Разбираем, почему распределённые БД часто выбирают доступность вместо строгой согласованности, и как работают кворумы, репликация и модели согласованности.
Распределённая БД — это база, которая работает не на одном сервере, а на группе узлов. Данные обычно хранятся в нескольких копиях (репликах), а узлы могут быть разнесены по стойкам, дата-центрам и даже регионам. Такой подход помогает переживать поломки и выдерживать рост нагрузки, но добавляет главную «боль»: сеть между узлами не идеальна.
В реальности случаются задержки в сети, перегрузка каналов, перезапуски сервисов, отключение отдельного дата-центра или целого региона. При этом пользователи ожидают, что приложение продолжит отвечать — оплачивать заказ, открывать профиль, писать сообщения.
Но когда часть узлов временно не видит другую часть (или видит с большой задержкой), система вынуждена выбрать, что важнее прямо сейчас:
Ключевой компромисс этой статьи — как распределённые базы данных балансируют согласованность и доступность: когда стоит «подождать ради правды», а когда — «ответить сейчас, даже если позже придётся разрулить расхождения».
На практике редко выбирают крайности. Чаще встречается набор управляемых компромиссов:
Дальше разберём термины без мифов: что именно ломается в сетях, какие модели согласованности бывают, и как репликация/кворумы помогают выбрать подход под ваш продукт и команду.
Чтобы обсуждать теорему CAP без путаницы, полезно зафиксировать три термина на уровне поведения системы и ощущений пользователя.
Согласованность — это про то, насколько предсказуемо система показывает результат записи. Если вы изменили адрес доставки и тут же открыли профиль с другого устройства, согласованная система покажет новый адрес везде.
Важно: в CAP под согласованностью обычно имеют в виду единое «правильное» состояние для чтений (упрощённо — как будто база одна), а не «валидность данных» в смысле ограничений.
Доступность — это про то, получит ли клиент ответ на запрос, даже если часть узлов сломалась или временно недоступна. Ответ может быть успешным (данные прочитаны/записаны) или ошибкой уровня приложения — но принцип A в CAP говорит: система старается не “молчать” и продолжать обслуживать запросы.
Для пользователя это разница между «сервис открывается и что-то показывает» и «крутится загрузка/500 ошибка».
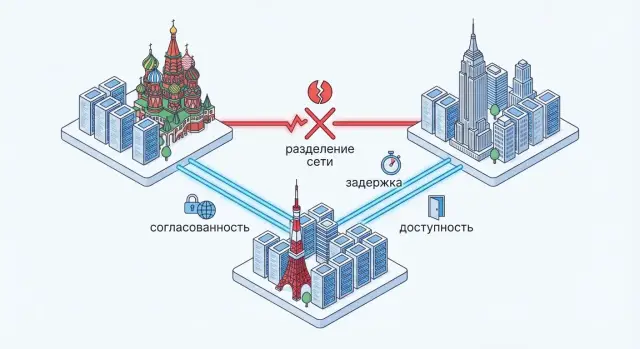
Разделение сети — ситуация, когда кластер распадается на группы, которые не могут обменяться сообщениями: например, дата-центры потеряли связь, коммутатор «подвис», или маршрутизация пошла неверно. Узлы при этом могут быть живы, но не слышат друг друга.
И именно здесь возникает жёсткий выбор: либо продолжать отвечать (A), рискуя показать разные версии данных (теряя C), либо остановить часть операций ради единой правды (C), жертвуя доступностью (A).
Теорема CAP — это не «таблица лидеров» для баз данных, а напоминание о предельных гарантиях в распределённой системе.
CAP говорит: если случилось разделение сети (partition), система не может одновременно гарантировать:
При сетевом разделении приходится выбирать: либо отвечать всем (A) ценой риска прочитать «не самое свежее» (не-C), либо сохранять единый «источник правды» (C) ценой отказов/блокировок части запросов (не-A).
CAP не про:
«Наша сеть надёжная, значит можно игнорировать P». На практике разделение может быть частичным: проблемы маршрутизации, перегруженные коммутаторы, ошибки DNS/Service Discovery, разные таймауты.
«CP/CA/AP — это про продукт целиком». Чаще выбор делается по операциям: например, платежи — ближе к CP, лента рекомендаций — ближе к AP.
