Правила поиска и фильтров в приложении: как описать совпадения, сортировку, подсказки и фолбэки, чтобы поиск не возвращал пусто.
Пустая выдача почти всегда возникает не из-за «плохих данных», а из-за слишком строгих правил. Данные есть, но поиск требует точного совпадения там, где пользователь ожидает хотя бы близкий результат. Человек вводит «детский врач», а в карточках услуг написано «педиатрия». Если правило одно: искать только точную фразу, система честно покажет «ничего не найдено».
Другая крайность тоже опасна. Если требований нет, ИИ часто «догадывается» по-своему: ищет только по одному полю (например, по названию), учитывает регистр, не прощает опечатки, игнорирует синонимы. Или наоборот, матчится слишком широко, а потом «душит» выдачу фильтрами. В vibe-coding платформах вроде TakProsto это особенно заметно: приложение собирается быстро, но поведение поиска без явных правил получается случайным.
Поэтому полезнее заранее договориться о нескольких вещах. Это не про технологии, а про ожидания: что считать «похоже», как вести себя при неоднозначности и что делать, когда результата нет.
Ответьте на базовые вопросы.
В большинстве запросов человек хочет увидеть хоть что-то полезное, а не идеальную пустоту. Значит, по умолчанию поиск должен быть мягким, а точность включаться через уточнения: фильтры, кавычки, выбор категории. Тогда «ничего не найдено» станет редким исключением, а не стандартным ответом.
Чтобы поиск не уходил в ноль, сначала разберите не «как искать», а «зачем человек ищет». Правила поиска и фильтров в приложении лучше писать от реальных намерений, а не от возможностей системы.
Начните с малого: возьмите 5-10 настоящих запросов из чатов, писем, звонков или истории поиска. Если данных нет, попросите поддержку и продуктовую команду вспомнить самые частые формулировки. Важно фиксировать запрос целиком, как его написал человек, со сленгом и ошибками.
Дальше разложите запросы по типам. Обычно хватает трех: человек ищет конкретное, выбирает из категории или подбирает по условиям. Один и тот же запрос может быть смешанным, и это нормально.
Пример карты намерений, которую удобно отдавать ИИ (например, когда описываете поведение поиска в TakProsto):
Следующий шаг: разделите то, что должно работать всегда, и то, что является уточнением. Например, «категория: услуги» может быть обязательной, если пользователь уже находится внутри раздела. А «срочно» и «с выездом» чаще стоит считать необязательными, чтобы они не обнуляли выдачу.
Не забудьте про разные слова для одного и того же. Составьте короткий список синонимов и сокращений (5-20 штук), которые реально встречаются: «ИП/предприниматель», «доставка/курьер», «бух/бухгалтерия». Это дешевле и надежнее, чем пытаться угадать «все возможные» варианты.
Пустая выдача часто начинается не с «плохого алгоритма», а с туманных данных. Если вы формулируете требования к поиску для ИИ, сначала договоритесь, что именно считается объектом поиска и какие поля у него есть. Иначе поиск будет смотреть «не туда»: ИИ сделает поиск по названию, а пользователь будет ждать результат по описанию или тегам.
Начните с простого перечня сущностей. В одном приложении это могут быть товары, заказы, статьи и клиенты. В другом только услуги и исполнители. Главное, чтобы у каждой сущности были понятные поля и заранее было решено:
Полезно собрать «паспорт поиска» на одну страницу:
Отдельно решите, что показывать в результатах. Если в выдаче не видно цены, города или статуса, пользователю сложнее понять, почему фильтр «сработал». Минимальный набор обычно такой: заголовок, 1-2 уточняющих атрибута и короткий фрагмент, где видно совпадение.
Пример: каталог услуг. Пользователь вводит «чистка дивана». Если вы индексируете только название услуги, а слово «диван» встречается лишь в описании, выдача будет пустой. Решение простое: добавить описание и теги в поля поиска, а город и цену оставить фильтрами. Если вы собираете приложение в TakProsto, эти договоренности лучше фиксировать до генерации, чтобы затем не «лечить» поведение точечными правками.
