держать в памяти и постоянно обновлять.
Каждый индекс занимает место на диске — иногда сравнимое с размером самих данных, особенно если вы индексируете длинные строки или много колонок.
Кроме диска важна память: чтобы индекс действительно ускорял запросы, его страницы должны попадать в кэш (буферный пул). Чем больше индексов, тем сильнее конкуренция за память: кэш «размазывается», вытесняя полезные данные и другие индексы. В итоге скорость может падать не из‑за CPU, а из‑за лишних чтений с диска.
Чтение ускоряется, но запись дорожает. При INSERT/UPDATE/DELETE база данных обязана обновить не только строку, но и все связанные индексы.
Это проявляется так:
Чем больше индексов — тем больше работы на каждую запись, выше нагрузка на журнал транзакций и больше блокировок/ожиданий.
По мере изменений данные и страницы индекса перестают быть компактными. Появляются разрывы, лишние страницы, хуже последовательность чтения. Сначала этого не видно, но затем запросы начинают делать больше операций ввода‑вывода и чаще упираются в диск.
Лёгко попасть в ловушку: «добавим индекс на всё». Но лишние индексы редко используются, зато всегда обслуживаются.
Практическое правило: индекс должен обслуживать конкретные критичные запросы. Если он не участвует в планах выполнения и не даёт измеримого выигрыша — вы платите за него каждый день, не получая скорости.
Работа с индексами начинается не с «давайте добавим индекс», а с диагностики. Индекс — это лекарство для конкретных запросов, а не универсальная таблетка.
Самые частые сигналы: отдельные запросы выполняются «вечность», периодически случаются скачки нагрузки на CPU/диск, пользователи видят таймауты, а в логах появляются всплески медленных SELECT.
Если проблема проявляется волнами, смотрите не только на один «плохой» запрос, но и на то, как часто он запускается.
Начните с двух источников:
Соберите 5–20 запросов, которые одновременно (а) заметно дорогие и (б) часто повторяются, и работайте только с ними.
Проверьте план выполнения запроса (например, через EXPLAIN). Признаки проблем:
Дополнительно полезны метрики по индексам: число сканов по индексу, cache hit, количество прочитанных страниц/блоков.
Удалять индекс имеет смысл, если он почти не используется в чтении, но создаёт цену в записи: замедляет INSERT/UPDATE/DELETE, раздувает размер базы и усложняет обслуживание. Сначала убедитесь, что он не нужен редким, но критичным отчётам или ночным задачам — и только потом планируйте удаление (лучше в окно низкой нагрузки).
Индекс сам по себе не гарантирует ускорения. Часто он создан «правильно», но запрос написан так, что оптимизатор просто не может им воспользоваться — и вы получаете тот же full scan, только ещё и с лишними затратами на поддержку индекса.
Типичная ситуация: вы оборачиваете колонку функцией, и поиск по индексу становится невозможен.
Плохо: WHERE LOWER(email) = 'a@b.com' или WHERE DATE(created_at) = '2025-01-01'.
Лучше: хранить нормализованное значение (например, email_lower) и индексировать его, либо переписать условие на диапазон: created_at >= '2025-01-01' AND created_at < '2025-01-02'.
В составном индексе порядок полей критичен. Индекс (status, created_at) хорошо подходит для WHERE status = ... AND created_at BETWEEN ..., но может быть почти бесполезен для WHERE created_at BETWEEN ... без фильтра по status.
Практическое правило: первыми ставьте поля, которые чаще всего участвуют в фильтрации равенством, затем — диапазоны и сортировки.
Индекс «на всё подряд» кажется универсальным, но он тяжёлый: занимает больше места, хуже помещается в память и дороже обновляется. Отдельная проблема — когда рядом лежат два индекса, которые почти одно и то же (например, (user_id) и (user_id, created_at) при отсутствии запросов, использующих только первый).
Если user_id хранится как строка, а в запрос прилетает число (или наоборот), СУБД может делать неявное преобразование и не использовать индекс. То же касается сравнения VARCHAR с TEXT, разных кодировок, несоответствия дат/строк.
Добавлять индексы «на всякий случай» — плохая стратегия. Каждый индекс замедляет INSERT/UPDATE/DELETE и усложняет обслуживание. Перед добавлением сверяйтесь с планом выполнения запроса и измеряйте изменения на реальных данных (подробнее — в разделе /blog/plan-vypolneniya-zaprosa).
Добавление индекса — это не «поставили галочку и стало быстрее», а небольшая инженерная процедура. Если действовать по шагам, вы получите ускорение чтения и не устроите сюрпризов записи, размеру базы и планировщику запросов.
Берите не «всё тормозит», а конкретный запрос: из логов медленных запросов, APM или мониторинга. Зафиксируйте:
Если есть возможность — сохраните текст запроса и параметры. Важно сравнивать «до/после» на одинаковых условиях.
Откройте план выполнения (EXPLAIN / EXPLAIN ANALYZE). Ищите признаки проблемы: полный проход по таблице, большой объём чтения, сортировку на миллионах строк, дорогой JOIN.
Не пытайтесь оптимизировать «в целом» — план подсказывает, какую часть запроса база выполняет наиболее затратным способом.
