Русскоязычный поиск часто ошибается из-за морфологии и опечаток. Даем примеры запросов для ИИ и простой способ проверять релевантность.
Проблема обычно простая: человек вводит понятный запрос, а в первых результатах видит "почти то", но не то. Он редко будет переформулировать запрос пять раз. Чаще он уйдет или напишет в поддержку. Поэтому релевантность на практике сводится к одному: нашел ли пользователь нужное в первых 3-5 результатах.
На русском промахи случаются чаще, потому что один и тот же смысл выражают десятками форм. "Оплата счета", "оплатить счет", "счета к оплате", "счетик" - для человека это рядом, а для поиска это может быть совсем разный текст. Если система плохо работает с морфологией русского языка, она начинает наказывать пользователя за естественную речь.
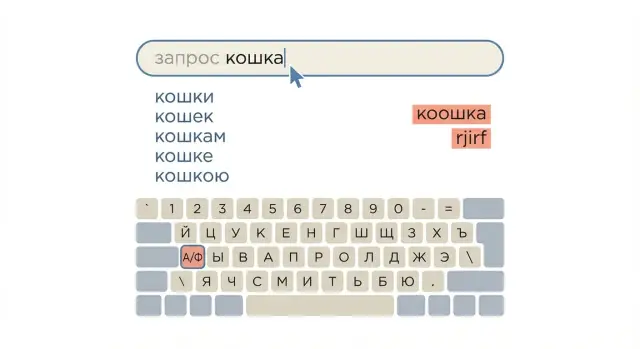
Вторая причина - написание. Запросы приходят с опечатками, пропущенными буквами, смешением е/ё, слитным и раздельным написанием. Добавьте ошибочную раскладку и транслит - и поиск уверенно показывает результаты по совпадению пары букв, а нужные документы не поднимает наверх.
Представьте: в базе знаний есть статья "Возврат товара: сроки и условия". Пользователь пишет "вазврат тавора срок" или "vozvrat tovara" и ждет ответ сразу. Если поиск не учитывает такие варианты, он может поднять "товарный знак" или "сроки доставки", потому что там больше точных совпадений.
Важно заранее понимать, какой у вас тип поиска. От этого меняются и правила релевантности:
Если вы настраиваете русскоязычный поиск с помощью ИИ, ему не стоит "догадываться", что считать одинаковым. Гораздо надежнее дать примеры, рамки и исключения, а потом проверить выдачу по тестовым запросам.
В русском языке один и тот же предмет легко превращается в десятки словоформ. Для поиска это означает простую вещь: пользователь пишет "стол", а в карточке товара стоит "стола" или "столом", и без нормальной морфологии выдача начинает вести себя странно.
Сначала решите, какие формы вы считаете одним смыслом. Чаще всего это все падежи и числа у обычных существительных: "стол", "стола", "столом", "столы". То же относится к названиям ролей и профессий: "менеджер", "менеджера", "менеджеры". Для прилагательных важнее согласование: "новая", "новое", "новые" обычно должны вести к одним и тем же результатам.
С предлогами аккуратнее. "В Москве", "по Москве", "из Москвы" звучат похоже, но намерение может отличаться. В каталоге услуг "доставка по Москве" и "доставка из Москвы" - разные сценарии. Поэтому предлоги лучше не "съедать" автоматически: сначала проверьте на своих данных, где это помогает, а где путает.
Отдельная боль - составные слова и дефисы. Пользователь может написать "онлайн-касса", "онлайн касса" или даже "онлайнкасса". Если вы управляете релевантностью через ИИ, полезно заранее зафиксировать правило: дефис, пробел и слитное написание считаем эквивалентными, но только для списка известных составных терминов.
С фамилиями и брендами не ломайте точные совпадения. Склоняемые фамилии могут выглядеть как разные слова, а бренд иногда важнее морфологии.
Практичный компромисс выглядит так:
Опечатки в русскоязычном поиске почти всегда системные. Люди пишут с телефона, путают раскладку, смешивают слитное и раздельное, используют транслит. Если это не учесть, релевантность будет прыгать: один и тот же смысл то находится, то пропадает.
Самый частый класс ошибок - неправильная раскладка. Пользователь хотел "привет", а набрал "ghbdtn". Для поиска здесь важна не оценка таких слов, а умение привести ввод к нормальной форме запроса.
Вторая группа - соседние клавиши и лишние повторения. "првет", "москвва", "дрельь" выглядят как разные слова, но намерение одно. Такие ошибки хорошо ловятся, если вы допускаете небольшое "расстояние" между запросом и словом в данных.
Третья группа - пропуски и перестановки букв: "кфе", "коофе", "кофее". Здесь легко переборщить. Если разрешить слишком много замен, поиск начнет подмешивать нерелевантные результаты.
Отдельно стоит слитное и раздельное написание. "водонагреватель" и "водо нагреватель" должны вести к одним и тем же товарам или статьям. То же самое с дефисами и пробелами в брендах и моделях.