Пустая выдача часто появляется из-за слишком строгих совпадений. Начните с базового: что считается совпадением по умолчанию, а что включается только по явному запросу пользователя.
Точное совпадение полезно для полей вроде артикула, номера заказа, ИНН, кода купона. Там, где люди вводят «точно известное», точность оправдана. Во всех остальных случаях лучше частичное совпадение: по словам, по началу слова, по фразе внутри названия. Иначе «детский стоматолог» не найдется по запросу «стоматолог детям».
Порядок слов обычно не должен ломать результаты. Пользователь пишет как удобно: «ремонт айфон экран» и «экран айфон ремонт» должны давать похожую выдачу.
Стоп-слова (типа «и», «в», «на») лучше игнорировать при совпадении, но учитывать в подсказках, чтобы фразы выглядели естественно.
Для запросов длиной 1-2 символа заранее решите поведение: показать популярные категории, недавние запросы или попросить уточнить. Главное, не запускать «серьезный» поиск, который почти всегда дает ноль.
Разрешите умеренные опечатки, но не превращайте поиск в угадайку. Практичное правило: допускать 1 ошибку в коротком слове и 2 в длинном. Для чисел и кодов ошибки лучше не допускать вообще.
Проверьте случаи «русская-английская раскладка» и транслит. В России это частая причина пустой выдачи: «ghbdtn» вместо «привет», «moskva» вместо «москва». В требованиях удобно прямо зафиксировать: для текстовых полей пробуем исправлять раскладку и транслитерацию, но не делаем это для паролей, номеров и артикулов.
Вот набор решений, который стоит записать одним блоком:
Фильтры ломают поиск не потому, что данные плохие, а потому что правила слишком жесткие. Пользователь ставит 2-3 галочки, и выдача превращается в пустоту. Если вы описываете требования для ИИ, задайте простое правило: фильтры должны помогать сузить выбор, а не наказывать за точность.
Разведите две ситуации: «нет результатов» и «слишком много результатов». При нуле интерфейс должен объяснять, какие условия отсекли все, и давать быстрый выход. При слишком большой выдаче, наоборот, подсказывать, какие фильтры обычно сужают список, и показывать счетчик результатов до применения.
Хорошая практика - сделать часть фильтров «мягкими». Это значит: если после применения получается 0, система не молчит, а предлагает ближайшую альтернативу.
Пример формулировки: при нуле система должна (1) подсказать, какой фильтр снять, и (2) предложить ближайшее ослабление, не меняя остальные условия. Например: «По рейтингу 4+ ничего нет. Показали 12 вариантов с рейтингом 3+».
Активные фильтры должны быть видны одним взглядом: чипы над результатами, счетчик и одна кнопка «Сбросить все». Полезно уметь снять конкретный фильтр в один тап, без захода в панель.
Зависимые фильтры должны вести себя предсказуемо. Если «город зависит от страны», то при смене страны город либо сбрасывается, либо остается только если он есть в новой стране. То же касается категорий и подкатегорий.
Пустые значения (нет цены, нет рейтинга) нельзя оставлять без правил. Решите заранее, включать их или исключать по умолчанию. Простой вариант: если выбран фильтр «Цена до 5000», то услуги без цены не показывать, но добавить переключатель «Показывать без цены». Для рейтинга аналогично: «4+» исключает без рейтинга, но можно подсказать «У 8 вариантов нет рейтинга - показать их».
Пример: человек ищет уборку в Казани, ставит «сегодня», «до 3000», «рейтинг 4.8+» и получает 0. Нормальная реакция - показать, что ограничило выдачу (например, рейтинг и цена), предложить ослабить одно условие и дать ближайший вариант (4.5+ или расширить дату), а не оставлять экран пустым.
