Разберём, почему управление состоянием так сложно: источники данных, синхронизация, асинхронность, перерисовки и выбор подходящего инструмента.
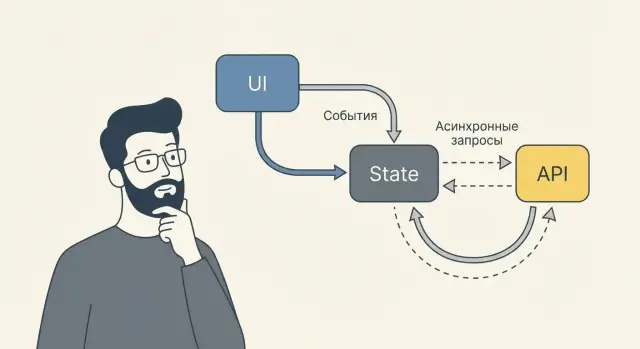
Состояние (state) — это данные, которые описывают «что сейчас происходит» в интерфейсе и из‑за которых экран должен выглядеть по‑разному. Проще говоря, состояние отвечает на вопрос: «в каком режиме находится UI прямо сейчас?» Оно меняется из‑за действий пользователя, событий системы или ответов сервера.
Пропсы — это данные, которые компонент получает извне от родителя. Сами по себе они не «управляются» внутри компонента: компонент их лишь отображает.
Вычисляемые (derived) значения — это то, что можно однозначно посчитать из уже имеющихся данных. Например, fullName = firstName + lastName, «кнопка активна, если все поля заполнены», «итоговая сумма = корзина + доставка». Такие значения обычно не нужно хранить отдельно: их лучше вычислять на лету, чтобы не ловить рассинхронизацию.
Если компонент всегда рисует одно и то же при одних и тех же входных данных, то ему достаточно пропсов и вычислений. Типичные примеры: статический блок текста, карточка товара, которая получает объект товара через пропсы, или кнопка с фиксированной логикой.
Чем меньше лишнего состояния вы создаёте, тем меньше точек, где UI может «поехать».
Управление состоянием часто выглядит как простая задача: «хранить данные и обновлять UI». На практике сложность появляется не из‑за одной большой проблемы, а из‑за десятков маленьких, которые начинают конфликтовать друг с другом по мере роста приложения.
Данные о том, что происходит в приложении, редко лежат в одном месте. Есть состояние формы, выделенный элемент в списке, права пользователя, уведомления, кэш запросов, URL‑параметры, данные из localStorage. Когда один и тот же факт дублируется (например, «пользователь авторизован») в двух местах, они неизбежно расходятся.
Типичный симптом: интерфейс показывает одно, а кнопка ведёт себя иначе — потому что разные части UI опираются на разные копии состояния.
Компоненты монтируются и размонтируются, а пользовательский поток продолжается. Нужны данные, которые переживают переходы между экранами, возврат назад, обновление страницы или повторный вход. Чем дольше живёт состояние, тем больше вопросов:
Ошибки часто проявляются не на «счастливом пути», а когда пользователь быстро кликает, теряет сеть, открывает два таба, сворачивает приложение, возвращается через час, или получает ошибку с сервера. Такие сценарии трудно воспроизвести, поэтому проблемы копятся и неожиданно выстреливают в проде.
Каждый новый экран добавляет не одну переменную, а новые связи: кто с кем синхронизируется, какие действия возможны в каком порядке, что должно обновиться автоматически, а что — нет. В итоге количество возможных состояний и переходов растёт быстрее, чем команда успевает держать это в голове — и «простая» логика превращается в систему правил и исключений.
Когда говорят «управление состоянием», часто имеют в виду одну абстрактную сущность. На практике состояние живёт в разных местах — и именно выбор «где хранить» определяет сложность, связанность компонентов и количество багов.
Локальное состояние — это данные, которые важны только внутри одного компонента или небольшого дерева и не нужны остальной части приложения.
