SQLite используют повсюду: в приложениях, браузерах и устройствах. Разбираем, почему встроенная serverless БД стала стандартом, где она сильна и где нет.
SQLite — это база данных, которая чаще всего не выглядит как «отдельная система». Она живёт внутри приложения и обычно сводится к одному файлу на диске. Именно поэтому многие пользователи (и даже часть разработчиков) взаимодействуют с ней ежедневно — и не замечают.
Embedded (встроенная) в контексте SQLite означает: это не внешний сервис, а библиотека, которая подключается к приложению. Приложение само «носит» базу данных с собой и напрямую читает/пишет данные.
Serverless здесь — не про облака, а про отсутствие отдельного сервера БД. Не нужно поднимать процесс PostgreSQL/MySQL, настраивать порты, пользователей, бэкапы «сервисом» и дежурство администратора. Всё работает «из коробки»: установили приложение — получили хранилище.
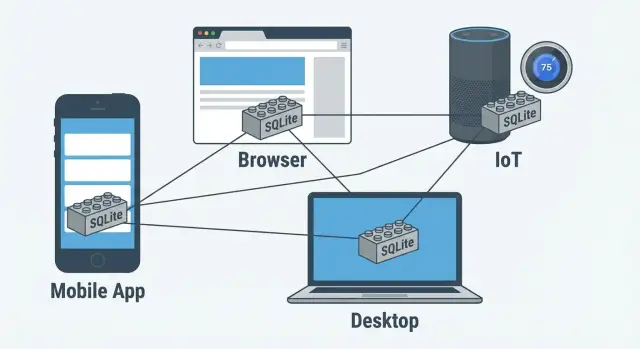
Кажется странным: как база «без сервера» может быть повсюду? Но именно это и сделало SQLite массовой. Её выбирают там, где важны простота и предсказуемость: мобильные приложения, десктопные программы, браузеры, кассовые системы, IoT и edge‑устройства.
У SQLite нет отдельной точки отказа в виде сервера: приложение может работать офлайн, на слабом устройстве и без сетевого доступа. А ещё SQLite легко встраивается в любые языки и платформы — поэтому она оказывается в миллиардах установок как часть других продуктов.
Чтобы понять, где SQLite — идеальное решение, а где начинаются ограничения, дальше разложим тему по полочкам:
Если вы когда-либо открывали приложение, которое «просто хранит данные» — с высокой вероятностью где-то рядом уже работала SQLite. Важно понимать её сильные стороны, чтобы использовать её осознанно, а не случайно.
SQLite часто называют «встроенной» и «serverless» базой данных — и это не маркетинг. На практике SQLite — это библиотека, которую вы подключаете к приложению, и один файл, в котором лежит база.
Вместо отдельного процесса, который слушает порт и принимает запросы по сети, SQLite работает внутри того же процесса, что и ваше приложение. Вы вызываете функции/методы SQLite через драйвер (в Python, Go, Java, Swift и т. д.), а библиотека читает и пишет данные прямо в файл базы.
Это меняет типичную картину эксплуатации: нет отдельного сервера БД, нет настройки пользователей БД на хосте, нет сетевой конфигурации, нет «поднимите кластер». Есть только ваше приложение и встроенный движок.
Деплой SQLite выглядит предельно просто:
Именно поэтому SQLite так удобно использовать в мобильных приложениях, десктопе и на edge‑устройствах: база живёт там же, где и код.
SQLite лучше всего чувствует себя, когда к файлу базы основной доступ идёт из одного приложения (и часто из одного процесса). Внутри процесса может быть много потоков, транзакции и блокировки поддерживаются, но модель остаётся локальной: файл — общий ресурс.
PostgreSQL и MySQL — это серверы: отдельный сервис, который управляет данными и обслуживает множество клиентов по сети. Это даёт масштабирование по подключениям и записи, централизованное администрирование и доступ из разных машин.
SQLite же — это «БД как часть приложения»: минимум инфраструктуры и быстрый локальный доступ, но без сетевой многопользовательской модели сервера.
SQLite любят не за «магические» функции, а за отсутствие лишней возни. Это база данных, которую можно начать использовать сразу: подключили библиотеку — и работает. Для команды это означает меньше времени на настройку и больше — на продукт.
С SQLite обычно не нужно поднимать отдельный сервер, открывать порты, заводить пользователей, настраивать сеть, права доступа и мониторинг службы. В типичном приложении база просто лежит рядом с ним (или создаётся при первом запуске), а доступ к данным происходит через обычные запросы.