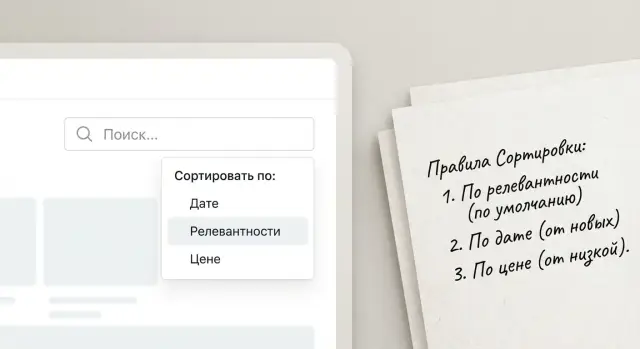
Сортировка часто решает исход поиска сильнее, чем сам запрос. Если порядок не задан, человек видит «правильные» результаты, но не на первых местах, и делает вывод, что поиск плохой. В требованиях сортировку лучше фиксировать так же четко, как и логику совпадений.
Начните с сортировки по умолчанию, которая подходит в большинстве случаев. Обычно это «самое полезное сейчас»: то, что актуально, доступно и ближе к запросу.
Важно описать вторичную сортировку, иначе при равных значениях выдача будет «прыгать». Пример: сначала релевантность, потом наличие, потом рейтинг, потом цена, потом алфавит. Так пользователь видит стабильный порядок и быстрее ориентируется.
Если у вас есть особые метки («акции», «проверенные», «в наличии»), не смешивайте это в один непонятный коэффициент. Лучше задать короткие приоритеты:
Продумайте, что делать с пропусками данных. Если у части карточек нет рейтинга или даты обновления, явно задайте поведение: «пустое значение уходит вниз» или «считаем как 0». И отдельно отметьте случаи, когда пропуск не должен наказывать: например, новая карточка без отзывов не обязана падать в самый конец, если она лучше попадает в запрос.
Пример формулировки требований: «Сортируем по: (1) релевантность, (2) in_stock desc, (3) verified desc, (4) promo desc внутри одинаковой релевантности, (5) updated_at desc, (6) rating desc, (7) price asc, (8) name asc. Null updated_at и null rating считаем минимальными и ставим ниже».
Подсказки нужны не для красоты, а чтобы сократить путь до результата. Если пользователь набирает «дост…», ему важно быстро увидеть, что именно есть в системе: категория, популярный запрос или конкретный объект. В рамках правил поиска и фильтров это слой, который часто спасает от нулевой выдачи еще до нажатия Enter.
Обычно работают три типа подсказок. Их можно смешивать, но с понятной логикой: сначала запросы (как люди формулируют), затем категории, затем элементы.
Важно, чтобы тип подсказки был узнаваем: подпись, иконка или группировка. Иначе пользователь не понимает, что именно он выбирает.
Автодополнение включайте только когда вы правда уверены в намерении. Если после 2-3 букв система часто угадывает верно, можно подставлять окончание (и принимать его по Tab). Если угадывания спорные, лучше не «перетягивать» ввод, а просто показывать список вариантов.
Если вариантов десятки, человек теряется. Здесь помогают простые ограничения: лимит, группировка и приоритет.
«Вы имели в виду» показывайте осторожно. Хороший сигнал - опечатка или раскладка (например, «ghbdtn» вместо «привет»), а не любое несовпадение. И показывайте это как мягкую рекомендацию, не подменяя исходный запрос.
Тексты пустого состояния должны помогать, а не обвинять. Вместо «Ничего не найдено» лучше: «По запросу “…” нет точных совпадений. Попробуйте убрать фильтр, выбрать категорию или посмотреть похожие варианты». Если вы собираете требования для ИИ, отдельно пропишите: когда показывать пустое состояние, какие подсказки давать и какие действия предлагать.
Представьте каталог медицинских услуг. Данных пока мало. Пользователь вводит: «педиатр москва сегодня». Если применить все слова как жесткие условия, результат легко станет нулевым. Поэтому правила должны различать: что обязательно, а что скорее пожелание.
Разберите запрос на части. «Педиатр» лучше всего совпадает с полем специальности (и синонимами вроде «детский врач»). «Москва» - это город или локация клиники. «Сегодня» - не текст, а ограничение по доступным слотам.
