Разбираем REST Роя Филдинга: 6 ограничений, зачем они нужны и как влияют на дизайн современных API и веб‑приложений. С примерами и ошибками.
REST часто упоминают как «стиль API», но исторически это скорее объяснение того, почему веб вообще работает так хорошо. Когда вы открываете страницу в браузере, переходите по ссылкам, обновляете вкладку или делитесь URL — вы пользуетесь принципами, которые Рой Филдинг сформулировал и описал в своей диссертации. Она важна не потому, что «придумала HTTP», а потому что разложила успешную веб‑архитектуру на понятные ограничения и показала: совместимость и масштабируемость — следствие дисциплины.
Филдинг — один из участников разработки спецификаций HTTP и URI, а также автор термина REST (Representational State Transfer). Его вклад — не новый протокол, а архитектурная рамка: набор ограничений, которые помогают системам эволюционировать без постоянных «переписываний с нуля».
REST не равен JSON, не равен «эндпоинты + GET/POST» и уж точно не сводится к модному названию. Это набор договорённостей о том, как клиент и сервер взаимодействуют, как передаётся состояние, что можно кэшировать, как устроен единый интерфейс и почему посредники (прокси, шлюзы, кэши) не ломают систему, а помогают ей.
Дальше пройдёмся по ограничениям REST по одному, обсудим практические выводы для дизайна API, а затем разберём типовые ошибки «REST‑подобных» интерфейсов и чек‑лист, который можно применить к вашему проекту.
REST особенно хорош там, где важны предсказуемость, масштабирование и долгий срок жизни интерфейса: публичные API, интеграции, большие веб‑системы. Но для некоторых задач (например, высокочастотный обмен событиями или строго типизированные внутренние вызовы) он может оказаться избыточным — и это нормально, если решение принято осознанно.
REST Филдинга вырос не из «API для мобильных приложений», а из понимания веба как распределённой гипермедиа‑системы: множество независимых участников обмениваются сообщениями, переходят по ссылкам и постепенно меняют состояние «сессии» на стороне клиента.
Ресурс — это любая осмысленная сущность, которую можно назвать и адресовать: заказ, статья, список задач, профиль, поисковый запрос, даже «текущие рекомендации». Важно, что ресурс — это концепция. Он не равен таблице в базе и не обязан быть «объектом» в коде.
Идентификатор (URI) — стабильное имя ресурса в сети. URI отвечает на вопрос «где искать смысл», но не «в каком формате он будет показан». Один и тот же ресурс может иметь один URI и разные представления.
Клиент и сервер обмениваются не ресурсами напрямую, а их представлениями (representation): конкретными байтами в конкретном формате.
Формат описывается медиатипом (Content-Type): application/json, text/html, image/png и т.д. Поэтому JSON — лишь один из вариантов представления, удобный для программных клиентов, но не «сердце REST».
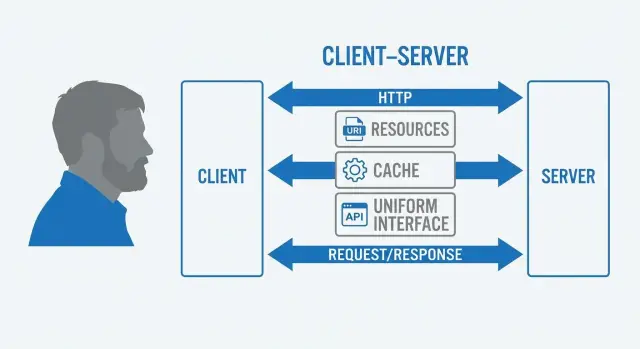
HTTP важен не только тем, что «по нему ходят запросы». Он задаёт базовую семантику взаимодействия: методы (GET/POST/PUT/DELETE), коды ответа, заголовки (кэширование, согласование форматов через Accept), правила для прокси и промежуточных узлов.
Гипермедиа означает, что сервер ведёт клиента дальше ссылками и формами внутри представлений: «вот где следующий шаг», «вот как отменить заказ», «вот куда оплатить». Клиенту не нужно заранее «знать все пути» — он может ориентироваться по полученным ссылкам.