Индекс должен соответствовать реальному фильтру/соединению/сортировке в запросе. После добавления проверьте план ещё раз: появился ли Index Scan/Seek и уменьшилось ли число прочитанных строк.
Если индекс не используется — вероятно, неверные колонки, порядок в составном индексе, низкая селективность или устаревшая статистика.
Каждый индекс ускоряет чтение, но замедляет INSERT/UPDATE/DELETE и увеличивает размер (и бэкапы). Прикиньте:
По возможности создавайте индекс без долгой блокировки (у многих СУБД есть online/конкурентное создание). Выкатывайте в низкую нагрузку, следите за метриками и обязательно сравните результаты с «до»: время, чтение, нагрузка на CPU/IO.
Если ускорения нет — откатывайте индекс. Индексация должна быть доказуемой, а не «на всякий случай».
В реальных командах индексация почти всегда идёт вместе с двумя задачами: быстро воспроизвести проблемный запрос и так же быстро проверить гипотезу (план выполнения, фактические чтения, регрессии после изменений).
Если вы делаете продукт и хотите сократить время от идеи до результата, полезно иметь среду, где можно быстро собрать сервис, подключить PostgreSQL и итеративно проверять запросы. Например, в TakProsto.AI (vibe-coding платформа для российского рынка) можно за короткое время собрать веб/бэкенд-приложение на React + Go + PostgreSQL, воспроизвести «медленный запрос» на реальных данных и пройти тот же цикл, который описан выше: метрики → EXPLAIN → индекс → проверка. При этом остаётся возможность экспортировать исходники, настроить деплой, откаты (snapshots/rollback) и работать в предсказуемой инфраструктуре на серверах в России.
Индексы дают максимум пользы, когда вы добавляете их не «на всякий случай», а под конкретные запросы и проверяете результат измерениями.
Соберите список самых частых и самых дорогих запросов (по времени, I/O, числу строк, блокировкам). Оптимизация редких запросов почти всегда проигрывает по эффекту оптимизации «топ-10» по нагрузке.
JOIN), и колонки из WHERE.Если запрос очень популярный, имеет узкий набор выбираемых колонок и всё ещё медленный, подумайте о покрывающем индексе (когда нужные поля можно прочитать из индекса). Делайте это только для действительно «горячих» запросов: покрывающие индексы увеличивают размер и стоимость обновлений.
Схема и нагрузка меняются: то, что ускоряло год назад, сегодня может быть лишним. После релизов, миграций, изменений запросов и роста данных пересматривайте:
Сравнивайте «до/после» по плану выполнения и метрикам (время, логические чтения, число возвращаемых строк). Если улучшения нет — откатывайте, а не оставляйте индекс «на всякий случай».
Индекс — это отдельная структура данных, которая позволяет БД находить нужные строки по значению колонки без полного просмотра таблицы.
В практических терминах он превращает запрос вида WHERE поле = значение из «прочитать всё и проверить» в «быстро найти нужный диапазон ключей и перейти к строкам».
Без индекса БД часто вынуждена делать полный проход по таблице (full scan): читать строку за строкой и проверять условие.
На больших объёмах данных основная стоимость — это I/O и количество прочитанных страниц, поэтому даже «простые» фильтры становятся медленными.
Чаще всего индексы ускоряют:
WHERE (равенство и узкие диапазоны);JOIN по ключам;ORDER BY (когда порядок индекса совпадает с сортировкой);GROUP BY (когда полезен проход по данным в уже сгруппированном порядке).Потому что оптимизатор выбирает план, который (по статистике) требует меньше работы.
Индекс могут не использовать, если фильтр возвращает слишком много строк, если сравнение идёт с неявным приведением типов или если условие написано так, что индекс неприменим.
Посмотрите план выполнения запроса (EXPLAIN / EXPLAIN ANALYZE). В нём видно:
Индексацию стоит делать только под запросы, где план показывает лишние чтения.
B-tree — универсальный вариант для большинства сценариев: равенство, диапазоны, сортировка, выборка «последних N».
Хеш-индекс полезен в основном для строгого равенства по ключу, но не помогает для диапазонов и ORDER BY, поэтому в типичных приложениях чаще выигрывает B-tree.
Кластерный индекс задаёт порядок хранения строк (логический порядок страниц данных), поэтому он может быть только один.
Некластерные индексы — отдельные структуры со значением ключа и ссылкой на строку; их может быть много, и они не меняют порядок строк в таблице.
Селективность — доля строк, которые проходит условие. Чем меньше строк возвращает фильтр, тем полезнее индекс.
Поля с низкой селективностью (is_active, status с 3–5 значениями) часто не дают ускорения, потому что БД всё равно прочитает большую часть таблицы.
Составной индекс (A, B, C) эффективно работает по «левому префиксу»: когда в запросе есть A, или A и B, или A и B и C.
Практически это означает:
Индексы ускоряют чтение, но увеличивают стоимость записи:
INSERT/UPDATE/DELETE должен обновить все индексы;Правило: держите индексы только под реальные критичные запросы и удаляйте неиспользуемые после проверки.
WHERE created_at BETWEEN ... индекс (status, created_at) может не помочь без условия по status.