Типичные примеры: открыт/закрыт dropdown, значение в поле ввода до отправки, выбранная вкладка, временные флаги вроде isEditing. Плюс локального состояния в том, что оно близко к месту использования: меньше зависимостей, проще тестировать и рефакторить.
Глобальное состояние имеет смысл, когда данные:
Важно не путать удобство доступа с необходимостью глобальности. Если состояние глобальное «на всякий случай», вы получаете скрытые связи: изменение в одном месте неожиданно ломает другое.
Отдельный класс — серверное состояние: результаты запросов, статус загрузки, ошибки, повторные попытки, пагинация, кэш и его инвалидирование. Эти данные формально «про приложение», но источник правды — сервер.
Ключевая мысль: не пытайтесь моделировать серверные данные как чистое клиентское глобальное состояние вручную. У серверного состояния свои правила: устаревание, гонки запросов, оптимистичные обновления.
UI‑состояние описывает, как отображать (модалки, фокусы, фильтры, сортировки). Бизнес‑состояние описывает, что есть (корзина, выбранный тариф, заполненная анкета). Смешивание часто приводит к «комбайнам», где рядом лежат и данные, и флаги интерфейса, и сетевые статусы — и это трудно сопровождать.
Практичное правило: храните состояние как можно ближе к месту использования, но не ближе, чем позволяет совместное использование.
Спросите себя:
Если ответы ведут к «много мест, долгоживущие, источник правды, не сервер» — вероятно, оправдан глобальный стор. Если «только тут и сейчас» — оставляйте локально. Если «данные с сервера» — мыслите категориями кэша и синхронизации, а не просто «положить в глобальное состояние».
Состояние редко меняется «одним нажатием». Пользователь кликает, UI запускает обработчики, уходит запрос, приходит ответ, параллельно срабатывают таймеры и эффекты. Если порядок этих событий не зафиксирован правилами, вы получаете гонки — ситуации, где итог зависит от того, кто успел первым.
Типичный пример: кнопка «лайк» и автоматическое обновление карточки по таймеру меняют одно поле liked. Если «обновление карточки» приходит позже, оно может перезаписать локальное действие пользователя устаревшим значением.
Практика: заранее решите, кто «главнее» — действие пользователя или обновление с сервера. Часто полезно вводить версию/время изменения или правило «последнее локальное действие удерживает приоритет до подтверждения сервера».
Быстрые клики запускают цепочку одинаковых запросов. Один ответ приходит поздно и откатывает UI назад.
Минимальные защиты:
requestId.Важно: «отмена» — это тоже событие. Если вы отменили запрос, состояние должно явно перейти в понятный статус (например, idle, а не «вечная загрузка»).
Дебаунс откладывает выполнение, троттлинг ограничивает частоту. Оба меняют причинно‑следственную связь: пользователь ввёл текст сейчас, а состояние «зафиксировалось» позже. Если в этот промежуток вы показываете подсказки, делаете автосохранение или валидацию — легко получить конфликт «старых» и «новых» данных.
Помогает простая схема: описать состояния (idle/loading/success/error), события (click, response, cancel) и правила переходов. Если событие приходит «не вовремя», у вас должен быть ответ: отклонить, поставить в очередь, объединить или сделать его источником истины.
Лишние обновления интерфейса редко выглядят как «большая проблема» в момент, когда вы их создаёте. Чаще это цепочка мелких решений: «давайте положим это в глобальное состояние», «пусть компонент подпишется на весь объект», «так проще передать пропсы». Через месяц оказывается, что любое нажатие кнопки дёргает половину страницы.
Главный источник — слишком широкие зависимости. Компонент читает большой кусок состояния, хотя реально ему нужна пара полей. Любое изменение внутри объекта (или создание нового объекта при обновлении) делает так, что сравнение по ссылке проваливается, и компонент обновляется.
Похожая история — когда вы храните в состоянии «производные» данные (например, отфильтрованный список), а потом обновляете и исходник, и производное. Это удваивает количество обновлений и создаёт рассинхронизацию.
Мемоизация (memo/useMemo/useCallback) полезна, когда вы уже сузили зависимости, но есть действительно дорогие вычисления или тяжёлые поддеревья UI.