И еще один обязательный слой - транслит и смешанное письмо. "iphone", "айфон" и "aifon" часто означают одно и то же, особенно в каталогах и поддержке.
Практичный минимум, который стоит заложить:
Пример из жизни: в базе есть "водонагреватель Ariston", а в поддержку пишут "djlj yfuhtdftnkm fhbcnty" или "водо нагреватель аристон". Если поиск приводит эти варианты к одной форме и при этом не ломает точные совпадения, пользователю не приходится угадывать правильное написание.
Поиск начинает "угадывать", когда все запросы смешаны в одну кучу. Один и тот же текст может означать разные действия: "айфон 13 цена" - не то же самое, что "айфон 13 как настроить камеру". Если разложить запросы по типам, вы быстрее настроите релевантность и избежите странных результатов.
Начните с базового: человек хочет купить, узнать, сравнить или найти инструкцию. Интент часто выдают слова-маркеры: "купить", "заказать", "доставка", "как", "почему", "инструкция", "сравнить", "лучше", "топ".
Короткая практика: запрос "налоговый вычет документы" может означать "узнать, какие нужны" или "найти шаблон заявления". Это два разных ответа и часто два разных типа страниц.
Дальше выделите сущность: товар, услуга, статья, человек, город, документ. Затем атрибуты, которые уточняют выбор: модель, год, размер, цвет, цена, локация.
Удобно фиксировать запрос как "сущность + атрибуты + интент". Например, "кроссовки 42 черные недорого" - товар, атрибуты (размер, цвет, цена), интент (покупка). А "кроссовки 42 как выбрать" - та же сущность, но интент уже обучающий.
Отдельно отметьте "мусорные" добавки. "Отзывы", "фото", "скачать", "цена", "как" иногда помогают, а иногда только мешают. "Цена" в каталоге полезна, а в базе документов может уводить в нерелевантные материалы.
И еще два фактора, которые ломают простые правила: синонимы и разговорные слова. "Авто/машина", "зарплата/оклад", "детская/для ребенка". Если такие пары не зафиксировать, ИИ будет то расширять смысл слишком широко, то наоборот пропускать хорошие результаты.
Когда типы запросов описаны, их проще превращать в примеры для обучения: для каждого интента и сущности дайте несколько корректных формулировок и явно отметьте, какие атрибуты должны влиять на выдачу, а какие можно игнорировать.
Релевантность чаще упирается не в "умность" алгоритма, а в качество входных данных. Если заранее собрать несколько простых списков, поиск начнет вести себя предсказуемо: меньше случайных совпадений, больше правильных ответов на разных формах слов и с ошибками.
Сначала составьте карту того, что вы вообще ищете. Это не про структуру сайта, а про сущности: категории, услуги, документы, роли, города, названия разделов, частые атрибуты. Сразу укажите варианты написания: "санкт-петербург", "спб", "питер", "петербург". Пользователи пишут по привычке, а не по справочнику.
Отдельно подготовьте список точных совпадений, где "похоже" недопустимо. Обычно это бренды, модели, артикулы, тарифы, номера договоров. Например, "Galaxy A54" не должен смешиваться с "A54s", а "Pro" - тянуть результаты для "Business". Такой словарь помогает жестко разделить зоны: где нужен строгий матч, а где можно включать морфологию.
Дальше решите, какие синонимы вы действительно считаете одним смыслом. "Оплата" и "платеж" часто можно объединить, а вот "заявка" и "жалоба" обычно нельзя. Короткий, но точный список почти всегда лучше огромного, который ломает выдачу.
Чтобы правки были измеримыми, соберите примеры плохих результатов. Запишите запрос, что пользователь ожидал увидеть, и что именно было не так: не тот раздел, перепутаны товары, слишком много "мусора", важный документ не поднялся в топ.
И наконец, зафиксируйте запреты: что нельзя показывать, что нельзя смешивать, и какие группы результатов должны быть раздельными. Это особенно важно, если поиск используется внутри продукта или личного кабинета.
Минимальный набор для старта:
Набор тестовых запросов нужен, чтобы проверять стабильность: поиск должен одинаково хорошо отвечать на "нормальные" формулировки, словоформы и мелкие ошибки.
Начните с 30-50 самых частых запросов из логов (или из подсказок, если логов нет). Разложите их по типам и сразу договоритесь, как оцениваете результат.
Сделайте это просто:
Ожидания фиксируйте конкретно: "в топ-3 должна быть карточка товара X и категория Y". Если контент часто меняется, задавайте критерий вместо конкретной страницы: "любая страница с точным артикулом", "категория с этим брендом".
Запросы на точность держите отдельным блоком и проверяйте строже. Если "A123" вдруг превращается в "похожие товары", это не "чуть хуже", а поломка сценария.
Морфология меняет окончания, число и даже часть речи, но смысл запроса часто сохраняется. Чтобы модель не трактовала это на глаз, заранее решите, какие пары обязаны давать одинаковую выдачу.