Сформулируйте требования вопросами:
Так CAP превращается в договорённости: где система должна «стоять насмерть за правду», а где — «быть доступной любой ценой» с заранее понятными последствиями.
Главная проблема распределённых БД в том, что «поломка» редко выглядит как чёрный экран. Чаще всё продолжает работать, но медленнее, выборочно и непредсказуемо — и именно это приводит к расхождениям.
Сетевое разделение — не всегда физический обрыв. Оно может выглядеть как ситуация, когда часть узлов «видит» друг друга, а часть — нет.
Причины обычно приземлённые: изменения маршрутизации (BGP/ECMP), перегрузка сетевых устройств, ACL/фаерволы, кратковременные ошибки в DNS/Service Discovery, слишком агрессивные таймауты. В итоге кластер может распасться на «острова», где каждый считает, что он живёт отдельно.
Даже без явного разделения одна реплика может получать обновления позже другой из‑за скачков задержек: очереди в сетевых буферах, «шумные соседи» в виртуализации, GC-паузы, перегрузка диска. Формально связь есть, но сообщения приходят «слишком поздно» — и система принимает решения на неполной картине.
Отсюда типичный эффект: чтения в одном месте видят новые данные, в другом — ещё старые, хотя мониторинги «зелёные».
Полный даун дата-центра заметен, и сценарий для него обычно продуман. Опаснее частичные сбои: один rack, один AZ, один коммутатор, несколько узлов с деградацией, а иногда — только один важный сервис (например, координатор/метаданные). При частичных сбоях кворумы и балансировщики могут продолжать направлять трафик «в больную зону», создавая лавину таймаутов.
Таймаут — это не просто «подождали и сдались». Для БД он часто означает: запрос мог выполниться, но ответ не дошёл. Ретрай может превратить один запрос в два, создать дубликаты, усилить нагрузку и продлить деградацию.
Поэтому настройки таймаутов/ретраев — часть модели отказов: они напрямую влияют на то, что система выберет в момент проблем — доступность любой ценой или более строгую согласованность.
Когда говорят «согласованность», часто подразумевают разные гарантии. Это не переключатель «вкл/выкл», а шкала: чем сильнее гарантия, тем дороже она обычно обходится по задержкам, пропускной способности и поведению при сбоях.
Линейризуемость — это ощущение, что у данных есть один общий «текущий момент истины»: операция записи как будто происходит мгновенно, и все последующие чтения в системе видят именно её результат. Пользователь обновил адрес — и любой сервер, в любом регионе, сразу отдаёт новый адрес.
Цена — необходимость координации: подтверждать запись несколькими узлами, ждать кворума, иногда блокировать параллельные операции. В итоге растут задержки (особенно между регионами), а при сетевом разделении часть запросов может начать получать ошибки или таймауты, потому что системе важнее «не соврать», чем «ответить хоть как-то».
Eventual consistency гарантирует, что если новые записи перестали поступать, то со временем все реплики сойдутся к одному значению. Но «когда именно» — не фиксировано: секунды, минуты, а при проблемах связи — дольше.
Практическое следствие: сразу после изменения вы можете прочитать старое значение на другой реплике. Это нормально для ленты новостей, счётчиков просмотров, статусов «в сети», но опасно для балансов и уникальных ограничений, если не добавить дополнительные механизмы.
Каузальная согласованность сохраняет причинно-следственный порядок: если комментарий был отправлен после публикации поста, то система не покажет комментарий «к несуществующему посту».
Сессионная согласованность фиксируется на уровне «вашей сессии» (устройства/токена): в рамках одной сессии поведение предсказуемее, даже если глобально система остаётся слабосогласованной.
Read-your-writes: вы поменяли аватар — и при следующем открытии профиля вы точно увидите новый, даже если другие ещё видят старый.
Monotonic reads: если вы уже увидели новую версию профиля, то при следующих чтениях вы не «откатитесь назад» и не увидите более старую версию.
Эти гарантии часто дают «пользовательское ощущение порядка» без полной линейризуемости — например, закрепляя запросы за одной репликой или используя маркеры версий.