Это особенно ценно там, где «админить» некому: в небольших командах, в стартапах, в учебных проектах, в офлайн‑приложениях.
SQLite хранит данные в одном файле. Для десктопа и мобайла это почти идеальный формат: файл можно положить в поставку, мигрировать вместе с приложением, бэкапить как обычный документ, а в некоторых сценариях — даже отправлять пользователю для диагностики.
В прототипах это ускоряет цикл «идея → проверка»: вы не думаете о развёртывании БД, вы проверяете гипотезу.
Когда нет отдельной службы базы данных, нечему «падать» как самостоятельному сервису: не случится ситуация, где приложение живо, а БД не поднялась после перезагрузки, потеряла конфиг или не стартовала из‑за нехватки места на системном разделе. Конечно, риск переносится на уровень файла и диска — но для небольших продуктов это часто проще контролировать.
SQLite даёт низкую стоимость входа: минимум инфраструктуры, минимум поддержки. А когда проект вырастает, вы уже понимаете реальные требования и можете осознанно перейти на серверную БД — не раньше, чем это действительно нужно.
SQLite любят не только за простоту, но и за то, что она ведёт себя как «настоящая» СУБД там, где это важно: в целостности данных. Даже будучи встроенной библиотекой и одним файлом, SQLite даёт строгие гарантии и предсказуемые сценарии восстановления.
SQLite поддерживает ACID‑транзакции без отдельного сервера и сложной настройки. Это означает, что изменения либо применяются полностью, либо не применяются вообще (атомарность), данные остаются согласованными после каждого коммита (согласованность), параллельные операции не «перемешивают» результаты (изоляция), а сохранённое не пропадает после перезапуска (долговечность).
Для прикладных задач это практично: можно безопасно обновлять несколько таблиц одним действием (например, списать деньги и записать чек) и не бояться «полуполоманных» состояний.
SQLite опирается на журналирование, чтобы переживать неожиданные события: отключение питания, краш процесса, принудительное закрытие приложения. Идея простая: прежде чем менять основной файл базы, SQLite фиксирует, что именно собирается сделать. Если операция оборвалась на середине, при следующем открытии база откатывается или докатывается до корректного состояния.
База — это один файл с хорошо определённым форматом. Его легко копировать, бэкапить, переносить между устройствами и даже разными ОС. Это удобно для локального хранилища в приложениях, тестовых стендов и офлайн‑режима.
В режиме WAL (write-ahead logging) записи идут в отдельный журнал, а читатели продолжают работать с «снимком» данных без постоянных блокировок. В реальных приложениях это снижает задержки при частом чтении и периодических записях (например, лента, каталог, кэш), сохраняя те же ACID‑гарантии — при условии корректной настройки синхронизации и бэкапов под WAL.
SQLite часто ощущается «молниеносной» просто потому, что работает рядом с вашим кодом: нет сетевого round-trip, нет отдельного сервера, нет очередей на стороне БД. Для многих задач это даёт выигрыш, который сложно переоценить — особенно в мобильных приложениях, настольных утилитах и на edge‑устройствах.
Сетевой запрос — это не только вычисление SQL. Это ещё сериализация, шифрование, маршрутизация, ожидание ответа и иногда повторные попытки. Даже «быстрый» запрос к удалённой БД часто проигрывает простому чтению из локального файла.
Когда данные лежат на том же устройстве, где отрисовывается интерфейс, вы уменьшаете цепочку зависимостей. SQLite хорошо подходит для сценариев, где важны быстрые выборки небольших порций данных (поиск, фильтры, списки, кэш), и где ответ должен быть предсказуемым даже без интернета.
Предел скорости обычно определяется не «умом» SQLite, а физикой: скоростью диска/флеш‑памяти, числом fsync, размером страниц, а также конкуренцией за запись. При интенсивных записях узким местом становятся блокировки файла. Режим WAL часто улучшает параллельность чтения и сглаживает задержки, но не превращает SQLite в систему для десятков одновременных писателей.
Главные приёмы простые:
EXPLAIN QUERY PLAN).LIMIT), чтобы не таскать лишнее через приложение.Так SQLite остаётся быстрым «локальным двигателем», пока вы не упираетесь в железо и параллельную запись.
SQLite часто воспринимают как «простую» БД, но её модель конкурентного доступа продумана: читать можно эффективно, а вот запись требует дисциплины. Это не баг, а следствие того, что данные живут в одном файле.
В классическом режиме SQLite допускает параллельные чтения: несколько запросов SELECT могут выполняться одновременно. Запись же ограничена: в каждый момент времени активен только один writer, потому что нужно гарантировать целостность файла.
