Практическое руководство по RabbitMQ: когда он нужен, как настроить обменники и очереди, надежную доставку, ретраи, мониторинг и масштабирование.
RabbitMQ — это брокер сообщений: отдельный сервис, который принимает сообщения от одних частей системы и доставляет их другим. Его ключевая роль — развязать компоненты приложения во времени и по нагрузке. Один сервис может «положить» событие или задачу в очередь, а другой — обработать позже, в своём темпе.
Без брокера интеграции часто строятся на прямых HTTP-вызовах. Это удобно, пока всё стабильно. Но если получатель временно недоступен или перегружен, запросы начинают падать, растёт время ответа, появляются цепочки ретраев и эффект домино.
RabbitMQ добавляет промежуточный слой: отправитель публикует сообщение и не обязан ждать, пока получатель всё обработает. В результате система становится устойчивее к всплескам трафика и частичным сбоям.
Очередь в базе данных — это обычно самодельная схема: таблица, статусы, блокировки, фоновые воркеры. Это работает, но часто упирается в конкуренцию за записи, сложность «честной» доставки и влияние на основную транзакционную БД.
HTTP — про запрос/ответ «здесь и сейчас». RabbitMQ — про асинхронную доставку и буферизацию: сообщение можно принять, сохранить и отдать потребителю, когда тот готов.
Пользователь оформляет заказ. Сервис заказов создаёт запись и публикует событие «Заказ создан». Далее:
Важно: если уведомления временно «лежат», заказ всё равно создаётся — сообщения подождут в очереди, а обработка догонит позже.
RabbitMQ стоит добавлять не «для красоты», а когда приложение начинает страдать от непредсказуемой нагрузки и высокой связности между компонентами. Очередь сообщений разрывает прямую зависимость между отправителем и получателем: один сервис быстро кладёт задачу, другой — забирает и выполняет, когда готов.
Если узнаёте хотя бы пару пунктов — очередь почти наверняка упростит жизнь:
RabbitMQ не обязателен, если поток простой и нагрузка мала:
Иногда лучше выбрать другое. Например, если нужен строгий порядок и replay событий на длинных промежутках, чаще смотрят в сторону лог-ориентированных брокеров (Kafka-подобные). Если нужна совсем минимальная задержка внутри одного процесса — подойдёт простой job-раннер без отдельного брокера.
Перед выбором зафиксируйте: допустимую задержку (мс/сек/мин), уровень надёжности (можно ли терять сообщения), важен ли порядок, и сколько стоит простой/потеря событий. Эти ответы определят сложность решения и бюджет эксплуатации.
Оцените текущие сообщения/сек и пиковые значения, средний размер сообщения, сколько потребителей будет обрабатывать параллельно. Добавьте прогноз роста (например, x2 за год) и заложите запас по пикам — это поможет понять, нужен ли брокер уже сейчас и каким должен быть стартовый масштаб.
RabbitMQ чаще всего используют через протокол AMQP 0-9-1. Чтобы уверенно читать документацию и настройки, полезно разобраться в базовых сущностях: как приложение подключается, куда «кладёт» сообщения и почему получатель читает их не оттуда, куда вы отправляли.
Приложение устанавливает connection (TCP-соединение) к брокеру. Это относительно «дорогая» штука: её обычно держат открытой.
Внутри connection создаются channels — лёгкие виртуальные потоки. Почти все операции идут через канал: объявление очередей, публикация, потребление. Типичный паттерн: 1 connection на процесс и несколько channels под разные задачи.
Дальше:
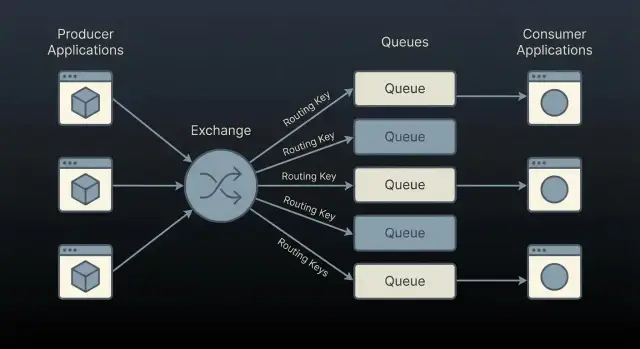
Упрощённая схема: Producer → Exchange → (Binding rules) → Queue → Consumer.
