Рефакторинг прототипа в модули: поэтапный план очистки routes, сервисов, доступа к БД и UI, чтобы изменения были маленькими и легко откатывались.
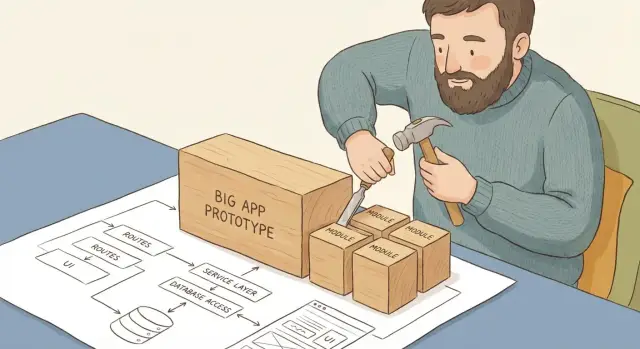
Прототип обычно держится на двух вещах: скорости и договоренности «потом разберемся». Пока функций мало, это работает. Но как только появляются новые экраны, роли пользователей, интеграции и первые реальные данные, прототип становится хрупким. Любая правка цепляет сразу несколько мест, и вы уже не уверены, что именно поменяли.
Чаще всего ломает одно: в прототипе смешано все сразу. Маршруты, проверки, бизнес-правила, запросы к базе и куски интерфейса живут рядом, иногда даже в одном файле. У изменений нет границ. Вы правите «одну мелочь», а случайно ломаете регистрацию, список заказов и админку.
Пора переходить к модульному рефакторингу, если вы замечаете такое:
Самая опасная реакция на эти симптомы - делать большой рефакторинг одним заходом. Он быстро превращается в длинную ветку, где одновременно меняют структуру, поведение и данные. В итоге сложно понять, что именно сломалось, и тяжело откатиться.
Надежнее цель попроще: маленькие шаги, понятные границы, легкий откат. Например, в прототип добавили скидки. Сначала скидка считается прямо в роуте, потом часть логики «переезжает» в UI, затем появляется второй тип скидок. Через неделю уже непонятно, где «истина». Если вместо переписывания всего вы сначала выделяете одну функцию расчета в services и подключаете ее без смены результата, появляется точка контроля. Дальше можно двигать остальное, не рискуя всей системой сразу.
Рост прототипа ломает не технологии, а отсутствие границ. Модульный подход возвращает границы так, чтобы каждое изменение было небольшим, проверяемым и обратимым.
Перед рефакторингом важно навести порядок не в коде, а в понимании: что сейчас работает, что считается правильным результатом и где вы готовы принять риск. Обычно на это уходит 1-2 часа, но экономит дни откатов и поисков ошибок.
Сначала опишите критичные сценарии простыми словами, как будто объясняете их новичку в команде. Не нужно покрывать весь продукт: выберите 5-10 действий, которые больнее всего ломать (вход, регистрация, создание сущности, оплата, выгрузка отчета, отправка уведомления). Для каждого сценария зафиксируйте ожидаемое поведение: что вводим, что должно появиться на экране, какие данные должны сохраниться.
Чтобы это было проверяемо, заведите короткий лист контроля по каждому сценарию. Достаточно:
Дальше сделайте «карту текущих зависимостей». Не идеальную архитектурную диаграмму, а честную заметку: какие routes дергают какие куски логики, где читается и пишется БД, какие UI-компоненты используются в нескольких местах. Часто хватает таблицы или схемы на листе. Смысл простой: чтобы при переносе файла вы понимали, что может отвалиться.
Параллельно выберите одну метрику прогресса, чтобы не спорить «стало лучше или нет». Лучше всего работают измеримые вещи: меньше прямых обращений из routes в БД, меньше дублирующихся запросов, меньше «божественных» компонентов в UI, больше функций, которые можно проверить отдельно.
И последнее - заранее решите, куда вы временно не лезете (scope freeze). Например: не меняем схему БД, не трогаем внешний вид экранов, не переписываем авторизацию, не улучшаем производительность. Это защищает от ситуации, когда рефакторинг незаметно превращается в «давайте заодно все поправим».
Короткое правило: на этапе подготовки вы фиксируете факты и проверки, а не придумываете новую архитектуру. Так появляется безопасный коридор, в котором дальнейшие изменения остаются маленькими и обратимыми.
Минимальный риск в рефакторинге - это не про скорость, а про контроль. Вы меняете как можно меньше за раз, чтобы всегда понимать, что именно сломалось (если сломалось) и как быстро вернуться назад.
Хорошая единица работы - шаг, который можно проверить руками за 5-10 минут. Например: перенесли обработчик в отдельный файл без изменения логики или переименовали папку и поправили импорты. Если шаг нельзя быстро проверить, он слишком большой.