Она становится костылём, если ей пытаются «лечить» архитектуру: компонент всё ещё подписан на огромный объект, а вы добавляете memo повсюду. Итог — сложнее код, больше когнитивной нагрузки, а прирост производительности нестабилен.
Если в состоянии лежат вложенные структуры, любое точечное изменение может менять ссылки на большие поддеревья. Нормализация (хранение сущностей по id) уменьшает область изменений.
Селекторы (в том числе мемоизированные) позволяют:
Один «универсальный стор» часто превращается в точку, где пересекаются несвязанные события. Лучше дробить:
Так вы снижаете радиус обновлений: изменения затрагивают только тех подписчиков, которым это действительно нужно.
Когда приложение растёт, проблема состояния превращается из «где хранить данные» в «кто имеет право их менять». Без границ изменения начинают «протекать» между фичами: каталог знает слишком много о корзине, профиль напрямую правит авторизацией, а любые правки ломают чужие экраны.
Полезное правило: каждый домен владеет своим состоянием и предоставляет наружу только публичные операции. Например, модуль корзины может отдавать addItem/removeItem/clear, но не «раскрывать» внутреннюю структуру так, чтобы другой модуль мог мутировать её напрямую.
Практически это выглядит как:
Состояние масштабируется лучше, когда у команды есть единые правила:
/features/cart, /entities/user);setUser, logout, applyPromo);Это снижает количество «магии» и упрощает ревью: по структуре видно, кто отвечает за изменения.
Изоляция — не про запрет общения, а про контролируемые точки интеграции. Корзина может зависеть от каталога через идентификаторы товаров, но не через копирование целых объектов. Профиль может влиять на цены через статус пользователя, но через явное поле/запрос, а не через чтение чужого внутреннего стора.
Чтобы менять архитектуру постепенно, вводите прослойку: сначала зафиксируйте публичный API модуля, затем перенесите внутреннюю реализацию под него. Старые места пусть продолжают вызывать те же операции, пока вы шаг за шагом переносите логику. Так рефакторинг становится серией небольших безопасных изменений, а не большим рисковым проектом.
Предсказуемость в управлении состоянием появляется не «сама», а как результат договорённостей: что можно менять, где можно менять и как фиксировать причины изменений. Чем меньше свободы у произвольных мутаций, тем проще объяснить баг, воспроизвести его и исправить.
Иммутабельность означает: мы не «правим» существующий объект состояния, а создаём новый. Это даёт два практических бонуса: проще сравнивать версии (например, по ссылке) и легче откатывать/воспроизводить цепочку изменений.
На практике помогает правило: не изменяйте вложенные поля напрямую. Вместо state.user.name = ... создавайте новую структуру на нужной глубине (или используйте инструменты, которые делают это безопасно).
Два подхода:
USER_RENAMED), а редьюсер решает «как меняется состояние». Это ограничивает точки записи и делает изменения однородными.Если нужен компромисс, используйте строгие границы: например, разрешайте менять состояние только внутри одного слоя (store/модель), а UI — только читает и отправляет события.
Единый поток данных — это когда изменение проходит по понятному маршруту: UI → событие → обновление состояния → перерисовка. Тогда можно логировать события, собирать историю и отвечать на вопрос «почему это значение стало таким?».
Побочные эффекты (запросы, таймеры, запись в storage) лучше выносить из «чистой» логики обновления состояния. Правило простое: редьюсер/функция обновления должна быть детерминированной, а эффекты — жить рядом, но отдельно и запускаться явно (по событию). Так исчезают неожиданные изменения «из ниоткуда» и уменьшается число трудноуловимых багов.
Серверное состояние — это данные, которые живут «где-то там»: в базе, в API, в кеше CDN. Фронтенд лишь запрашивает, отображает и иногда временно переопределяет их. Сложность начинается с того, что эти данные по природе асинхронны: они могут прийти позже, частично, в другом порядке, а иногда — не прийти вообще.