Важно: если вы опубликовали сообщение в exchange, но ни одна binding не подошла, сообщение может быть потеряно (или возвращено — зависит от настроек публикации и флагов).
Сообщение состоит из тела (payload) и properties (метаданных). На практике чаще всего используют:
application/json);Properties не заменяют контракт данных, но помогают маршрутизировать, отлаживать и совместимо развивать интеграции.
vhost — логическая «песочница» внутри одного RabbitMQ. В каждом vhost свои exchange/queue/binding и свои права доступа.
Практичные сценарии:
dev, stage, prod на одном кластере (если так принято в компании);Это база. Дальше выбор типа exchange, подтверждения и ретраи будут восприниматься как настройка поведения поверх понятной схемы.
Правильный выбор exchange в RabbitMQ определяет, насколько легко вам будет расширять систему: добавлять новых потребителей, вводить новые типы событий и не превращать маршрутизацию в набор исключений.
Direct exchange отправляет сообщение в те очереди, где binding key точно совпадает с routing key.
Это хороший вариант для «команд» и точечных задач: например, billing.charge или email.send. Плюсы — предсказуемость и простая отладка. Минус — при росте количества типов сообщений может появиться много отдельных ключей и биндингов.
Topic exchange сопоставляет routing key по шаблонам (например, order.* или order.#). Он особенно удобен для событий, когда разные сервисы подписываются на разные подмножества.
Пример: события заказов.
order.createdorder.paidorder.shippedСервис аналитики может слушать order.#, а сервис уведомлений — только order.paid и order.shipped. Такой подход хорошо масштабируется: добавили новый сервис — добавили binding, издателя трогать не нужно.
Fanout exchange игнорирует routing key и отправляет сообщение во все привязанные очереди.
Подходит для простых broadcast-сценариев: «сбросить кэш», «обновить конфигурацию», «переоткрыть фичи». Важно помнить: fanout легко создаёт неожиданный трафик, если к exchange привязывают очереди без строгого контроля.
Headers exchange маршрутизирует по заголовкам AMQP (например, type=invoice, region=EU). Его стоит выбирать, когда routing key становится перегруженным или нужна маршрутизация по нескольким независимым признакам.
Обычно это инструмент «последней необходимости»: заголовки хуже читаются в логах и сложнее стандартизируются.
Хорошие имена экономят время на поддержке и расследованиях:
<domain>.<purpose> — order.events, billing.commands.<domain>.<entity>.<event> или <domain>.<event> — order.created, user.password_reset.<service>.<domain>.<subscription> — notify.order.paid, analytics.order.all.Договоритесь о словаре событий и не меняйте семантику существующих ключей: вместо «переопределения» добавляйте новый ключ/событие. Это снижает риск тихих потерь и неожиданных подписок.
Надёжность в RabbitMQ складывается из нескольких «слоёв»: что переживёт перезапуск брокера, как издатель (producer) понимает, что сообщение принято, и как потребитель (consumer) подтверждает обработку. Если хотя бы один слой настроен «по умолчанию», вы можете получить потери или неожиданные повторы.
Частая путаница: durable очередь и persistent сообщение — разные настройки.
Чтобы сообщения действительно переживали перезапуск, обычно нужны оба условия: очередь durable и сообщения persistent. Даже тогда возможны нюансы (например, сообщения могут быть в памяти до записи на диск), поэтому следующий слой — подтверждения от брокера — критичен.
Publisher confirms — механизм, когда producer получает подтверждение, что брокер принял сообщение (и, в зависимости от конфигурации, успел его зафиксировать).