Отсюда практическое правило: SQLite отлично подходит для «много читаем, мало пишем», но при частых конкурентных INSERT/UPDATE начинаются очереди и ожидания.
Конкуренция бывает двух типов:
На практике помогает простая стратегия: делать транзакции короткими и не держать их «на всякий случай».
Режим WAL (Write-Ahead Logging) меняет картину: писатель пишет не прямо в основной файл, а в журнал. В результате:
Но WAL добавляет нюансы: появляются дополнительные файлы WAL/SHM, а контрольные «сбросы» (checkpoint) нужно учитывать — особенно на устройствах с ограниченным диском.
Самые частые причины блокировок:
busy_timeout или ретраи.Если приложению нужны частые конкурентные записи от многих клиентов, SQLite всё ещё может работать, но обычно требуется пересмотреть модель доступа или архитектуру записи (очередь, батчинг, один «писательский» компонент).
SQLite редко «продают» как отдельный продукт — она просто оказывается внутри приложений там, где нужно надёжное локальное хранилище без отдельного сервера и настройки.
Самый частый сценарий — офлайн‑режим и кэш. Приложение может сохранять ленту, каталог товаров, сообщения, черновики, настройки и пользовательские данные так, чтобы всё работало без сети и мгновенно открывалось при следующем запуске.
SQLite удобна тем, что данные можно хранить структурированно (таблицы, индексы, запросы), а не собирать «зоопарк» из JSON‑файлов. Часто поверх неё используют ORM/обёртки, но в основе остаётся тот же файл базы.
На компьютерах SQLite используют для конфигов, локальных каталогов, истории действий, очередей задач, кеширования результатов поиска. Например, музыкальный плеер хранит медиатеку, а бухгалтерская утилита — локальную копию справочников.
Встраиваемые программы (в том числе на «железе») ценят SQLite за предсказуемость: один файл, минимальные зависимости, простое резервное копирование.
Браузеры и толстые клиенты любят локальные базы для индексов, состояния и служебных данных: история, сохранённые сессии, метаданные, внутренние кэши. Даже если пользователь этого не видит, локальная БД помогает быстро находить и восстанавливать состояние приложения.
На edge‑устройствах SQLite подходит, когда ресурсов мало, а данные нужно держать на устройстве: телеметрия, буферизация перед отправкой в облако, локальные правила/профили, журналы событий. Это практичный компромисс между «просто файлы» и тяжёлой серверной СУБД.
SQLite часто работает как «локальная витрина»: приложение получает данные из API/облака, но показывает их и даёт работать с ними без постоянного подключения. Это снижает задержки, экономит трафик и делает интерфейс отзывчивым — даже если сеть нестабильна.
Практичный подход: хранить локально то, что нужно для быстрого отображения и офлайн‑сценариев (профиль, справочники, последние документы, настройки), а на сервере — «источник истины» и общие данные, требующие совместной работы. Тогда SQLite отвечает за скорость и автономность, а облако — за синхронизацию и общий доступ.
Кстати, этот же принцип часто используют при быстром запуске продукта: сначала делают локальный прототип (в том числе на SQLite), а затем выносят «источник истины» на сервер. В TakProsto.AI такой переход проще планировать заранее: можно быстро собрать интерфейс и логику приложения в формате чата, а когда нагрузка и требования прояснятся — перейти на серверный бэкенд на Go с PostgreSQL (типовой стек платформы), сохранив структуру данных и сценарии.
Хорошее правило: локально — данные, которые можно восстановить из сервера или пересчитать; на сервере — то, что важно не потерять и чем делятся устройства.
Если данные редактируются, полезно хранить рядом метаданные: время изменения, версию, статус отправки. Это упрощает разрешение конфликтов (например, «последняя запись победила» или ручное подтверждение в интерфейсе).
Надёжная схема для офлайна: не пытаться «сразу отправить», а сначала записать действие в локальную очередь/журнал событий (outbox). Фоновый процесс потом отправляет события на сервер, повторяет при ошибках и отмечает успешные.
Такой журнал даёт важный бонус: если приложение закрылось или сеть пропала, действия пользователя не исчезают.
Поскольку база — часть приложения, обновления требуют аккуратных миграций: версионируйте схему, делайте изменения небольшими, добавляйте колонки вместо «ломающих» переделок.
Если миграция может быть долгой, выполняйте её при старте в отдельном шаге и показывайте понятный прогресс — пользователю важнее предсказуемость, чем идеальная структура таблиц.