Почти любой интерфейс кэширует ответы: в памяти, в localStorage, в сервис‑воркере или внутри библиотек. Кэш ускоряет UI, но создаёт второй источник правды.
Главный вопрос: когда данные считаются устаревшими? Если вы показываете список заказов, обновляете один заказ и забываете инвалидировать список — пользователь увидит «старую реальность». Поэтому нужны понятные правила: какие запросы инвалидируются после мутаций, какие обновляются точечно, а какие можно «дотянуть» фоновым рефетчем.
Сеть ненадёжна: запрос может упасть, зависнуть, вернуться с 500 или таймаутом. Наивная обработка ошибок («показать alert и всё») быстро ломается.
Практичнее заранее определить:
Чтобы интерфейс казался быстрым, часто применяют оптимистичное обновление: UI меняется сразу, а запрос на сервер идёт «в фоне». Если сервер отказал — нужно аккуратно откатить изменение и синхронизировать кэш.
Критично не смешивать оптимистику с локальными «костылями» вроде ручного мутирования глобального стора: лучше иметь единый механизм, который умеет снапшоты, откат и повторную синхронизацию.
Библиотеки вроде TanStack Query (React Query) и SWR берут на себя большую часть серверного состояния: кэш, stale‑таймеры, инвалидацию, рефетчи, ретраи, отмену запросов и оптимистичные мутации. Это помогает отделить «данные с сервера» от «состояния интерфейса» и заметно упрощает фронтенд‑архитектуру в местах, где Redux/Context начинают разрастаться.
Инструмент управления состоянием — это не «модный выбор», а договорённость о том, как команда будет менять данные, искать причины багов и масштабировать приложение. Чаще всего вам не нужен «самый мощный» вариант — нужен самый понятный под ваши сценарии.
Смотрите не на популярность, а на ответы на вопросы:
Context отлично подходит для сквозных настроек: тема, локаль, текущий пользователь, feature flags. Боль начинается, когда в контекст складывают «всё подряд»: частые изменения заставляют перерисовываться много компонентов, а структура зависимостей становится неочевидной. Context — это канал доставки, а не полноценная архитектура.
Redux хорош там, где важны прозрачные изменения и воспроизводимость: события (actions), единый стор, понятные редьюсеры, удобная отладка. Redux Toolkit снижает количество шаблонного кода, но «цена» остаётся: нужно соблюдать договорённости, проектировать слайсы, следить за нормализацией данных и не смешивать в сторе всё подряд.
MobX приятен скоростью разработки: изменили поле — UI обновился. Это удобно для сложных форм и интерактивных экранов. Риск — неявные зависимости: бывает сложнее понять, почему компонент обновился, и где именно меняется значение. В больших командах это требует особенно аккуратных правил.
Лёгкие сторы (например, Zustand) подходят, когда нужно простое глобальное состояние без церемоний: несколько независимых хранилищ, минимум обвязки, быстрый старт. Обычно это хороший выбор для средних приложений, если вы заранее договорились о структуре сторов и границах ответственности.
В экосистеме Vue современный стандарт — Pinia: модульные сторы, хорошая типизация, меньше лишней формальности. Vuex встречается в легаси‑проектах; миграция на Pinia часто упрощает поддержку.
Главное правило: серверное состояние не пытайтесь «притворить» глобальным UI‑состоянием. Для запросов, кэша и инвалидаций обычно лучше специализированные решения (например, React Query), а стор оставить для клиентской логики и UI.
Если вы собираете продукт быстро (лендинги, админки, внутренние сервисы), сложность state management часто проявляется уже на уровне «простых» вещей: формы, роли доступа, статусы загрузки, отмены запросов и предсказуемые переходы между состояниями.
В TakProsto.AI (vibe‑coding платформа для создания web/server/mobile приложений через чат) полезно начинать с явной модели: проговорить в диалоге сущности, статусы (idle/loading/success/error), источники правды (локально/глобально/сервер), а затем зафиксировать это в «planning mode». Дополнительно помогают снапшоты и rollback: когда эксперимент с архитектурой состояния пошёл не туда, проще откатиться к стабильной версии, чем «распутывать» цепочки эффектов.