Смысл простой: если публикация не подтвердилась (таймаут/negative ack), producer должен повторить отправку или сохранить событие для повторной попытки. Без confirms вы можете «успешно» отправить сообщение из приложения, но потерять его при проблемах на стороне брокера.
Consumer должен отправлять ack только после того, как работа реально сделана (например, запись в БД завершилась).
Если подтверждать «сразу при получении», вы рискуете потерять сообщения при падении consumer.
prefetch ограничивает, сколько неподтверждённых сообщений RabbitMQ выдаёт consumer одновременно. Это защищает от перегрузки и помогает справедливости: быстрые потребители не простаивают, а медленные не «захватывают» очередь.
С типичной связкой confirms + ack вы получаете доставку at-least-once: сообщение будет обработано минимум один раз, но иногда — дважды (при ретраях/переподключениях).
Exactly-once на уровне брокера обычно недостижимо в реальных сбоях, поэтому практичная цель — проектировать обработчики так, чтобы повтор не ломал систему (например, через уникальные ключи/дедупликацию на стороне данных).
RabbitMQ не обещает «ровно один раз». Сеть может моргнуть, потребитель упасть после обработки, а подтверждение (ack) не успеть уйти — и сообщение придёт снова. Поэтому правильный вопрос не «как убрать повторы», а «как сделать повторы безопасными».
Даже при аккуратных ack вы обычно получаете семантику at-least-once (как минимум один раз). Значит, обработчик должен выдерживать повторную доставку без двойных списаний, дублей писем и «разъехавшихся» статусов.
Практичный подход — делать операции идемпотентными:
event_id/command_id (UUID) и храните «уже обработанные» в БД/кеше с TTL.event_id) и обрабатывайте конфликт как «уже сделано».updated_at/условный апдейт, чтобы повтор не откатывал состояние назад.Важно: дедупликация должна быть рядом с реальным эффектом (в той же транзакции), иначе появится окно гонки.
Для повторов с паузой чаще всего используют:
Делайте задержку ступенчатой (например, 10с → 1м → 10м) и храните счётчик попыток в заголовках.
DLQ — не «мусорка», а очередь для разбирательств. Туда стоит отправлять сообщения, которые:
Организуйте процесс: метрики по DLQ, алерты и понятные причины в заголовках/логах.
«Ядовитые» сообщения (всегда падают) опасны тем, что могут занять воркеры. Защита простая: лимит ретраев, перевод в DLQ и отдельная процедура повторной подачи после исправления (с новым event_id, если это важно для дедупликации).
RabbitMQ часто воспринимают как «универсальный клей» между сервисами. На практике устойчивые интеграции строятся на понятных паттернах и чётких ожиданиях: кто инициатор, кто отвечает за результат, какие гарантии доставки нужны.
Команда — адресное намерение: «сделай X» (обычно одному получателю). Отправитель ожидает, что работа будет выполнена, и зачастую важен контроль ошибок.
Событие — факт: «X произошло» (полезно многим подписчикам). Публикатор не должен знать, кто и как отреагирует. Это снижает связность, но повышает требования к идемпотентности и совместимости сообщений.
Хорошее правило: команды помогают управлять процессом, события — информировать. Не подменяйте одно другим — иначе сложнее отлаживать ответственность.
RPC (request/reply) поверх очередей используют, когда действительно нужен синхронный ответ, но прямой HTTP-вызов невозможен.
Риски: рост задержек, таймауты, накопление «висящих» запросов, сложности с ретраями (можно случайно выполнить операцию дважды). Если выбираете RPC, обязательно задавайте таймауты, correlation-id, лимиты параллелизма и продумывайте поведение при повторной доставке.
Для бизнес-процессов из нескольких шагов применяют саги: либо оркестратор координирует команды и слушает события, либо используется хореография на событиях.
Важно не превращать брокер в «магическую шину», где логика процесса размазана по подписчикам без явного владельца. Обычно проще сопровождать процесс, когда есть один сервис-«дирижёр» и прозрачные компенсирующие действия.
