Почему в практической безопасности важнее модели угроз, человеческий фактор и стимулы, чем модные «крипто»-термины. Разберём подход Шнайера на примерах.
Практическая безопасность по Брюсу Шнайеру — это не спор о том, «какой алгоритм шифрования самый правильный», а разговор о том, как реально ломают системы и почему многие провалы происходят не из‑за слабой криптографии.
Вокруг безопасности легко построить витрину: шифрование, «нулевое доверие», «военный уровень защиты». Но атака часто идёт там, где нет магии: через настройки по умолчанию, плохие процессы, фишинг, доступы «на всякий случай», забытые интеграции и экономию на проверках.
Шнайер последовательно продвигает мысль: безопасность — это управление рисками в системе, а не набор модных технологий. Сильная криптография может быть внутри, но итог всё равно будет слабым, если злоумышленнику проще купить доступ, обмануть сотрудника или воспользоваться ошибкой в процессе.
Брюс Шнайер — известный исследователь и популяризатор прикладной безопасности, автор книг и статей о том, как думать про угрозы, доверие и стимулы. Его подход ценят за приземлённость: меньше героизма, больше здравого смысла и проверяемых допущений.
Материал даст рамку принятия решений и набор вопросов, которые помогают:
Для продуктовых команд, разработчиков, специалистов по безопасности и руководителей — всех, кому важно принимать решения про риски, сроки и бюджет без лишней терминологии и самообмана.
Частая ошибка — говорить о безопасности так, будто это свойство одной технологии: «у нас AES», «пароли захешированы», «мы используем TLS». В подходе Брюса Шнайера безопасность — это управление риском: какие неприятные события могут случиться, насколько они вероятны и как дорого обойдутся.
Абсолютной («идеальной») защиты нет; есть осознанный выбор, какие риски снижать и какой ценой.
Алгоритм может быть криптографически стойким, но реальная система включает людей, процессы и инфраструктуру: регистрацию, восстановление доступа, хранение ключей, админ‑панели, логи, поддержку, интеграции.
Там, где криптография работает математически, атаки на систему часто работают организационно. Например, если злоумышленник получил доступ к почте пользователя, он может сбросить пароль и войти легально. В этот момент «сильное шифрование» внутри продукта не спасает: проблема не в слабом алгоритме, а в том, что управление аккаунтом (аутентификация, восстановление, уведомления, защита от подмены SIM/почты) оказалось слабым звеном.
Спрашивать «насколько это стойко?» без контекста — всё равно что выбирать замок, не зная, что вы защищаете и от кого. Для одних продуктов ключевой риск — захват аккаунтов и мошенничество, для других — утечка персональных данных, для третьих — саботаж со стороны инсайдера.
Поэтому полезная формулировка звучит так: какой риск мы снижаем этой мерой, какую атаку она затрудняет и что остаётся уязвимым. Именно так безопасность перестаёт быть набором «правильных» алгоритмов и становится целостной системой решений.
Начинать практическую безопасность полезно не с «самых страшных атак» и не с выбора модных технологий, а с ясности: что именно вы защищаете и зачем. У Шнайера безопасность — это про управление риском, а риск всегда привязан к ценности активов и допустимому ущербу.
Активы — это не только «данные в базе». Для продукта обычно важны:
Важно назвать активы «человеческим» языком, чтобы бизнес и команда одинаково понимали ставку.
Перед любыми мерами защиты ответьте письменно (хотя бы на одну страницу):
Что защищаем? (конкретные активы и процессы)
От кого? (типы нарушителей, их возможности — без фантазий)
Какой ценой? (деньги, время команды, влияние на UX и скорость релизов)
Какой ущерб допустим? (порог, после которого инцидент становится «катастрофой»)
Эти ответы сразу задают рамки: иногда «идеальная защита» просто дороже, чем потенциальный ущерб.
Критерий успеха в безопасности — не «ноль уязвимостей», а приемлемый риск для конкретного продукта. Его формируют:
Практичный ориентир: сформулируйте 3–5 измеримых условий «достаточно безопасно» (например, допустимый простой, максимальная сумма мошенничества в месяц, время обнаружения инцидента, обязательные уровни доступа). Это станет опорой для последующих решений — от приоритизации до процесса релизов.