Помогает простое правило: сначала перенос кода, потом изменения поведения. Если одновременно и переставлять файлы, и менять логику, вы теряете причину ошибок.
Обратимость нужна не только на случай «катастроф», но и для обычной усталости команды: поздно, нет времени, всплыли неожиданные зависимости. Используйте приемы, которые позволяют быстро выключить новое и включить старое.
Рабочие варианты:
На практике это выглядит так: вы переносите бизнес-логику из routes в services. Сначала создаете сервис и вызываете его из старого route, не меняя входы и выходы. Только после того как проверки проходят, упрощаете route и чистите дубли.
Опаснее всего начинать с «наведем порядок», не договорившись о границах. Сначала зафиксируйте контракты: какие поля принимает обработчик, что возвращает, какие ошибки возможны, где транзакция, где валидация. Это можно оформить хотя бы коротким комментарием или простыми структурами запроса и ответа.
Перед каждым этапом заранее ответьте на два вопроса: «Где откатиться?» и «Когда остановиться?». Критерий остановки - понятный сигнал, что дальше нельзя продолжать сегодня: растет число багов, появляются непонятные зависимости, ручная проверка занимает слишком много времени. В этот момент лучше зафиксировать рабочее состояние и продолжить меньшим шагом завтра.
Цель здесь не в «идеальной архитектуре», а в понятных границах и предсказуемых изменениях. Практичная базовая схема - четыре слоя: вход (routes), логика (services), данные (data/db), представление (ui). Так быстрее видно, где что живет, и легче заметить места, где слои начинают «тянуть» друг друга.
Начните с минимального каркаса, который можно расширять:
/src
/routes # обработчики входа: HTTP/RPC, валидация, маппинг
/services # бизнес-правила, сценарии, оркестрация
/data
/db # репозитории, запросы, транзакции
/migrations # миграции и сиды
/ui # компоненты, страницы, адаптеры к API
/shared # общие типы, небольшие утилиты
Границы модулей можно резать по слоям или по фичам. По слоям проще стартовать, но со временем есть риск, что одна фича будет размазана по папкам. По фичам удобнее поддерживать продукт (например, /features/auth, /features/billing), но переходить на это лучше после того, как базовые слои стали чистыми.
Часто работает компромисс: верхний уровень по слоям, а внутри services и ui группировать по фичам. Например, services/user, services/orders, ui/orders.
Чтобы изменения были безопаснее, определите «публичный контракт» каждого модуля: что другим разрешено использовать напрямую. Обычно это интерфейсы сервисов, типы входа-выхода, события или результаты операций и список ошибок, которые модуль обещает отдавать наружу. Все остальное - внутренности, их можно менять без каскада правок.
Отдельная ловушка - папка shared. Она нужна, но туда легко начать складывать «все подряд». Держите там только маленькие, очевидные вещи: простые функции без зависимостей, общие типы, базовые валидаторы. Если утилита тянет БД, сеть или UI, ей место в своем слое.
На первом этапе цель простая: сделать маршруты понятными и предсказуемыми, не меняя результат для пользователя. Это безопасный вход в рефакторинг, потому что вы трогаете в основном «провода», а не правила.
Сначала зафиксируйте список всех маршрутов и сгруппируйте их по фичам, а не по методам (GET/POST) и не по принципу «как исторически сложилось». Обычно хватает 4-8 групп: auth, users, billing, projects, admin. Уже на этом шаге видны дубли и странные исключения.
Дальше сделайте минимальный перенос: обработчики переезжают в отдельные файлы, но код внутри не переписывается. Меняется только то, где он лежит и как подключается.
Удобный безопасный ритм такой: составили таблицу «маршрут, метод, вход, выход, где лежит код», перенесли один обработчик, проверили 2-3 критичных сценария, пошли дальше.
Когда обработчики разложены по фичам, добавьте тонкую валидацию и нормализацию входа. Речь не про «переписать все на сложные типы», а про базовую защиту от мусора: trim для строк, дефолты для пагинации, проверка обязательных полей.
Следующий шаг - единый формат ошибок и ответов. Прототипы часто отвечают то строкой, то объектом, то 500 на любую проблему. Сделайте маленький контракт и соблюдайте его везде, даже если внутри все еще «как раньше».
Пример простых договоренностей:
Если боитесь сломать клиентов, держите старый и новый путь параллельно, но ограниченное время. Самый безопасный вариант - оставить старый URL, а внутри направить его на новый handler.
Критерий готовности к следующему этапу: маршруты сгруппированы по фичам, обработчики лежат отдельно, есть минимальная валидация, ответы и ошибки имеют один формат, а откат возможен простым возвратом регистрации маршрута на старый handler.