SQLite отлично работает, пока база «живёт рядом» с приложением и основная нагрузка — чтение или умеренные записи. Но есть ситуации, где ограничения встроенной БД начинают тормозить продукт и команду.
SQLite допускает параллельные чтения, но запись в один файл — узкое место: одновременно активен по сути один писатель. Режим WAL часто улучшает ситуацию, но он не превращает файл в многопользовательскую систему с высокой пропускной способностью на запись.
Типичные сигналы:
SQLite рассчитана на локальный доступ к файлу. Попытка сделать «общую базу по сети» через сетевую файловую систему (NFS/SMB) или общий диск часто заканчивается сюрпризами: нестабильные блокировки, странные ошибки при обрывах связи, риск повреждений при некорректной конфигурации.
Если вам нужен единый источник данных для десятков/сотен клиентов, нормальная схема — серверная БД, где конкуренция и блокировки решаются на уровне сервера, а доступ идёт по протоколу БД.
С SQLite легко начать, но по мере роста продукта появляется «операционка»:
Если всё это приходится строить вокруг одного файла на каждом узле, поддержка быстро становится дороже, чем переход на управляемую серверную БД.
Пора смотреть в сторону PostgreSQL/MySQL или облачного аналога, если:
SQLite остаётся отличным локальным слоем, но когда база превращается в инфраструктурный центр, серверный подход обычно проще и безопаснее в долгую.
SQLite часто воспринимают как «маленькую базу», а значит — «менее серьёзную» по безопасности. На деле она просто устроена иначе: это файл на диске, и многое зависит не от СУБД, а от того, как вы храните и защищаете этот файл.
Базовый уровень защиты SQLite — это механизмы операционной системы: права на файл и каталог, изоляция пользователей, песочницы (на мобильных платформах), шифрование диска. Если приложение запускается с правами, позволяющими читать файл БД, оно его прочитает — SQLite не добавляет «встроенную» модель пользователей и ролей как серверные БД.
Отсюда практическое правило: относитесь к файлу .db как к любому другому чувствительному артефакту. Ограничивайте доступ на уровне ОС, не кладите БД в общие папки, не раздавайте её через сетевые шары, не оставляйте в местах с широкими правами.
Стандартный SQLite не шифрует данные «из коробки». Шифрование обычно решается:
Важно понимать: шифрование файла защищает от чтения «украденного» файла, но не от логики приложения, которое само же его расшифрует при запуске.
Частые проблемы — утечка файла БД, небезопасные бэкапы (попали в облако без шифрования), общий доступ к диску/контейнеру, а также логи и дампы с реальными данными.
Практика, которая почти всегда окупается:
SQLite часто выбирают не только из‑за «одного файла», но и потому, что вокруг него давно сложился практичный набор инструментов. В результате с базой удобно работать и разработчикам, и тем, кто просто сопровождает продукт.
Базовый швейцарский нож — стандартный CLI sqlite3. Он помогает быстро посмотреть схему, выполнить запрос, выгрузить данные:
.schema — увидеть структуру таблиц и индексов.dump — сделать текстовый дамп (удобно для бэкапа и переносов)PRAGMA integrity_check; — проверить целостность файлаЕсли нужен интерфейс «как в Excel, но для таблиц», выручат визуальные браузеры: DB Browser for SQLite, SQLiteStudio, а также IDE вроде DataGrip. Они особенно полезны, когда нужно вручную посмотреть данные пользователя или проверить результат миграции.
Чтобы изменения структуры не превращались в хаос, используйте версионирование схемы. Популярные варианты:
PRAGMA user_version;schema_migrations и записывать применённые миграции.Хорошая миграция должна быть идемпотентной там, где это возможно: CREATE TABLE IF NOT EXISTS, аккуратные проверки существования колонок, а также выполнение пачки изменений в транзакции, чтобы не оставить файл в «полуобновлённом» состоянии.
SQLite отлично подходит для интеграционных тестов: поднятие БД — это создание временного файла.
Практика: в начале теста создать БД в temp‑каталоге, прогнать миграции, затем выполнять сценарии. :memory: тоже быстрый вариант, но он иногда ведёт себя иначе (например, при нескольких соединениях), поэтому файл часто надёжнее.
Типичная «производственная» проблема — SQLITE_BUSY, когда запись ждёт освобождения блокировки. Помогают:
busy_timeout/busy handler;Для диагностики полезно включать логирование SQL на уровне драйвера/обёртки и фиксировать контекст: какой запрос, сколько ждал, какая операция (чтение/запись). Это превращает редкие зависания «непонятно почему» в понятные задачи оптимизации.