Типичная проблема: сервис записал изменения в БД, но не смог опубликовать сообщение (или наоборот). Outbox решает это: вместе с бизнес-транзакцией в БД пишется запись в outbox-таблицу, а отдельный воркер надёжно публикует события в RabbitMQ.
Так вы уменьшаете риск «потерянных» событий и упрощаете повторную отправку.
Сообщения живут дольше кода. Добавляйте поля так, чтобы старые потребители могли их игнорировать, а новые — работать при отсутствии поля. Полезно иметь явную версию схемы (например, в заголовке) и заранее договориться о правилах: изменения «только добавлением» и постепенное удаление полей после периода совместимости.
RabbitMQ хорошо масштабируется, если заранее договориться о модели параллелизма: сколько consumer’ов вы запускаете, сколько потоков/воркеров внутри каждого и какая «единица работы» у сообщения. Частая ошибка — увеличивать число consumer’ов без контроля prefetch: один быстрый потребитель забирает слишком много сообщений и держит их «в обработке», пока другие простаивают.
Практика: начинайте с небольшого числа процессов (например, 2–4 на инстанс) и регулируйте prefetch так, чтобы в работе у каждого было ровно столько сообщений, сколько он реально успевает обработать. Если обработка CPU‑тяжёлая — масштабируйте по числу ядер. Если I/O — можно больше параллелизма, но следите за ростом задержки.
Если важен порядок «по ключу» (например, по userId), один общий поток сообщений быстро станет бутылочным горлышком. Решение — очереди‑шарды: маршрутизируйте сообщения по ключу в N очередей (consistent hash или явный номер шарда), сохраняя порядок внутри каждой очереди, но позволяя параллельность между шардами.
Автомасштабирование обычно строят по одному из сигналов:
Длина очереди полезна, но задержка часто отражает пользовательскую боль точнее.
Для высокой надёжности чаще выбирают quorum queues: они устойчивее к сбоям и предсказуемее по консистентности. Классическое зеркалирование (mirrored) встречается в старых установках и требует осторожности: сложнее в эксплуатации и может давать неприятные сюрпризы при сетевых проблемах.
Большие сообщения — главный враг производительности: растут сетевые расходы, давление на память и диск, время репликации. Хороший ориентир — передавать через очередь «указатель» (id) и метаданные, а payload хранить отдельно.
Также учитывайте: persistent‑сообщения и durable‑очереди увеличивают нагрузку на диск, поэтому важны быстрые диски и контроль объёма очередей, чтобы не упереться в alarm по памяти/диску.
Хороший мониторинг RabbitMQ — это способность быстро ответить на вопросы: где узкое место, что именно тормозит доставку и что делать прямо сейчас.
Начните с показателей, которые почти всегда объясняют происходящее:
Метрики показывают «что», а логи — «почему». Договоритесь, что каждое сообщение несёт correlation_id (или свой trace-id) и ключевые сервисы пишут его в логи. Тогда можно восстановить цепочку: публикация → маршрутизация → получение → обработка → ack/nack.
Если есть распределённая трассировка, связывайте спаны по тому же идентификатору — так проще отличить проблему в RabbitMQ от медленной БД или внешнего API.
Полезные сигналы для оповещений:
Чтобы ловить проблемы до продакшена, делайте короткие нагрузочные прогоны: разгоните publish rate, искусственно замедлите обработчик (sleep/ограничение внешнего API), посмотрите, где первым «сыпется» — потребители, сеть, диск или лимиты RabbitMQ.
Очередь растёт в ready или в unacked?
Есть ли consumers и стабильны ли они?
Deliver rate ≈ Publish rate? Если нет — где провал.
Выросло время обработки у потребителя (логи по correlation_id)?
Нет ли блокировок по disk/memory и ошибок соединений?
RabbitMQ часто становится «центральной шиной» между сервисами — и именно поэтому его стоит защищать так же внимательно, как базу данных. Хорошая новость: базовые меры несложны, если внедрить их с самого начала.