Отсюда и типичное заблуждение: «REST = JSON по HTTP». JSON по HTTP может быть и RPC в новом костюме, если всё построено вокруг методов вроде /doSomething, отсутствуют осмысленные ресурсы, медиа‑типы и навигация через ссылки.
REST у Филдинга — не «набор эндпоинтов» и не чек‑лист HTTP‑методов. Это система архитектурных ограничений, которые вместе создают предсказуемый стиль взаимодействия компонентов в вебе. Смысл ограничений в том, чтобы упростить эволюцию системы: менять сервер, клиент, кэш или прокси независимо, не ломая всё сразу.
Ограничения уменьшают свободу «сделать как удобнее прямо сейчас», но взамен дают:
В «классическом» REST шесть ограничений:
При этом code-on-demand опционально.
Важно: это не независимые правила. Например, stateless и кэшируемость усиливают друг друга: когда каждый запрос самодостаточен, его проще кэшировать и анализировать промежуточным узлам. А единый интерфейс (стандартизованные семантики взаимодействия) делает возможной «инфраструктуру между» клиентом и сервером.
Нарушая ограничения, вы обычно покупаете локальное удобство ценой системных потерь: появляются скрытые сессии, «магические» заголовки, нестабильные контракты, невозможность безопасного кэширования, сложность диагностики через прокси и шлюзы.
Ищите не «как правильно назвать эндпоинт», а какую проблему веба решает каждое ограничение и какие компромиссы оно навязывает. Полезный приём: после каждого раздела отвечать на два вопроса — «что это даёт системе?» и «что станет невозможным/дорогим без этого?».
Ограничение «клиент–сервер» — это про разделение ответственности: интерфейс и взаимодействие с пользователем живут на стороне клиента, а данные, бизнес‑правила и доступ к хранилищам — на стороне сервера. В REST это не просто удобство разработки, а способ уменьшить связанность частей системы.
Клиент отвечает за отображение, навигацию, сбор ввода и локальные UX‑решения (например, валидацию «похоже на e‑mail»). Сервер отвечает за «истину»: аутентификацию и авторизацию, проверку прав, правила предметной области, сохранение и выдачу ресурсов.
Такое разделение помогает не смешивать задачи: клиент не должен знать, как устроены таблицы в базе или какие микросервисы дергаются внутри, а сервер — не должен быть привязан к конкретным экранам и компонентам интерфейса.
Когда граница проведена правильно, вы можете менять одну сторону почти независимо от другой:
Именно здесь REST выигрывает «в долгую»: система становится более сопровождаемой, потому что изменения локализуются.
Представьте API каталога: GET /products и GET /products/{id}. Команда клиента выпускает новый экран с фильтрами и сортировкой, используя те же ресурсы и добавив параметры запроса. Параллельно команда сервера выпускает оптимизацию выдачи и новую схему хранения. Если контракт ресурсов не сломан (форматы, статусы, семантика), релизы можно выкатывать отдельно — без синхронного «большого взрыва».
Перекосы обычно бывают в две стороны.
1) «Сервер рендерит всё». Это само по себе не запрещено, но часто приводит к ситуации, когда сервер начинает быть «в курсе» экранов: эндпоинты делаются под конкретные страницы, смешиваются данные и представление, а API становится неудобным для других клиентов.
2) «Клиент знает слишком много». Например, клиенту приходится собирать бизнес‑операцию из десятка вызовов, он повторяет правила расчета скидок или статусы процесса. В итоге логика размножается по приложениям, а любое изменение правил требует обновлять всех клиентов.
Практичный ориентир: клиенту достаточно понимать ресурсы и допустимые действия, а серверу — обеспечивать корректность и целостность.
Stateless в REST — это не про «сервер ничего не хранит вообще», а про то, что сервер не хранит состояние взаимодействия с клиентом между запросами. Каждый запрос должен быть самодостаточным: чтобы обработать его, серверу не нужно помнить, что было «в прошлый раз» именно с этим клиентом.