Ошибки в управлении состоянием редко выглядят как «сломалась кнопка». Чаще это дрожащий UI, пропадающие данные, бесконечные загрузки и баги, которые воспроизводятся «через раз». Ниже — несколько антипаттернов, которые почти гарантированно приводят к таким эффектам.
Когда в глобальное состояние складывают открытость выпадашек, текущий hover, текст в инпуте и «в какой вкладке мы сейчас», стор разрастается и начинает жить своей жизнью.
Побочные эффекты:
Например, список товаров хранится и в компоненте, и в глобальном сторе, и ещё как результат запроса. Из‑за этого появляются рассинхронизации: обновили в одном месте — забыли в другом.
Хороший маркер проблемы — «костыли синхронизации»: эффекты вида «если A поменялось, обнови B», которые множатся и ломаются от любой правки.
Серверное состояние (данные из API) имеет свой жизненный цикл: загрузка, ошибка, кэш, инвалидирование. Если его обновлять «как обычные переменные UI» (например, вручную мержить ответы, хранить копии и патчить их в разных местах), легко получить:
Когда изменение одного поля запускает эффект, который меняет другое поле, которое запускает третий эффект, система превращается в домино. Итог — циклы, зависания и баги, зависящие от порядка событий.
Набор булевых флагов вроде isLoading, isFetching, isRefreshing, isDirty, isValid, isBlocked быстро начинает противоречить сам себе. В какой-то момент возможны состояния, которые «не должны случаться», но случаются.
Лучше моделировать состояние явно: статус (например, idle/loading/success/error) + данные + ошибка, и чёткие правила переходов.
Хорошая архитектура состояния начинается не с выбора Redux/MobX/React Query, а с ясной модели данных и правил. Ниже — практичный чек‑лист, который помогает снизить количество «магии» и неожиданных багов.
Опишите, какие данные существуют в приложении и для каждого пункта ответьте:
Удобный формат — таблица «сущность → владельцы → точки чтения/записи → срок жизни». Такая карта быстро показывает, что можно оставить локальным, а что действительно требует общего доступа.
Инварианты — это условия, которые всегда должны быть верны (например: «выбранный фильтр должен существовать в списке доступных»). Зафиксируйте:
Чем раньше это описано, тем проще отлавливать ошибки не в UI, а в логике.
Решите, как вы выражаете изменения:
userClickedSave),saveProfile),Важно: договоритесь о нейминге и о том, где живут вычисления (в селекторах/хуках, а не размазаны по компонентам).
Для каждой загрузки/операции заранее заложите: loading, success, error, empty. Опишите поведение при частичном успехе, ретраях, отмене запроса и при устаревших данных.
Состояние меняется вместе с продуктом. Заранее решите:
Если этот чек‑лист пройден, выбор библиотеки станет вторичным — вы уже знаете, что именно нужно хранить и как оно должно меняться.
Когда состояние начинает «жить своей жизнью», проблема редко в одном баге. Обычно не хватает прозрачности: непонятно, кто изменил данные, когда, почему и какой эффект это дало в UI. Поддержка становится проще, если заранее вложиться в инструменты наблюдения и правила фиксации знаний.
Хорошая отладка — это не «поставить breakpoint», а быстро восстановить цепочку причин.
cart_updated, profile_loaded, payment_failed) с корреляционным id. Это помогает связывать UI‑симптомы с серверными событиями.Тесты должны ловить регрессии именно в правилах изменения состояния.
Короткий документ на 1–2 страницы часто полезнее десятка комментариев в коде:
Можно оформить как /docs/state-map или раздел в /blog/engineering-handbook.
Добавьте минимальный набор сигналов: частота ошибок запросов, время до готовности данных, количество повторных загрузок, неожиданные «пустые экраны». Свяжите фронтенд‑логи с ошибками и сессиями пользователей — тогда «плавающие» баги перестают быть мистикой и превращаются в воспроизводимые кейсы.
Лучший способ понять возможности ТакПросто — попробовать самому.