SQLite хорош как встроенная база данных и локальное хранилище: один файл, ACID‑транзакции, минимум зависимостей. Но когда проект растёт, полезно понимать, какие варианты закрывают новые потребности — и по каким признакам стоит мигрировать.
Если у вас много одновременных записей, сложные права доступа, несколько сервисов работают с одной БД и важны роли/аудит — серверная СУБД обычно проще и предсказуемее. PostgreSQL и MySQL лучше подходят для многопользовательских сценариев, где запись идёт постоянно и параллельно.
SQLite с режимом WAL сильно улучшает конкуренцию чтения/записи, но всё равно упирается в модель «одна запись за раз». На сервере параллельность и изоляция транзакций решаются на другом уровне.
Когда данные — это «ключ → значение» (сессии, кэш, счётчики, токены), key‑value системы выигрывают по скорости и простоте. Но у них обычно меньше возможностей для сложных запросов и джойнов, а транзакции и консистентность могут отличаться по модели. Это не «замена SQLite один в один», а другой класс инструментов.
Если вы делаете отчёты, агрегации, сканируете большие объёмы и вам важнее аналитика, чем OLTP‑операции, DuckDB часто удобнее. Это тоже встраиваемый подход, но оптимизированный под колоночные запросы и анализ, а не под частые мелкие изменения строк.
Выбирайте альтернативу, исходя из:
Практичный путь часто гибридный: SQLite остаётся локальным кэшем/офлайн‑слоем, а серверная БД становится «источником истины». Если вы планируете миграцию, полезно заранее фиксировать схему и точки синхронизации — это снизит риск, когда требований станет больше, чем может дать SQLite.
В этом контексте TakProsto.AI удобно использовать как быстрый способ собрать рабочий прототип (в том числе офлайн‑сценарии с SQLite), а затем — без болезненной пересборки процесса разработки — перейти к «серверной» архитектуре: React на фронтенде и Go + PostgreSQL на бэкенде. При необходимости можно экспортировать исходники, включить деплой/хостинг, подключить домен, а также пользоваться снапшотами и откатом — это помогает безопасно переживать как миграции схемы, так и переход между типами хранилищ, особенно в небольших командах.
SQLite — это встраиваемая СУБД в виде библиотеки, которая работает внутри процесса приложения и хранит данные обычно в одном файле. Поэтому её не нужно поднимать как отдельный сервис, но при этом вы получаете SQL, индексы и транзакции.
«Embedded» означает, что SQLite подключается как библиотека и выполняет запросы прямо в вашем приложении. «Serverless» — что нет отдельного сервера БД (процесса, порта, пользователей, сетевых подключений); база живёт локально как файл, а не как сетевой сервис.
Потому что это дешёвый и предсказуемый способ получить локальное хранилище: минимальная настройка, быстрый доступ без сети и переносимость файла.
Чаще всего SQLite используют как:
SQLite даёт ACID‑транзакции: изменения либо применяются целиком, либо откатываются; база остаётся согласованной даже при сбоях.
Практический совет: объединяйте связанные изменения в одну транзакцию (BEGIN … COMMIT), чтобы не получить «полуприменённые» данные (например, списали деньги, но не записали чек).
WAL (write-ahead logging) — режим, в котором запись идёт в отдельный журнал, а не сразу в основной файл. Обычно это:
Нюансы: появляются файлы -wal и -shm, а бэкапы и обслуживание (checkpoint) нужно делать с учётом WAL.
Классическая модель SQLite — много читателей, один писатель: параллельных SELECT может быть много, а записи конкурируют за один файл.
Чтобы уменьшить проблемы:
busy_timeout) или ретраи;SQLite часто очень быстра локально, но упирается в диск/флеш и стоимость частых fsync при записи.
Практика ускорения:
EXPLAIN QUERY PLAN);LIMIT.Самый частый «ускоритель» — перестать делать тысячи мелких коммитов.
Пока файл базы открыт, простой «копипаст» может быть некорректным (особенно в WAL). Безопасные варианты зависят от платформы/драйвера, но общие правила такие:
-wal, -shm).Проверка целостности после бэкапа: .
SQLite не предназначена для «общей базы по сети» через NFS/SMB: блокировки и сбои сети могут приводить к ошибкам и рискам повреждения.
Если нужен единый источник данных для многих клиентов, обычно правильнее:
Сигналы, что пора на серверную БД:
Часто лучший вариант — гибрид: SQLite остаётся локальным кэшем/офлайн‑слоем, а серверная БД — «источником истины».
PRAGMA integrity_check;