Запросы не зависят от скрытого контекста, созданного предыдущими запросами. Если вы отправили GET /orders/123, то результат не должен меняться только потому, что ранее вы открывали «корзину» или «страницу оформления».
При этом сервер может хранить состояние ресурсов (например, заказ в базе данных). Запрещено хранить состояние сессии как обязательное условие для понимания следующего запроса.
Чтобы запрос был самодостаточным, в нём обычно передают:
Authorization: Bearer …);Stateless упрощает горизонтальное масштабирование: любой запрос может обработать любой экземпляр сервиса за балансировщиком, без «прилипания» клиента к конкретному серверу. При падении узла меньше рисков потерять «память» о том, на каком шаге находится пользователь.
Частая ловушка — API, которое требует предварительного «логина», после которого сервер кладёт в сессию права, выбранную организацию, корзину или этап оформления. Клиент начинает зависеть от cookie/идентификатора сессии, а запросы перестают быть переносимыми и повторяемыми.
Вместо серверных сессий используют токены (JWT или непрозрачные access token), которые клиент отправляет в каждом запросе.
Для надёжности операций полезно проектировать идемпотентные методы там, где это ожидается (PUT/DELETE), а для повторов POST — принимать Idempotency-Key.
Для наблюдаемости и поддержки добавляйте X-Correlation-Id (или traceparent): тогда цепочку запросов проще отследить в логах и при разборе инцидентов.
Кэш в вебе — это не «оптимизация по желанию», а часть архитектуры. Он сокращает задержки (ответ приходит ближе к пользователю), снижает нагрузку на серверы и сети, а ещё повышает устойчивость: при кратковременных сбоях клиенты и промежуточные узлы могут использовать уже полученные данные.
Кэшируемость в REST опирается на стандартные механизмы HTTP.
Cache-Control задаёт правила хранения и «свежести» ответа: например, max-age (сколько секунд считать ответ актуальным), public/private (можно ли хранить на общих прокси), no-store (вообще не сохранять) и must-revalidate (после истечения срока обязательно перепроверять).
ETag + If-None-Match — надёжный способ валидации. Сервер отдаёт ETag (идентификатор версии представления), а клиент при следующем запросе присылает его в If-None-Match. Если ничего не изменилось, сервер отвечает 304 Not Modified без тела — быстро и дёшево.
Last-Modified + If-Modified-Since — более простой (и менее точный) вариант: проверка по времени последнего изменения.
Обычно хорошо кэшируются GET‑запросы к справочникам, публичным карточкам, спискам категорий, конфигурации, документации. Осторожность нужна, когда данные персональные, зависят от прав доступа, географии, A/B‑варианта или динамических параметров.
Опасный случай: ответ выглядит одинаково по URL, но фактически зависит от заголовков (например, Authorization, языка или роли). Тогда кэш «перемешает» пользователей. Выход — либо не кэшировать, либо явно учитывать вариативность через Vary и корректные private/public.
Самые популярные анти‑паттерны:
max-age даёт «устаревшую правду», слишком короткий — убивает смысл кэша.Кэширование должно ускорять систему, не ломая доверие к данным. Если ресурс критичен к актуальности (балансы, статусы заказов, права доступа), лучше выбрать короткий TTL и ставку на валидацию (ETag/304), чем пытаться «выжать скорость» ценой ошибок.
Единый интерфейс — самая «дорогая» часть REST: ради него вы отказываетесь от удобных на первый взгляд «специальных» эндпоинтов и дисциплинируете API. Зато выигрыш долгосрочный: клиент и сервер меньше зависят друг от друга, проще развивать систему и подключать новые клиенты.
В REST адресуют сущности, а не действия. Поэтому предпочтительнее:
/users/42 вместо /getUser?id=42/orders/2025-00031 вместо /createOrder или /updateOrderStatusГлагол «что сделать» переезжает в HTTP‑метод, а URI остаётся стабильным идентификатором ресурса.
Клиент отправляет представление ресурса (JSON, XML и т. п.), а сервер применяет изменения.