Распределённая база держит данные в нескольких копиях (репликах), чтобы переживать сбои узлов и ускорять чтение рядом с пользователем. Но как только копий больше одной, возникает главный вопрос: если реплики на мгновение разошлись, какую версию считать правильной?
Число реплик обычно обозначают как N. На практике часто выбирают 3 или 5: это даёт запас на отказ одного узла (при N=3) или даже двух (при N=5), но повышает стоимость хранения и трафик на записи. Важно помнить: больше копий не делает систему «магически честнее» — это лишь увеличивает шанс, что «актуальная» версия где-то доступна.
Кворумная схема задаёт два числа:
Интуиция простая: если R + W > N, то чтение и запись пересекаются хотя бы на одной реплике. Значит, при отсутствии крайних сбоев и при корректной логике версионирования вы чаще будете видеть «свежие» данные.
При падении части узлов система выбирает: либо отвечать быстрее, принимая риск устаревших данных (меньше R/W), либо быть строже к актуальности и чаще возвращать ошибку/таймаут (больше R/W).
Даже с кворумами реплики могут расходиться. Поэтому многие системы используют антиэнтропию: фоновую синхронизацию (например, через меркл-деревья или сравнение версий), которая «подтягивает» отстающие копии.
Если обнаружены разные версии, включается мердж: по времени (last-write-wins), по правилам предметной области или через явные конфликты, которые должен разобрать сервис/пользователь. Кворумы помогают чаще читать «правду», а антиэнтропия — со временем приводить все копии к одному состоянию.
«Выбрать доступность» — значит договориться, что система будет отвечать на запросы даже во время сетевого разделения (когда часть узлов не видит другую). Ответ может быть не самым свежим, но пользователь получит результат, а сервис — продолжит работать.
Когда связь между репликами рвётся или сильно замедляется, узлы начинают жить «каждый сам по себе»: принимают записи и обслуживают чтения локально. Из‑за этого появляются устаревшие данные — вы читаете состояние, которое ещё не успело доехать до всех копий.
Важно: это не всегда ошибка. Если продукту важнее непрерывная работа, чем абсолютная точность «прямо сейчас», то временная рассинхронизация — нормальная цена за отсутствие отказа.
Обычно доступность ставят выше согласованности там, где:
Примеры: ленты и рекомендации (пост может появиться чуть позже), каталоги товаров (цены/наличие обновятся с задержкой), метрики и телеметрия (важнее собрать данные, чем сразу их выровнять), кеши (лучше старое значение, чем таймаут).
Больнее всего слабая согласованность бьёт по операциям, где критична единственная версия правды:
Для таких сценариев часто выделяют отдельные компоненты/таблицы со строгими гарантиями, а остальную систему делают более доступной.
Когда система допускает слабую или итоговую согласованность, разные узлы могут временно «видеть» разные версии данных. Это нормально, пока есть понятный способ свести изменения к одному результату.
Представьте профиль пользователя. Клиент А меняет поле «город» на «Казань», а клиент Б почти одновременно — на «Самара». Из‑за задержек и репликации оба обновления расходятся по узлам в разном порядке. В итоге часть запросов читает «Казань», часть — «Самара», а при синхронизации возникает вопрос: какая версия правильная?
Last-write-wins (LWW): «побеждает» запись с самым поздним временем/версией. Это просто и быстро, но есть риск потерять важное обновление из‑за несовпадающих часов или потому, что «позднее» не значит «правильнее».
Версии (оптимистическая блокировка): вместе с записью хранится номер версии. Клиент пишет «обнови, если версия всё ещё 7». Если уже 8 — значит, кто-то успел раньше, и клиент должен перечитать данные и повторить действие осознанно.
Векторные часы (идея): система хранит «вклад» разных узлов в историю изменения. Это помогает отличить два случая: одно обновление действительно позже другого, или они независимы и конфликтуют. Тогда конфликт можно обнаружить честно, а не «случайно победить».
CRDT — это структуры данных, которые можно объединять так, что все реплики придут к одному результату независимо от порядка доставки изменений. Например, счётчики, наборы элементов, некоторые типы регистров. Это снижает число конфликтов, но подходит не для любых бизнес-правил.