Примеры, которые часто стоит включить в тестовый набор (ожидаем одинаковую выдачу):
Для каждой пары заранее уточните, что именно значит "одинаково". Например, "ремонт ноутбука" может вести на страницу услуги, а "ремонт ноутбуков" - на список сервисов или категорию. "В Москве" может включать фильтр город=Москва, а "Москва" иногда вводят как часть названия компании или события. В спорных случаях лучше считать запросы похожими, но не полностью эквивалентными.
Ошибки в русскоязычных запросах бывают разными. Важно не просто "чинить" ввод, а заранее решить, насколько далеко вы готовы отходить от исходного слова, чтобы не начать подсовывать лишнее.
Чтобы ИИ не "угадывал", задайте рамки: максимальное число правок в слове, приоритет исправлений (раскладка vs опечатка), и что делать при конфликте (например, "мир" vs "сыр" при одной замене).
Простой ориентир: если у вас есть каталог и база знаний, по запросу "aifon 13 promax" человек чаще ожидает товар, а не статью про настройку. Значит, для брендовых слов и моделей полезно усиливать точные совпадения и словари вариантов написания.
Начинайте не с настроек, а с правил успеха. Один и тот же запрос можно считать "хорошо обработанным" по-разному: для навигации важен точный документ на 1 месте, для категорийных запросов важнее разнообразие, для справочных важно попадание в тему.
Коротко опишите, что должно оказаться в топе и как вы это проверяете. Удобно держать таблицу: запрос, тип, "идеальный ответ", допустимые альтернативы.
На старте обычно хватает таких критериев:
Сохраните "базовую линию": снимок выдачи (хотя бы топ-10) и оценку по вашим правилам. Это точка отсчета, чтобы видеть не только улучшения, но и поломки.
Сначала настройте текстовую обработку: нормализацию регистра, е/ё, лишние пробелы, лемматизацию или стемминг, словари синонимов (например, "СПб/Санкт-Петербург"). Важно: каждое изменение делайте отдельно и сразу перетестируйте.
Потом добавляйте опечатки. Задайте порог исправления и правила, когда исправлять нельзя (короткие слова, артикулы, точные модели). Проверьте раскладку и транслит: "ghbdtn" -> "привет", "moskva" -> "москва".
Когда базовые слои стабильны, подключайте ИИ-ранжирование там, где правила начинают спорить: длинные разговорные запросы вроде "айфон 13 не заряжается после обновления" или "доставка в питер сегодня". ИИ проще контролировать, если вход уже нормализован.
Финальный цикл простой: повторный прогон тестов, сравнение с базовой линией, фиксация изменений.
Поиск чаще портится не из-за одной большой проблемы, а из-за пары "улучшений", которые выглядят разумно, но ломают смысл.
Если коррекция опечаток пытается любой ценой найти "похожее слово", начинают смешиваться разные товары и темы. Пользователь пишет "ланос стартер", а система исправляет и уводит в общие категории вместо нужной детали. Правило простое: лучше ничего не исправить, чем исправить в другую сущность.
Синонимы зависят от предметной области. В финтехе "аккаунт" и "счет" могут означать разные вещи. Если склеить их, вы получите много совпадений по словам, но не по смыслу.
Артикулы, номера моделей, коды ошибок, версии, серийники стоит обрабатывать отдельно. "E13", "P0420", "SM-G991B" нельзя размывать морфологией и "умными" синонимами. Для таких запросов точность важнее семантики.
"Как выбрать ноутбук" и "купить ноутбук 16 ГБ" - разные намерения. Если ранжировать их одинаково, пользователи будут получать статьи вместо товара или товары вместо инструкции.
Если вы меняете правила и не ведете небольшой эталонный набор, вы не узнаете, стало ли лучше. Тесты только на чистых запросах тоже обманывают: реальность - это "айфон 13 чехолл", "sber spisanie", "вк парол забыл".
Чтобы русскоязычный поиск улучшался предсказуемо, держите короткий контрольный набор: 20-30 точных запросов (коды, модели), 20-30 "человеческих" (с вопросами), и 20-30 шумных (опечатки, раскладка, транслит).
Перед тем как докручивать релевантность, проверьте, что у вас есть понятные проверки и правила, по которым вы принимаете изменения. Без этого поиск улучшают "на глаз", а потом сложно понять, почему стало хуже.
Короткий чеклист перед настройкой:
Дальше переходите от списка проблем к повторяемому циклу улучшений: фиксируете кейс, добавляете правило, прогоняете тесты, сравниваете с базовой линией.
Обычно быстрый эффект дают три шага: один прогон тестов до изменений, правки маленькими порциями (1-3 изменения за раз), и обязательный повторный прогон с записью, сколько запросов стало лучше, хуже или без изменений.
Если вы собираете прототип поиска внутри TakProsto (takprosto.ai), удобно хранить такие правила и тестовые наборы рядом с проектом, а изменения проверять через snapshots и rollback, чтобы спокойно откатываться, если часть запросов просела.
Лучший способ понять возможности ТакПросто — попробовать самому.