POST /orders — создать новый заказ (сервер назначает идентификатор).PUT /users/42 — заменить ресурс целиком (полная версия представления).PATCH /users/42 — изменить часть полей (частичное представление/патч).Важно, что смысл операции читается из комбинации «метод + ресурс», а не из имени эндпоинта.
Сообщение должно быть понятным без «тайных договорённостей»:
Content-Type, Accept, Cache-Controlcode, message, details)Это снижает количество неявных правил в SDK и документации.
Идея гипермедиа: сервер подсказывает клиенту допустимые следующие шаги ссылками в ответах. Тогда клиент меньше «зашит» в конкретные маршруты.
Например, в ответе на /orders/2025-00031 можно вернуть ссылки вроде cancel, pay, items. Если бизнес‑правила меняются, клиенту часто достаточно следовать новым ссылкам, а не переписывать логику маршрутизации.
Слоистая система в REST означает, что клиент не обязан знать, общается ли он напрямую с «вашим» сервером или через цепочку промежуточных узлов. Для клиента это один и тот же единый интерфейс и те же правила взаимодействия.
Промежуточные компоненты решают прикладные задачи, не меняя смысл API. Прокси и шлюзы могут завершать TLS, добавлять защитные проверки, нормализовать заголовки. Балансировщики распределяют нагрузку по нескольким инстансам сервиса. CDN и обратные прокси ускоряют выдачу за счёт кэша и приближения контента к пользователю.
Ключевая идея: каждый слой добавляет ценность (скорость, безопасность, доступность), но не должен ломать контракт клиента с API.
Слои позволяют изолировать внутреннюю инфраструктуру: внешний мир видит один вход (например, API‑gateway), а реальные сервисы могут меняться, масштабироваться и мигрировать без изменения клиентского кода. На стороне безопасности это даёт единые точки контроля: rate limiting, WAF‑правила, проверка токенов, аудит, корреляция запросов.
Минусы тоже реальны. Отладка усложняется: ответ мог быть закэширован CDN, модифицирован прокси, сжат/распакован, или получил дополнительные заголовки. Опаснее всего «тихие трансформации»: переписывание URL, изменение кодировки, обрезка заголовков, автоматическая подмена статусов ошибок.
Добавляйте слой так, чтобы внешние URL, методы, коды ответов и семантика ресурсов не менялись. Если требуется новая политика (например, лимиты), возвращайте предсказуемые ошибки и документируйте их. Не заставляйте клиентов «угадывать», кэшируется ли ответ: используйте Cache-Control, ETag, Vary.
Опишите «путь» запроса: клиент → gateway → сервис, и какие заголовки обязательны на каждом участке (Authorization, Accept, Content-Type, Cache-Control). Хорошая практика — сквозной идентификатор запроса (например, X-Request-Id) и правила, где он создаётся и как прокидывается дальше. Это экономит часы при разборе инцидентов и спорных кейсов с кэшем.
Code-on-demand — это единственное ограничение REST, которое не обязательно выполнять. Его смысл в том, что сервер может временно расширять возможности клиента, доставляя ему исполняемый код, который запускается на стороне пользователя.
Самый понятный пример — веб‑страницы, которые загружают скрипты и выполняют их в браузере. Сервер отдаёт не только данные, но и логику поведения интерфейса: валидацию формы, динамическую подгрузку контента, обработку событий.
Главное преимущество — гибкость. Если часть логики «приезжает» с сервера, то обновление поведения клиента может происходить без установки новой версии приложения. Это удобно, когда:
За гибкость приходится платить:
В контексте API code-on-demand чаще не нужен. Если ваша цель — предсказуемый обмен данными между сервисами и клиентами, обычно лучше отдавать данные и контракты, а не исполняемую логику. Особенно стоит избегать этого подхода в интеграциях с повышенными требованиями к безопасности и в B2B‑API, где важнее стабильность и прозрачность поведения.
Термин «REST» часто используют как синоним «HTTP API с JSON». На практике это разные вещи: REST — не формат и не набор эндпоинтов, а соблюдение набора ограничений, которые дают предсказуемую эволюцию, кэширование и слабую связность между клиентом и сервером.