Ручное вмешательство нужно там, где важно бизнес-значение: деньги, права доступа, статусы заказов. Упростить помогают: сохранение истории изменений, явные причины обновлений, понятные правила приоритета (например, «оплата важнее отмены»), а также UI для выбора версии и повторной отправки операции.
CAP часто запоминают как выбор «согласованность или доступность» во время сетевого разделения. Но PACELC добавляет важную мысль: даже когда всё нормально и разделения сети нет, система всё равно делает выбор — между задержкой (Latency) и согласованностью (Consistency).
Расшифровка простая:
То есть компромисс существует не только «в аварии», а каждый день — в обычных запросах.
Пользователь почти всегда первым замечает задержку: кнопка «Сохранить» крутится дольше, лента обновляется с паузой, поиск «думает». Несовпадение данных замечают реже — но оно может быть болезненнее (например, деньги, остатки на складе, права доступа).
PACELC помогает проговорить это честно: вы можете сделать систему «быстрой на ощущение», но иногда ценой того, что чтение покажет не самый свежий результат.
Сильная согласованность обычно требует, чтобы запись считалась успешной только после подтверждения от лидера и/или нескольких реплик (кворумы, синхронная репликация). Это добавляет:
В итоге хвостовые задержки (p95/p99) растут — именно их и «чувствует» интерфейс.
Если чтение идёт с ближайшей реплики, ответы быстрые, но возможны устаревшие данные (eventual consistency). Если чтение гарантирует «после записи вижу запись» или требует кворум — данные точнее, но больше задержка.
Поэтому при проектировании важно явно решить: где нужна строгая точность, а где важнее мгновенный отклик — и закрепить это в настройках репликации и режимах чтения/записи.
Слабая (или «нестрогая») согласованность — это не приговор качеству. Это повод проектировать так, чтобы пользователь и команда понимали: где система гарантирует «железно», а где возможны временные расхождения.
Один из самых практичных шаблонов — CQRS: разделить путь записи (команды, изменяющие состояние) и путь чтения (запросы, показывающие состояние).
Команды можно обрабатывать с более строгими правилами (валидации, очереди, последовательность), а чтение — строить из реплик и проекций, которые обновляются асинхронно. Пользователь при этом получает быстрые ответы на чтение, а вы — прозрачное место, где допускается «устаревание» данных.
В распределённой системе «одна транзакция на всё» часто означает хрупкость и блокировки. Вместо этого применяют саги: цепочки локальных шагов, где у каждого шага есть компенсирующее действие.
Например: списали резерв → не удалось создать доставку → сделали компенсацию (сняли резерв). Это проще наблюдать и масштабировать, чем пытаться удерживать глобальный ACID между сервисами и регионами.
При ретраях и повторной доставке сообщений запрос может прийти дважды. Чтобы «два раза не списать», нужны:
Так вы превращаете сетевые повторы в безопасную рутину.
Полезно заранее определить, что именно система обязуется согласовывать строго. Часто такой «атомарной зоной» становится партиция (шард): внутри неё можно обеспечить порядок и кворум, а между партициями — принять асинхронность.
Практический эффект: вы проектируете ключи партиционирования так, чтобы связанные операции жили в одной зоне (например, «всё по заказу» или «всё по пользователю»), и тем самым уменьшаете количество межпартиционных конфликтов.
Выбор между согласованностью и доступностью — не «религиозный спор», а управляемое решение про риски, деньги и ожидания пользователей. И почти всегда не нужно выбирать один режим для всей системы.
Ответьте на вопросы вместе с продуктом, поддержкой и бизнесом:
Практичный подход — разделить данные на уровни и под них выбрать согласованность:
Формулируйте ожидания без терминов вроде «кворум»:
Часто разумно сделать разные уровни согласованности для разных операций:
И последний фильтр — команда: если у вас нет зрелых практик мониторинга, разборов инцидентов и понятной модели конфликтов, то «слабая согласованность ради скорости» может обернуться непредсказуемыми багами. Выбирайте режим, который вы способны объяснить, поддержать и измерить.
Когда вы обсуждаете CAP/PACELC, спор часто упирается не в термины, а в то, как быстро проверить гипотезы на реальном приложении: где нужен строгий путь записи, где можно читать из реплики, как вести версии и идемпотентность.