По совпадениям по словам работает простая иерархия: специальность важнее названия клиники, город важнее описания. А длинные тексты (био, отзывы) не должны побеждать точные поля. Так вы избегаете ситуации, когда наверх попадает «педиатр в Подмосковье» только потому, что в отзыве есть слово «Москва».
Фильтры удобно делить на автоматические и ручные. Автоматически включайте только то, что почти всегда верно: город из запроса и специальность. А «сегодня», цена, онлайн прием - делайте мягкими или ручными, иначе выдача будет часто обнуляться.
Если «сегодня» не найдено, срабатывает фолбэк, который сохраняет смысл запроса:
И обязательно проговорите пользователю, что именно было ослаблено. Короткая строка над выдачей часто спасает доверие: «Свободных записей на сегодня нет. Показали ближайшие даты» и кнопка «Вернуть только сегодня».
Чтобы ИИ сделал поиск, который помогает, ему нужны не общие слова, а конкретные правила. Удобный формат - короткий документ: сущности, примеры, запросы, логика совпадений, фильтры, сортировка и тексты состояний.
Опишите сущность (что именно ищем) и поля. Добавьте 3 живых примера объектов, как они будут храниться. Например: услуга с полями "название", "описание", "город", "цена", "категория", "рейтинг", "синонимы".
Перечислите типы запросов и ожидания: по названию ("стрижка"), по проблеме ("болит спина"), по атрибуту ("в Казани"), по диапазону ("до 3000"), с ошибками ("strojka"). Для каждого коротко определите, что считать успехом: хотя бы 1 результат или, например, минимум 5.
Задайте правила совпадений и послабления. Пример: сначала точное совпадение по названию, затем частичное по словам, затем по синонимам; разрешить опечатки до 1-2 символов; игнорировать регистр и "ё/е".
Фильтры и зависимости: какие фасеты доступны, какие несовместимы, что делать при нуле результатов (подсказать снять самый строгий фильтр, предложить «расширьте цену»).
Сортировки: основная (релевантность), вторичная (рейтинг), третья (цена). Отдельно укажите правила при равной релевантности, чтобы порядок не прыгал.
Тексты подсказок и пустых состояний: короткая подсказка в поле ввода, 3-5 примеров запросов, понятный текст при пустой выдаче с 1-2 действиями.
Если вы делаете приложение в TakProsto, этот шаблон удобно заносить в planning mode: так правила фиксируются до генерации, и поиск получается частью логики экрана, а не «черным ящиком».
Пустая выдача почти всегда означает не «плохие данные», а слишком жесткие правила. ИИ может аккуратно реализовать требования, но если требования сами ведут к нулю, получится поиск, который ничего не находит.
Человек ищет «ремонт айфона 13» в каталоге услуг. У вас есть услуга «Замена дисплея iPhone 13», но поиск смотрит только на «Название услуги», без синонимов и без учета латиницы. Параллельно включен фильтр «район: Центр» по умолчанию. Итог - пусто, хотя нужная услуга есть.
Хорошее пустое состояние должно помогать: показать активные фильтры, предложить снять самый жесткий, подсказать похожие запросы. Если вы собираете требования для ИИ, прямо опишите поведение при нуле: что ослабляем сначала, а что не ослабляем никогда (например, «только безопасные категории»).
Перед релизом поиска не нужны месяцы исследований. Нужна короткая проверка, которая покажет, что выдача не проваливается в ноль без причины, а человек понимает, что делать дальше.
Соберите небольшой набор запросов и прогоните его вручную, как обычный пользователь. Обычно хватает 20 запросов, но они должны быть разными: короткие (1-2 слова), длинные (фраза), с синонимами, с ошибкой в одном слове.
Параллельно проверьте около 10 комбинаций фильтров. Специально попробуйте крайние случаи: выбрать сразу много фильтров, выставить редкий диапазон цены, включить редкий признак. Важно увидеть, где выдача уходит в ноль, и понять, ожидаемо ли это.