Начните с разделения окружений и команд через vhost. Один vhost на dev/stage/prod (или хотя бы отдельный для prod) помогает изолировать очереди, обменники и права.
Создавайте отдельных пользователей для приложений и для людей. Людям обычно нужен доступ через Management UI, а приложениям — только AMQP.
administrator, monitoring) выдавайте строго по необходимости.configure на .*.TLS стоит включать всегда, когда трафик выходит за пределы одного доверенного сегмента сети: между хостами, в Kubernetes, через VPN, в облаке или при доступе внешних потребителей.
Что важно учесть:
Не храните пароли в репозитории и в .env на ноутбуках. Используйте менеджер секретов (Vault/Secret Manager/Kubernetes Secrets) и разные учётные данные для dev/stage/prod.
Ротацию делайте планово:
Ограничьте доступ на уровне сети: разрешайте подключения к AMQP‑портам только от приложений, а к Management UI (обычно 15672) — только из админской сети/VPN.
Идеально, когда RabbitMQ вообще не «смотрит» в интернет, а доступ возможен лишь через внутренний firewall/security groups.
Чтобы один сервис не «положил» брокер:
max-length, max-length-bytes, TTL), чтобы очереди не росли бесконечно;Эти меры дают понятную изоляцию: кто может подключаться, что может делать и сколько ресурсов способен потребить.
RabbitMQ часто «взлетает» быстро на ноутбуке и неожиданно начинает капризничать в продакшене. Разница обычно не в очередях как таковых, а в эксплуатационных мелочах: политиках, лимитах, порядке обновлений и том, как вы управляете конфигурацией.
Начните с базовых правил, которые предотвращают самые частые аварии:
x-queue-type (classic/quorum), лимиты на длину/размер (max-length, max-length-bytes) и (при необходимости) TTL для сообщений/очередей.Держите настройки в репозитории и применяйте их автоматически:
rabbitmq.conf и advanced.config — как часть инфраструктурного проекта.Планируйте обновления как изменения в базе данных: заранее и по шагам. Сначала проверьте совместимость версий Erlang/RabbitMQ и плагинов. Затем делайте rolling update (по одному узлу), контролируя состояние кластера и репликацию очередей.
Любые изменения типа очереди или ключевых аргументов (например, quorum вместо classic) лучше оформлять как миграцию: новая очередь → переключение продюсеров/консьюмеров → удаление старой.
RabbitMQ можно восстановить по-разному:
На практике часто делают ставку на повторную публикацию событий/команд, а не на «бэкап очереди».
Поднимайте RabbitMQ локально через Docker с теми же definitions и политиками, что и в продакшене (только с меньшими лимитами). Так ошибки маршрутизации, отсутствующие очереди или неверные права проявятся до релиза, а не после.
Если вы собираете сервис на TakProsto.AI (vibe-coding платформа для российского рынка), удобно проверять архитектурные гипотезы с очередями ещё на раннем этапе: вы описываете сценарии в чате, а платформа помогает быстро собрать приложение (типичный стек — React на фронтенде и Go + PostgreSQL на бэкенде) и подключить инфраструктурные компоненты вроде RabbitMQ.
Практически это полезно, когда вы хотите:
Отдельный плюс для проектов с требованиями по локализации и данным: TakProsto.AI работает на серверах в России и использует локализованные/opensource LLM‑модели, не отправляя данные в другие страны.
Даже правильно настроенный RabbitMQ может начать «сыпаться» из‑за нескольких типовых промахов. Ниже — самые частые и практичные способы их предотвратить.
Большие payload (десятки/сотни КБ и больше) увеличивают задержки, нагрузку на диск/память и время восстановления.
Правило: в очередь — только «конверт», а данные — отдельно. Вынесите тяжёлый payload в объектное хранилище (S3/MinIO), а в событии передавайте ссылку, ключ и контрольную сумму/версию. Так проще ретраи и меньше риск «раздуть» брокер.