В TakProsto.AI это удобно прототипировать в формате чата: можно описать домен (например, заказы/оплаты/каталог), попросить собрать веб-интерфейс на React и бэкенд на Go с PostgreSQL, а затем итеративно добавить «режимы» операций — строгие для критичных таблиц и более доступные для вторичных. Полезны planning mode (чтобы сначала договориться о гарантиях и сценариях отказов), а также snapshots и rollback — чтобы безопасно откатываться после изменений в логике ретраев, версионирования и обработке конфликтов.
Отдельный плюс для российского контура: TakProsto.AI запускает приложения на серверах в России и использует локализованные/opensource LLM-модели, не отправляя данные за пределы страны — это важно, если архитектурные эксперименты затрагивают реальные пользовательские данные или требования комплаенса.
Компромисс между согласованностью и доступностью становится опасным не в теории, а в момент, когда «что-то пошло не так», а команда не понимает: данные ещё не доехали, уже конфликтуют или кластер потерял кворум. Поэтому распределённой БД нужны не только настройки, но и наблюдаемость плюс регулярные проверки отказов.
Полезно заранее договориться о базовом наборе SLO-метрик:
Дополнительно полезны метрики «здоровья кворума»: сколько узлов доступно для чтения/записи, сколько запросов обслужено в деградированном режиме, сколько отклонено.
Настройте алерты не только на CPU/память, но и на симптомы распределённых проблем: всплеск таймаутов между узлами, рост ошибок межузлового RPC, резкое увеличение репликационной задержки, невозможность собрать кворум чтения и записи. Важно, чтобы алерт сразу показывал затронутые зоны/стойки/шарды.
Проверяйте сценарии, которые реально случаются: отключение узла, частичная потеря сети между зонами, деградация диска, «заморозка» GC/пауз на одном узле, рассинхрон часов. В тестах фиксируйте, что происходит с:
Делайте так, чтобы инцидент можно было разобрать по данным: журналы изменений (что, где и когда применилось), сквозная трассировка запросов и понятные постмортемы с действиями «что поменяем в конфигурации/алертах/тестах». Это снижает риск повторения и помогает честно управлять компромиссом C/A.
В контексте CAP согласованность — это гарантия, что чтения видят единое «текущее» значение (как будто база одна).
Это не про «валидность» данных (ограничения/нормализация), а про то, увидит ли клиент результат записи одинаково на разных узлах сразу после изменения.
Доступность в CAP означает: запрос к работающему узлу получает ответ (успех или контролируемую ошибку), даже если часть кластера недоступна.
Практически это про то, что сервис не зависает таймаутами и не превращается в «вечную загрузку» во время деградаций.
Partition (разделение сети) — когда кластер распадается на «острова», которые не могут обмениваться сообщениями.
В этот момент система вынуждена выбрать:
Потому что без P часто можно «и быстро, и точно» в пределах одного кластера, но при разделении сети гарантировать одновременно C и A невозможно.
CAP — не «выберите 2 из 3 навсегда», а правило поведения в аварийном режиме, когда связь между узлами ломается или становится односторонней/выборочной.
Кворумы задаются числами N (реплик), W (сколько подтверждений записи нужно), R (со скольких реплик читаем).
Практические ориентиры:
Eventual consistency уместна, когда задержка обновлений не ломает смысл:
Для денег, прав доступа, бронирований «последнего ресурса» лучше выделять путь со строгими гарантиями (или отдельный компонент/таблицу).
Типичный случай — параллельные записи одного поля/объекта на разных узлах во время задержек/разделения сети.
Частые стратегии:
Потому что при таймаутах запрос мог выполниться, а ответ — не дойти, и клиент делает ретрай.
Минимальный набор защиты:
Так повторы превращаются из «двойного списания» в управляемый сценарий.
PACELC напоминает: даже без аварий система выбирает между Latency (L) и Consistency (C).
Практика:
Выбирайте режимы чтения/записи , а не «одним флагом на всю систему».
Базовый набор, который стоит измерять:
И обязательно тестируйте отказы в staging: отключение узлов, частичную потерю сети между зонами, деградацию диска, «подвисание» узла (GC-паузы), рассинхрон часов.
Важно заранее решить, что делать при конфликте: авто-мердж, бизнес-правило, ручная обработка.