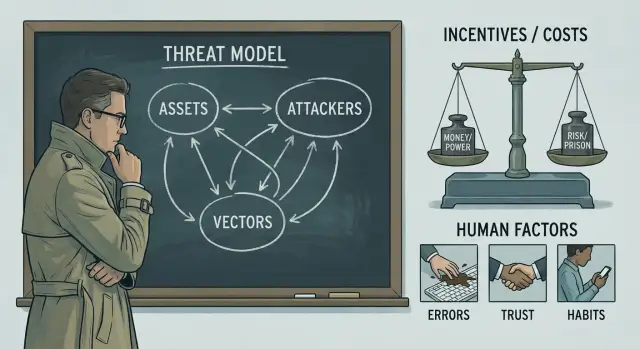
Модель угроз у Шнайера — это не «документ ради документа», а быстрый способ договориться: что мы защищаем, от кого и какими мерами. Хорошая новость: чтобы получить пользу, не нужно рисовать сложные диаграммы и собирать комитет.
Достаточно описать четыре вещи:
Чтобы не утонуть в фантазиях, удобно начинать с простых классов атакующих:
Не усложняйте: запишите угрозы списком и оцените их на грубом уровне.
| Угроза | Вероятность | Ущерб | Приоритет |
|---|---|---|---|
| Подбор паролей к аккаунтам | средняя | высокий | высокий |
| Утечка через подрядчика | низкая | высокий | средний |
| Ошибки в настройке прав доступа | высокая | средний | высокий |
Важно: цель таблицы — выбрать 3–5 действий на ближайший цикл, а не «закрыть всё».
Моделирование угроз без владельца решения и сроков превращается в теорию. Для каждой меры сразу фиксируйте: кто отвечает (роль/имя), что именно меняем и к какому спринту/дате должно быть сделано. Тогда модель угроз становится рабочим инструментом продукта, а не разовым мероприятием.
Когда команда обсуждает безопасность, разговор часто уходит в «самое страшное»: шпионов, нулевые дни, «нас обязательно взломают». Проблема в том, что страшное не равно вероятное.
Практический подход Шнайера предлагает смотреть на риск как на произведение вероятности и ущерба — и работать с тем, что реально может произойти и реально больно ударит по продукту.
Например, целевая атака на руководителя может звучать драматично, но если у вас небольшой B2B‑сервис и нет уникальных данных, шанс именно такой атаки может быть низким. Зато банальные сценарии — повторное использование паролей, фишинг, утечки через публичные ссылки, ошибки в правах доступа — случаются постоянно и дают измеримый ущерб.
Вместо чисел «0,37» и «1,8%» полезнее договориться о простых уровнях. Это быстрее, понятнее и честнее.
Можно зафиксировать правило: если спорите больше 10 минут — ставьте «средняя» и запишите, что нужно уточнить.
Любая модель неполна: у вас нет всех данных об атакующих и будущих уязвимостях. Поэтому полезно явно прописывать:
На выходе должен быть короткий перечень 5–10 рисков с понятными действиями. Пример формата:
Такой список удобно «закрывать» задачами в спринтах, а не обсуждать безопасность как абстрактную вечную проблему.
Люди почти всегда выбирают удобство, а не «идеальную безопасность». И это не недостаток пользователей — это свойство любой реальной системы.
Практическая безопасность по Шнайеру начинается с признания: если защита требует постоянной внимательности и дисциплины, её будут обходить — или она будет ломаться.
Самые типичные ошибки повторяются из продукта в продукт:
Важно: эти ошибки предсказуемы — значит, их можно учитывать в модели угроз и проектировании.
Политика «запретить» часто приводит к обходным путям: люди ищут самый короткий маршрут к цели, даже если он небезопасен. Эффективнее сделать безопасный путь самым простым:
Хороший UX снижает риск не хуже технических контролей:
Когда система спроектирована так, что обычное поведение пользователя остаётся безопасным, человеческий фактор перестаёт быть «виноватым» и становится частью защиты.
Шнайер постоянно возвращает нас к неприятной мысли: атакуют там, где дешевле, а защищают там, где выгоднее. Уязвимости часто появляются не из‑за «плохих инженеров», а из‑за экономических условий вокруг продукта: кто получает выгоду, кто несёт потери и кто принимает решения.
В одной системе участвуют как минимум четыре стороны: пользователь, бизнес, подрядчик/поставщик и злоумышленник.
Пользователь хочет удобства и скорости. Бизнес — роста, выручки и быстрых релизов. Подрядчик может быть заинтересован закрыть работу по ТЗ и минимизировать часы поддержки.
Злоумышленник ищет максимальную отдачу при минимальных затратах: если фишинг дешевле взлома, будут фишить; если проще атаковать слабый процесс, а не шифрование, ударят по процессу.
Если штрафы и репутационные потери за утечки размыты или «не ощущаются» командой, безопасность почти всегда проигрывает задачам, за которые прямо платят.
Когда KPI завязаны на скорость релизов и количество фич, а цена инцидента наступает «потом» и достаётся другим людям, появляется стимул отложить исправления, упростить проверки и оставить технический долг.