REST особенно хорошо работает там, где вы оперируете ресурсами и их состояниями:
Есть задачи, где REST будет не самым удобным:
Важно: выбрать не «правильное слово», а подход, который снижает стоимость поддержки.
Спросите себя:
Нужно ли кэширование и условные запросы как часть дизайна (а не как костыль)?
Должны ли клиенты обновляться независимо от сервера, без постоянных правок контрактов? Тогда ценность REST‑принципов (единый интерфейс, понятные семантики методов, предсказуемые статусы) резко возрастает.
Насколько тесно клиент должен знать внутренние «команды» сервера? Чем больше таких знаний, тем ближе вы к RPC.
«REST‑подобный» API обычно использует HTTP и JSON, но нарушает часть ограничений: например, хранит состояние на сервере между запросами, прячет кэшируемость или превращает URL в набор глаголов (/createUser, /doPayment).
Это не «плохо» само по себе: иногда так дешевле стартовать. Риск в другом — со временем такие интерфейсы сложнее масштабировать, версионировать и поддерживать несколькими командами. Хорошая практика — честно зафиксировать, какие ограничения вы сознательно не соблюдаете и почему, чтобы «REST» не превращался в маркетинговую наклейку.
REST чаще всего «ломают» не из злого умысла, а потому что удобнее быстро «сделать, чтобы работало». Ниже — ошибки, которые потом дороже всего исправлять, и практичные способы их избежать.
Частая проблема — описывать действия вместо ресурсов.
Плохо: /getUser, /createOrder, /users/123/activate.
Лучше: думать существительными и коллекциями: /users/123, /orders, /users/123/status.
Если действие действительно нужно (например, «подтвердить»), оформляйте его как под‑ресурс или как создание ресурса‑события: POST /orders/123/confirmations.
POST нередко превращают в «универсальную кнопку». Это лишает клиентов предсказуемости и ломает кэширование.
GET — только чтение, без побочных эффектов (и тогда его можно кэшировать).PUT — полностью заменить ресурс по URI.PATCH — частично обновить ресурс.DELETE — удалить ресурс.Если вы всегда используете POST, вы сами отказываетесь от встроенных правил HTTP.
Код ответа — это контракт. Минимальный набор, который стоит дисциплинированно использовать: 200/201/204, 400, 401, 403, 404, 409, 422, 429, 500.
Ошибки лучше возвращать в одном формате (например, code, message, details, request_id), чтобы клиент мог одинаково обрабатывать проблемы во всех эндпоинтах.
Версия нужна, когда вы ломаете обратную совместимость. Старайтесь сначала делать «мягкие» изменения: добавлять поля, не менять смысл существующих.
Если всё‑таки нужно ломать контракт — используйте явное версионирование (часто через префикс /v2/…) и план миграции: срок поддержки старой версии, предупреждения в ответах, понятная страница /docs.
Не путайте аутентификацию (кто вы) и авторизацию (что вам можно). Даже при наличии токена проверяйте права на каждый ресурс.
Отдельный риск — утечки через кэш и логи:
Cache-Control: no-store.request_id для расследований.Эти правила делают API предсказуемее для клиентов и дешевле в поддержке для команды.
Перед релизом полезно быстро проверить, не «сломали» ли вы REST в самых важных местах. Ниже — практичный список, который можно прогнать за час на ревью, а затем закрепить в Definition of Done.
Клиент–сервер: UI и бизнес‑логика не перемешаны. Клиент не должен знать про таблицы/внутренние сервисы, а сервер — про детали экранов.
Stateless (без состояния): каждый запрос самодостаточен — авторизация, локаль, версия API, контекст. Сервер не рассчитывает на «предыдущий шаг».
Кэшируемость: ответы, которые можно кэшировать, реально кэшируются (Cache-Control/ETag/Last-Modified), а приватные данные помечены как некэшируемые.
Единый интерфейс: ресурсы названы как сущности, а не как действия; HTTP‑методы используются по назначению; форматы ответов стабильны; переходы между связанными ресурсами предсказуемы.