Когда в одной очереди живут события, команды и «техничка» без явного контракта, потребители начинают обрастать условными ветками и ломаются при изменениях.
Решение: разделяйте по назначению (разные очереди/маршруты) и фиксируйте схему. Минимум — поле type и version в каждом сообщении, описанный JSON Schema/Avro/Proto и правила совместимости (например, только добавление необязательных полей).
Если потребитель забирает слишком много сообщений «в полёт», он может накапливать их в памяти и увеличивать время обработки.
Решение: задайте prefetch (QoS) под время обработки и объём памяти. Начните с 10–50 на поток и измеряйте. Если обработка тяжёлая — уменьшайте, если лёгкая — повышайте.
Без DLQ сообщения либо теряются, либо бесконечно падают и «крутятся».
Решение: делайте retry с ограничением попыток и задержкой (TTL + dead-lettering или отдельная delay-очередь), а после лимита — в DLQ с причиной ошибки. В DLQ должны быть понятные метаданные (счётчик попыток, timestamp, error).
Хаотичные имена очередей и exchange усложняют поддержку и миграции.
Решение: договоритесь о шаблоне имён (например, app.env.domain.event.v1), версионируйте публичные маршруты и не меняйте смысл существующих ключей маршрутизации — добавляйте новые.
RabbitMQ добавляет промежуточный слой между компонентами: отправитель публикует сообщение и не ждёт, пока получатель выполнит работу.
Это снижает связность и делает систему устойчивее к всплескам трафика и временной недоступности отдельных сервисов: сообщения «подождут» в очереди, а обработка догонит позже.
Как правило, очередь помогает, если появляются:
Если у вас простой CRUD и низкая нагрузка, брокер может быть лишним усложнением.
Основная схема такая: Producer → Exchange → (bindings) → Queue → Consumer.
Producer публикует сообщение в exchange, а consumer читает из очереди. Routing происходит через bindings (часто с routing key). Это важно помнить: «публикация в очередь» обычно на деле означает «публикация в exchange, который маршрутизирует в нужную очередь».
Выбор зависит от того, как вы хотите подписывать потребителей:
order.*, order.#), удобно для доменных событий;Практика: для событий чаще начинают с topic, для адресных задач — с direct.
Это разные уровни надёжности:
delivery_mode=2) — сообщение стараются сохранить на диск.Чтобы сообщения обычно переживали рестарт, нужны оба условия: очередь durable и сообщения persistent. Для реальной гарантии добавьте ещё и publisher confirms со стороны producer.
Publisher confirms — механизм, по которому producer получает подтверждение от брокера, что сообщение принято (и в нужной степени зафиксировано).
Без confirms вы можете «успешно» отправить сообщение из приложения, но потерять его при проблемах на стороне сети/брокера. С confirms появляется понятная стратегия: таймаут/negative ack → повторить отправку или сохранить событие для повторной публикации.
Consumer должен отправлять ack только после того, как реальный эффект выполнен (например, запись в БД успешно завершилась).
ack — обработано, удалить из очереди;nack/reject — обработка не удалась (можно вернуть в очередь или отправить в DLQ в зависимости от настроек).Если подтверждать сразу при получении, при падении consumer вы потеряете сообщения (они уже будут «подтверждены»).
prefetch ограничивает число неподтверждённых сообщений, которые брокер выдаёт consumer одновременно.
Это помогает:
Частая практика — начать с небольшого значения и подбирать по времени обработки и ресурсам.
Повторы нормальны для схемы at-least-once: consumer мог упасть после обработки, а ack не успел уйти — сообщение придёт снова.
Чтобы повторы были безопасны:
event_id/command_id и делайте дедупликацию рядом с эффектом (часто в БД);DLQ — это очередь для разбирательств, а не «свалка без мониторинга».
Проблема: сервис записал изменения в БД, но не смог опубликовать сообщение (или наоборот) — получаются «дыры» в событиях.
Outbox решает это так:
Итог: проще повторная отправка и меньше риск потерять событие из-за временных сбоёв брокера/сети.