Экономия на поддержке и мониторинге тоже создаёт дыру: проблему заметят поздно, а значит злоумышленник получит больше времени.
Назначайте владельцев рисков и делайте последствия видимыми: кто принимает решение — тот и отвечает за принятый риск.
Закрепляйте процессы: минимальные проверки перед релизом, обязательный разбор инцидентов без поиска виноватых, приоритет исправлений по риску.
И, наконец, бюджет: безопасность без ресурсов превращается в просьбу «делайте лучше». Деньги и время — это язык, на котором стимулы реально меняются.
Криптография — важный инструмент, но она решает довольно узкий класс задач: конфиденциальность (чтобы данные не прочитали посторонние) и целостность (чтобы данные нельзя было незаметно подменить). Иногда ещё — аутентичность (доказать, кто именно подписал сообщение).
Почти всё остальное — это уже про процессы, доступы, стимулы и ошибки людей.
Фразы вроде «у нас AES‑256», «всё на TLS», «zero‑knowledge», «военное шифрование» звучат убедительно, но сами по себе не отвечают на главный вопрос: от кого защищаемся и что именно пытаемся предотвратить.
Если злоумышленник может получить доступ администратора, украсть ключи, заставить пользователя отдать код из СМС или забрать резервные копии — выбор «модного алгоритма» уже не спасает.
Компания может честно хранить данные «зашифрованными AES», но держать ключ в том же облачном аккаунте без жёстких ролей и журналирования. Или делать бэкапы базы в открытый бакет. В итоге атакующему не нужно «ломать крипту» — достаточно добыть ключ или копию данных.
Поэтому практичная криптография начинается не с алгоритма, а с ответов на вопросы выше и привязки к вашей модели угроз (см. /blog/model-ugroz).
Практическая безопасность удобнее всего проявляется на конкретных историях. Один и тот же продукт может быть «идеально защищён» на бумаге и при этом уязвим в реальных точках входа: там, где есть люди, поддержка, интеграции и данные, разлетевшиеся по логам.
Если модель угроз говорит, что злоумышленник чаще крадёт доступ через пользователя, то фокус смещается с «усилить пароль» на «сломать цепочку после кражи». Две типовые меры:
Важно: 2FA не спасает от перехвата активной сессии, поэтому в приоритизации часто выше стоят контроль сессий и обнаружение аномалий.
Даже сильная криптография бессмысленна, если аккаунт можно вернуть через поддержку по слабой проверке личности. В модели угроз это отдельный «канал атаки», и для него нужны свои барьеры:
Интеграции часто получают «вечные» ключи и широкие права — потому что так проще. Практический подход требует обратного:
Логи, трекинг и отчёты нередко становятся «теневым хранилищем» персональных данных и токенов. Здесь помогает простая дисциплина:
Эти сценарии полезны тем, что превращают безопасность из абстракции в список проверяемых решений — и показывают, где защита ломается чаще всего.
Даже хорошие меры защиты иногда не срабатывают: потому что люди ошибаются, атаки меняются, а сложные системы дают сбои. Практический подход по Шнайеру здесь простой: дешевле заранее подготовить обнаружение и реакцию, чем потом неделями расследовать «как так получилось» без данных и плана.
Предотвращение снижает вероятность, но реакция снижает ущерб. Если вы не видите, что происходит, вы платите дважды: за инцидент и за слепое восстановление.
Поэтому минимальная «страховка» — это не ещё один барьер, а способность быстро понять, что случилось, ограничить масштаб и вернуться в норму.
В большинстве продуктов достаточно базового комплекта:
Заранее определите роли и контакты: кто дежурит, кто принимает решение об отключении функции, кто общается с клиентами и партнёрами, кто фиксирует таймлайн.
Нужны критерии эскалации: например, затронуты персональные данные, есть признаки компрометации админ‑аккаунта, инцидент повторяется или растёт по масштабу.
Разбор должен отвечать на вопросы «что позволило случиться» и «как уменьшить риск/ущерб в следующий раз». Итог — конкретные улучшения в продукте и процессах: новые алерты, уточнение прав доступа, изменения UX (чтобы снижать ошибки), и обновлённый план реагирования.
Внедрение «практической безопасности» в продукте — это не разовый воркшоп и не документ ради галочки. Это привычка регулярно принимать решения о рисках так же, как вы принимаете решения о фичах, сроках и качестве.
После короткой сессии по модели угроз важно сразу «приземлить» выводы в бэклог. Для каждой приоритетной угрозы зафиксируйте:
Хороший критерий готовности проверяем: «появился алерт при X», «пользователь видит подтверждение при Y», «запрос без прав возвращает отказ», а не «усилить безопасность».