Теперь цель такая: routes (или контроллеры) перестают быть местом, где «делается все сразу». Они принимают запрос, проверяют базовые вещи (например, что пользователь авторизован), вызывают сервис и возвращают ответ.
Оставляйте в route: разбор входных данных, проверку формата (тип, обязательность полей), маппинг во внутренний формат, выбор HTTP-кода и формат ответа. Переносите в сервис: проверки «по смыслу» (можно ли пользователю сделать действие), расчеты, сценарии (создать сущность, обновить, отправить уведомление), координацию нескольких операций.
Если у вас есть «функция-гигант», режьте ее не по папкам, а по шагам сценария. Начните с самого безопасного куска, который легко проверить: расчет суммы, применение промокода, определение статуса. Затем переносите следующий шаг. Важно, чтобы на каждом маленьком переносе результат для пользователя оставался тем же.
Полезный прием - сразу отделять внешние зависимости (почта, платежи, файлы, сторонние API) через интерфейсы. Тогда сервис можно проверять отдельно, а конкретные реализации подключать снаружи.
Чтобы контракты не «поплыли», для каждого сервиса зафиксируйте:
База данных часто становится источником скрытых поломок, потому что в прототипе SQL или ORM-вызовы разбросаны по handlers, фоновых задачах и иногда даже по UI. Первое правило на этом этапе: у данных должен быть один вход.
Сделайте единый слой доступа к данным: репозитории или тонкие обертки над запросами. Не нужно сразу придумывать сложную архитектуру. Достаточно договориться, что весь код чтения и записи живет в одном пакете или модуле, а остальной код вызывает его как обычные функции.
Начните со «сборки» запросов без изменения поведения. Вы не оптимизируете SQL и не меняете схему. Вы просто переносите запросы из разных мест в один слой и даете им понятные имена.
Хороший признак прогресса: в routes/handlers больше нет прямых SQL-строк и ручного маппинга результатов. Там остается вызов репозитория и обработка ошибок.
Переносите по одному сценарию за раз (например, «создать заказ» или «обновить профиль») и после каждого шага прогоняйте те же проверки.
В прототипах часто бывает либо «везде транзакция», либо «нигде». Оба варианта дают сюрпризы. Добавляйте транзакционные границы только вокруг операций, которые должны пройти вместе.
Транзакция почти всегда оправдана, если в одном действии есть запись в несколько таблиц, чтение+запись с ожиданием согласованного результата, списание баланса или важные инварианты (например, статус заказа и история статусов).
Менять схему безопаснее приемом «сначала совместимость, потом переключение». Например, хотите заменить поле phone на phone_e164. Тогда:
Так вы сохраняете обратную совместимость и уменьшаете риск.
UI часто кажется «самым безопасным» местом, но именно здесь легко сломать привычные сценарии. Поэтому цель этапа не в том, чтобы сразу построить дизайн-систему, а в том, чтобы аккуратно выделить повторяющиеся элементы и договориться о простых правилах.
Первый шаг - разделить «умные» и «глупые» компоненты. «Умный» компонент знает, откуда берутся данные, когда дергать запрос, что делать при ошибке. «Глупый» компонент получает данные через props и только рисует интерфейс. Так внешний вид можно менять без риска задеть бизнес-логику.
Дальше ищите повторения, но начинайте с того, что встречается чаще всего: кнопки, поля ввода, подсказки об ошибках, модальные окна. Выносите по одному элементу за раз. Хорошая тактика - оставить старые вызовы, но заменить внутреннюю реализацию.
Для постепенной стандартизации хватает нескольких договоренностей: 2-3 размера отступов, единые состояния кнопок (обычная, disabled, loading), базовые цвета (фон, текст, ошибка, акцент), стандарт для форм (подпись, поле, сообщение об ошибке).
Делайте UI-изменения маленькими порциями: сегодня заменили все «кнопки сохранения» на новый компонент, завтра - поля ввода на одном экране. После каждого шага быстро проверяйте ключевые сценарии (логин, создание записи, сохранение, отмена).
Отдельно про состояние: не пытайтесь тащить все в глобальный стор. Локально держите то, что живет только в одном компоненте (вкладки, модалки). Общие данные (например, текущий пользователь) можно вынести выше. То, что является источником истины на сервере (списки, карточки), лучше подтягивать запросами. А фильтры и пагинацию полезно держать в URL, чтобы можно было поделиться состоянием.
Провалы чаще происходят не из-за сложности кода, а из-за масштаба шага. Когда прототип уже приносит пользу, рефакторинг должен выглядеть как серия маленьких, почти скучных изменений, которые легко проверить и так же легко отменить.
Желание «навести порядок раз и навсегда» обычно заканчивается тем, что вы неделями живете в ветке, а в конце получаете конфликты, незаметные регрессии и усталость.