Слоистая система: клиенту всё равно, общается ли он с приложением напрямую, через шлюз, CDN или прокси; аутентификация/лимиты/логирование могут быть отдельным слоем.
Code‑on‑demand (опционально): если вы отдаёте исполняемый код (например, скрипты), это не ломает безопасность и не делает поведение клиента непредсказуемым.
Сведите улучшения к метрикам:
Если хотите углубиться в практику дизайна API и примеры ошибок, загляните в /blog.
Если вы делаете продукт и вам нужен быстрый путь от идеи до работающего сервиса, принципы REST удобно проверять на практике в TakProsto.AI: платформа для vibe-coding позволяет через чат собрать веб‑интерфейс на React, бэкенд на Go и PostgreSQL, а затем экспортировать исходники, развернуть и хостить проект в России. В том числе полезны «снапшоты» и откат (rollback), а также planning mode — чтобы заранее согласовать ресурсную модель, статусы и ошибки до того, как они «зацементируются» в клиентах.
А если вы выбираете план для внедрения и поддержки процессов разработки, следующий шаг — /pricing. "
REST — это архитектурный стиль, описывающий, почему веб масштабируется и остаётся совместимым. Он задаёт набор ограничений (client-server, stateless, cache, uniform interface, layered system и опционально code-on-demand), которые вместе делают взаимодействие предсказуемым и эволюционирующим.
Если у вас просто «HTTP + JSON + эндпоинты», это может быть RPC под видом REST.
Рой Филдинг — соавтор спецификаций HTTP и URI и автор термина REST. Его вклад в том, что он формализовал успешные свойства веба как набор ограничений и показал, какие компромиссы дают масштабируемость и совместимость.
Для практики это полезно как «карта причин»: что именно ломается, когда вы нарушаете одно из ограничений.
Ресурс — это именуемая сущность (концепция), которую можно адресовать: заказ, пользователь, корзина, поиск, рекомендации. Он не обязан совпадать с таблицей в БД или классом в программировании.
Хорошая проверка: ресурс имеет устойчивый URI и может иметь разные представления (например, JSON/HTML).
Представление (representation) — это конкретный формат данных, которые вы передаёте по сети: байты + медиатип (Content-Type). Один и тот же ресурс может отдаваться разными представлениями.
Практически: определите медиатипы, договоритесь о полях/ошибках и используйте Accept/Content-Type для согласования форматов.
Stateless означает: сервер не хранит состояние взаимодействия (сессии) между запросами; каждый запрос самодостаточен. При этом состояние ресурсов (данные заказа в БД) хранить можно.
На практике это обычно требует:
Authorization);Idempotency-Key для повторов POST).Кэшируемость снижает задержки и нагрузку, а также помогает переживать краткие сбои. В HTTP это делается стандартными механизмами, а не «самодельными флагами».
Минимальный набор:
Cache-Control с понятным TTL;ETag + для ответов ;Единый интерфейс — это дисциплина: адресуем сущности (URI), используем семантику HTTP-методов и стандартизируем ответы/ошибки. Главный выигрыш — слабая связанность: клиенту меньше нужно знать о внутренних «командах» сервера.
Практически:
/createOrder);GET/POST/PUT/PATCH/DELETE по назначению;Гипермедиа — это когда сервер подсказывает допустимые следующие шаги ссылками и формами в ответах. Клиент меньше «зашит» в маршруты и может следовать тому, что вернул сервер.
Даже частичная польза возможна без «идеального HATEOAS»:
items, payment, cancel);Слоистость означает, что между клиентом и сервисом могут быть прокси, шлюзы, балансировщики, CDN — и это не должно менять семантику API.
Чтобы слои не ломали контракт:
REST особенно хорош для публичных API, интеграций и долгоживущих систем с ресурсной моделью и выгодой от HTTP-кэша. REST может быть избыточен для:
Критерий: если вам важны независимые релизы клиентов/сервера и предсказуемая эволюция — REST-ограничения окупаются.
If-None-Match304 Not ModifiedVary, если ответ зависит от заголовков (язык, авторизация и т. п.).Authorization, Accept, Content-Type);X-Request-Id/traceparent) для отладки.