Отдельно полезно закрепить техническую дисциплину релизов. Например, в TakProsto.AI (виб‑кодинг платформа для создания веб, серверных и мобильных приложений через чат) командам удобно использовать planning mode для фиксации допущений и границ модели угроз, а также снапшоты и rollback — чтобы безопаснее выкатывать изменения и быстрее откатываться при подозрении на инцидент. Это не заменяет меры защиты, но уменьшает цену ошибки в продакшене.
Почти всегда есть цена: дополнительные шаги для пользователя, время разработки, нагрузка на поддержку. Обсуждайте это прямо на планировании, не пряча под общими словами.
Удобный приём — формулировать варианты: минимум, разумный уровень, максимум, и рядом указывать влияние на метрики продукта и оценку затрат.
Если разговор упирается в бюджет, зафиксируйте предпосылки и вернитесь к ним при пересмотре планов (в том числе на /pricing, если у вас есть привязка затрат к тарифам).
Чтобы подход жил, оставьте лёгкие следы, которые реально перечитывают:
Если у команды есть правила публикаций и внутреннего обмена знаниями, заведите единое место и политику обновлений (например, в базе знаний и с ссылкой на /blog как на стандарт «как мы пишем и обновляем материалы»).
Эта секция — про то, как держать разговор о безопасности «на земле»: активы, ущерб, вероятные атаки и реальные ограничения команды. Её удобно использовать в конце планёрки или перед запуском фичи.
Что мы защищаем? (данные клиентов, деньги, доступы, репутацию, доступность сервиса)
Что будет самым неприятным исходом? Потери в рублях/часах простоя, штрафы, массовые возвраты, потеря доверия.
Кто может атаковать и зачем? Мошенник ради денег, конкурент, обиженный сотрудник, случайный «исследователь», ботнет.
Как атака выглядит по шагам? Не «XSS/SQL», а: «получить доступ → закрепиться → вывести деньги/данные».
Где у нас сейчас самая слабая часть цепочки? Регистрация, восстановление доступа, админка, интеграции, поддержка.
Какая защита даст максимум эффекта за неделю? Часто это 2FA для админов, ограничения прав, журналирование, контроль подозрительных операций.
Как мы поймём, что нас ломают? Какие сигналы/алерты увидим, кто дежурит, что делать в первые 30 минут.
Вы в зоне пустых разговоров, если:
Неделя 1: выбрать 3–5 ключевых активов и согласовать критерии успеха (что считаем «инцидентом»).
Неделя 2: собрать простую модель угроз (сценарии, акторы, входы, последствия). Достаточно одной страницы.
Неделя 3: приоритизировать по «вероятность × ущерб», выбрать топ‑3 риска и владельцев задач.
Неделя 4: закрыть топ‑3 (или заметно снизить), добавить базовое обнаружение/реакцию, закрепить процесс: 15 минут на безопасность в планировании.
Практическая безопасность — это управление рисками в реальной системе: активы + акторы + поверхности атаки + процессы. Она отвечает на вопросы «что защищаем», «от кого», «какой ущерб», «какими мерами уменьшаем риск», а не спорит о «самом правильном алгоритме».
Потому что атаки часто обходят математику и идут через людей, доступы и процессы: фишинг, сброс пароля, ошибки ролей, утечки через логи, «вечные» ключи интеграций.
Криптография помогает, но обычно не закрывает сценарии вида «получить доступ к почте → восстановить пароль → войти легально».
Начните с инвентаризации того, что реально имеет цену:
Формулируйте активы «человеческим языком», чтобы бизнес и команда понимали одно и то же.
Полезный минимум — письменно ответить:
Эти ответы сразу отсекают меры, которые дороже потенциального ущерба.
Достаточно четырёх блоков:
Чтобы не утонуть в деталях, делайте модель на 1–2 страницы и сразу привязывайте меры к владельцам и срокам (см. /blog/model-ugroz).
Используйте простую матрицу: риск = вероятность × ущерб.
Практичные шкалы:
Цель — выбрать 3–5 действий на ближайший цикл, а не «закрыть всё сразу».
Потому что ошибки предсказуемы: фишинг, повтор паролей, доверие к «похожему» интерфейсу.
Лучше работают решения, где безопасное поведение — самое простое:
В уязвимостях часто виноваты не «плохие инженеры», а перекос стимулов:
Выравнивание стимулов: назначайте владельцев рисков, фиксируйте принятый риск и срок, делайте последствия видимыми, закладывайте ресурсы на базовые проверки и наблюдаемость.
Перед тем как «просто включить шифрование», проверьте:
Часто ключи и бэкапы важнее выбора «самого сильного алгоритма».
Соберите минимальный набор, который уменьшает ущерб:
Идея простая: предотвращение снижает вероятность, а реакция снижает ущерб — нужно и то, и другое.