Минимальный чеклист:
Если нашли 3-5 проблемных примеров, не пытайтесь чинить все сразу. Возьмите один тип провала и запишите правило простыми словами: что считаем совпадением, что делаем при нуле, какие фильтры нельзя сочетать без предупреждения, какой порядок сортировки по умолчанию и при равенстве.
Соберите это в документ на 1-2 страницы и отдайте как ТЗ: список полей для поиска, правила совпадений, поведение фильтров, тексты для пустой выдачи, примеры запросов и ожидаемый результат.
Если вы делаете приложение в TakProsto, начните с planning mode, чтобы договориться о правилах до генерации. А затем тестируйте изменения через snapshots и rollback: так проще сравнивать варианты и откатываться, если поиск стал хуже.
Чаще всего данные есть, но правила слишком строгие. Например, вы ищете только точную фразу или только по одному полю (только name), а пользователь ожидает совпадения по смыслу, по формам слов и по описанию. Начните с ослабления базового совпадения и добавьте понятный фолбэк на случай нуля.
Сначала договоритесь, какие поля вообще участвуют в поиске: название, описание, теги, коды, автор, адрес. Затем отдельно перечислите поля для фильтров и поля, которые нужны только для карточки результата. Если это не зафиксировать, поиск почти всегда «смотрит не туда» и регулярно уходит в ноль.
Базовый набор синонимов почти всегда окупается, потому что люди пишут по-разному: «детский врач» и «педиатр». Делайте список коротким и реальным (5–20 вариантов на домен), а не попытку покрыть «всё на свете». Лучше явные синонимы и сокращения, чем надежда, что система сама догадается.
По умолчанию стоит прощать регистр, «ё/е» и 1–2 опечатки в слове, иначе пустых выдач будет слишком много. Для кодов, номеров заказов, ИНН и артикулов лучше не допускать ошибок и требовать точность. Так вы не превращаете поиск в угадайку, но спасаете типичные пользовательские опечатки.
Исправление раскладки и транслита полезно для текстовых запросов, потому что это частая причина нуля: человек вводит не в той раскладке или пишет латиницей. При этом для чувствительных или «точных» полей (коды, номера, купоны) такое исправление лучше отключить. Важно, чтобы система показывала подсказку и не подменяла запрос молча.
Для 1–2 символов лучше не запускать «серьезный» поиск, который почти всегда вернет ноль или шум. Нормальный вариант — показать популярные категории, недавние запросы или попросить уточнить ввод. Это выглядит полезнее, чем пустой экран из‑за слишком короткого запроса.
Задайте правило «не обнулять выдачу»: если после применения фильтров получилось 0, интерфейс должен объяснить, какой фильтр отсек всё, и предложить ослабление. Хороший вариант — показать ближайшую альтернативу, сохранив остальные условия, и дать кнопку вернуть строгий фильтр обратно. Так фильтры помогают выбирать, а не наказывают за точность.
Зависимые фильтры должны вести себя предсказуемо: при смене «родительского» значения дочернее либо сбрасывается, либо остается только если допустимо. Для пустых значений (нет цены, нет рейтинга) заранее решите, включать их или исключать, иначе пользователь будет получать неожиданный ноль. И добавьте понятное объяснение, почему часть объектов скрылась.
Нужна стабильная сортировка по умолчанию и понятные вторичные правила, иначе результаты «прыгают» и кажется, что поиск сломан. Обычно достаточно схемы: сначала релевантность, затем доступность/актуальность, потом рейтинг или обновление, дальше цена и алфавит. Для пропусков (нет рейтинга, нет даты) задайте явное поведение, чтобы они не ломали порядок.
Опишите требования как короткое ТЗ: сущности и поля, примеры объектов, типы запросов, правила совпадений, поведение фильтров при нуле, сортировки и тексты пустых состояний. В TakProsto удобно сначала зафиксировать это в planning mode, чтобы генерация не делала случайных допущений. После изменений проверяйте на наборе тестовых запросов и сравнивайте версии через snapshots и rollback, чтобы быстро откатываться, если стало хуже.