Частые ловушки:
Почти все это начинается как «маленькая хитрость ради скорости»: временно дернуть БД прямо из UI или из роутера, а потом забыть и не найти месяцами.
Если вы не знаете, как быстро вернуть прошлое состояние, вы начинаете принимать рискованные решения. Перед каждым этапом держите два пункта: как проверить, что ничего не сломалось (несколько сценариев руками, пара простых тестов или хотя бы фиксация ожидаемых ответов), и как откатить.
Практический прием: переносите логику из routes в services через тонкую обертку. Если после релиза всплывает проблема, вы возвращаете вызов назад без каскадных правок.
Еще один сигнал «стоп»: вы начали спорить об «идеальной» структуре, но не можете объяснить, какую конкретную боль она снимает уже завтра. В рефакторинге лучше выиграть надежность и понятность, чем красоту схемы.
Успех обычно зависит не от архитектурных схем, а от привычки делать маленькие шаги и сразу проверять результат.
Перед каждым мини-этапом зафиксируйте одну цель и один критерий «все ок». Например: «вынести бизнес-правила из route в service, поведение ответа не меняем». Дальше держите простой ритм: меняете только одну зону (routes или services или db или ui), заранее фиксируете, что должно остаться неизменным (статусы, поля, тексты ошибок), делаете точку отката, прогоняете 3-5 ключевых сценариев, ограничиваете шаг по времени (например, 1-2 часа).
После шага не «протыкайте руками где получится», а пробегите те же сценарии. Если что-то сломалось, откатывайтесь сразу, фиксируйте причину и возвращайтесь с меньшим изменением.
Пример из жизни: был прототип интернет-сервиса. Через месяц добавления функций стало страшно трогать код: один route тянет запросы к БД, там же правила скидок, там же куски верстки. Фича «добавить промокод» превращается в риск. Дальше помогает только последовательность: сначала тонкие routes, затем правила в services, затем единый слой db-доступа и аккуратные миграции, и только потом - стандартизация UI.
Если вам важны быстрые точки возврата, их удобно делать на платформе TakProsto (takprosto.ai) за счет снапшотов и rollback, а planning mode помогает заранее разложить маленькие шаги рефакторинга.
Дальше стоит завести регулярную «малую чистку» в план разработки: короткие сессии после каждой 1-2 фич, а не один большой рефакторинг раз в полгода. Тогда модули появляются естественно, и прототип не превращается обратно в комок.
Обычно ломается не «технология», а отсутствие границ: в одном месте смешаны маршруты, бизнес-правила, запросы к БД и UI. Тогда любая правка цепляет сразу несколько частей, и вы теряете контроль над тем, что именно изменили.
Если мелкие задачи стали занимать заметно больше времени из‑за страха «где это еще используется», баги всплывают «не там, где правили», правила копируются в разных местах, файлы разрастаются, а логику тяжело проверить отдельно — пора переходить на модульные шаги.
Сначала зафиксируйте факты:
Это дает «коридор безопасности», чтобы дальше менять код маленькими шагами.
Делайте шаг такого размера, который проверяется за 5–10 минут. Практичное правило: сначала перенос/выделение кода без изменения поведения, потом изменение поведения. Так вы всегда понимаете причину поломки и можете быстро вернуться назад.
Самые рабочие варианты:
Главная цель — возможность быстро отключить новое без каскадных переделок.
Потому что один «большой» рефакторинг почти неизбежно смешивает перестановку файлов, смену логики и изменения данных. В итоге сложно локализовать причину регрессии, растет конфликтность в ветке и дорожает откат. Надежнее серия маленьких, проверяемых переносов с понятными границами.
Оставляйте в routes/контроллерах:
Переносите в services:
Так маршруты становятся «проводами», а логика — проверяемой отдельно.
Соберите все чтение/запись в один слой (репозитории или набор функций) и уберите SQL/ORM‑вызовы из handlers и фоновых задач. Двигайтесь по одному сценарию (например, «создать заказ») и после каждого переноса прогоняйте те же проверки. Хороший признак: в routes нет SQL‑строк, только вызовы репозитория и обработка ошибок.
Делайте изменения «сначала совместимость, потом переключение»:
Это снижает риск, потому что старый код еще может жить рядом с новым.
Разделяйте компоненты на «умные» (где данные, запросы, обработка ошибок) и «глупые» (только рендер через props). Стандартизируйте постепенно: вынесли один повторяющийся элемент (кнопку/инпут/ошибку), заменили в одном месте, прогнали ключевые сценарии, пошли дальше. Не тащите все в глобальный стор: локальное состояние — локально, серверные данные — через запросы, фильтры/пагинацию — удобно держать в URL.