Проектирование схемы Postgres в planning mode: как заранее описать сущности, связи, ограничения, индексы и миграции, чтобы потом меньше переделывать код.
Идея «сначала сгенерировать, потом поправить» кажется быстрой, пока проект не начинает жить. Вы добавляете пару полей, меняете связь, переименовываете таблицу, и внезапно ломаются формы на фронте, обработчики на бэке и тестовые данные. Каждое такое движение тянет цепочку мелких правок, и скорость превращается в бесконечные переделки.
Planning mode помогает остановиться на 20-30 минут и договориться (с собой и командой), какие данные вообще есть и как они должны себя вести. Это особенно важно, если вы строите приложение через чат и затем генерируете модели и эндпоинты: чем яснее план, тем меньше «магии» и неожиданностей после генерации.
Перед генерацией кода полезно ответить на несколько вопросов про данные:
Когда есть единый план, фронт и бэк начинают говорить на одном языке. Дизайнер формы понимает, какие поля обязательны. Бэкенд знает, где ставить ограничения и как обрабатывать ошибки. А база данных становится источником правды, а не отражением случайных правок в коде.
Критерий успеха простой: вы показываете схему человеку, который не читал код, и он все равно понимает сценарий. Например: «клиент создал заказ, добавил товары, оплатил, получил статус доставки». Если схема покрывает реальные шаги и в ней видно, где хранятся ключевые факты и правила, генерация в TakProsto пройдет спокойнее, а переписывать модели и API придется заметно реже.
Перед тем как рисовать таблицы, договоритесь о словаре. Запишите, какие «вещи» вы храните, как вы их называете, и кто за что отвечает. Это не про SQL, а про смысл: одна и та же сущность не должна жить под разными именами (например, «клиент» и «покупатель»), иначе потом появятся дубликаты таблиц и лишние связи.
Начните с короткого набора: сущности, их состояния и справочники. Сущность - это то, что имеет отдельную жизнь (пользователь, заказ, платеж). Состояния - как сущность меняется во времени (черновик, оплачен, отменен). Справочники - короткие списки, которые редко меняются (типы доставки, валюты, причины отмены). В planning mode в TakProsto удобно проговорить это в чате и сразу зафиксировать формулировки.
Дальше опишите операции обычными глаголами: что человек делает в продукте. Создает, редактирует, ищет, фильтрует, оплачивает, возвращает, отменяет. Эти действия подсказывают, какие поля должны быть обязательными, какие будут часто участвовать в поиске, и где нужны статусы и история изменений.
Чтобы не ошибиться с индексами и структурой, оцените нагрузку простыми словами. Например: «часто» - поиск по номеру заказа, список заказов пользователя, проверка статуса оплаты; «редко» - отчеты за год, массовый экспорт, админские сверки; «очень редко» - пересчет старых данных, миграции справочников.
В конце соберите бизнес-ограничения, которые лучше закрепить в базе, а не только в коде: уникальность (email, номер заказа), обязательность (нельзя создать платеж без суммы), допустимые значения (статус только из списка), запреты (нельзя удалить пользователя, если есть оплаченные заказы). Чем четче вы сформулируете это словами, тем проще превратить план в таблицы, ограничения и миграции без переделок.
В planning mode сначала договоритесь о словаре предметной области: какие сущности существуют и зачем. Держите описание в 1-2 строках, без деталей реализации. Например: «Пользователь хранит профиль и вход», «Заказ описывает покупку и статус», «Позиция заказа связывает заказ и товар».
Дальше для каждой сущности накидайте минимальный набор полей: тип, обязательность и пример значения. Такой формат быстро показывает пробелы и лишнее. Например для заказа: created_at (timestamp, обяз., "2026-01-09 10:15"), total_amount (numeric, обяз., 1990.00), status (text или enum, обяз., "paid"), comment (text, необяз., "доставить после 18:00"). Если поле не помогает ни одному сценарию (поиск, расчет, отчет, интеграция), смело убирайте.
С идентификаторами решите сразу, чтобы потом не переписывать модели и API. Обычно выбор такой:
Частая ошибка при проектировании схемы Postgres - пытаться положить в одну таблицу и текущее состояние, и историю, и настройки. Разделяйте: текущее состояние в основной таблице, историю изменений - в отдельной (например, order_status_history), редкие настройки - в отдельном профиле.
Отдельно решите, что является справочником, а что перечислением. Если значения фиксированы и почти не меняются (например, "draft/paid/canceled"), подойдет enum или CHECK-ограничение. Если список будет расширяться бизнесом (типы доставки, причины отмены), лучше справочник (delivery_type) с id и названием. В TakProsto это удобно фиксировать до генерации: потом модели и эндпоинты получаются ровнее, а переделок меньше.
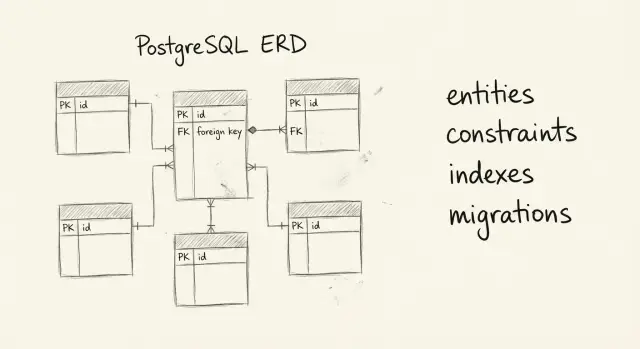
Связи важнее, чем кажется: именно они решают, будут ли данные «держаться вместе» или расползутся на копии, пропуски и странные исключения. Лучше один раз спокойно выбрать тип связи, чем потом переписывать модели и эндпоинты.
Начинайте с самого простого варианта.
Связь 1-N подходит почти всегда: один пользователь - много заказов, один заказ - много позиций. В такой связи внешний ключ хранится на стороне «многих» (например, orders.user_id).
Связь 1-1 используйте, только если есть понятная причина разделить данные. Например, users и user_profiles, где профиль может быть пустым. Тогда обычно внешний ключ кладут в таблицу, которая может отсутствовать (user_profiles.user_id), и делают его UNIQUE, чтобы не было двух профилей на одного пользователя.
Связь N-N (многие-ко-многим) почти всегда означает отдельную таблицу связей. Если связь «просто связывает», достаточно двух внешних ключей и составного UNIQUE.
Сразу решите поведение при удалении родителя. Чаще всего подходят такие правила:
RESTRICT, если удаление опасно (нельзя удалить товар, пока есть позиции в заказах)CASCADE, если дочерние записи без родителя не имеют смысла (удалили черновик заказа - удалились его позиции)SET NULL, если связь необязательная (у комментария может пропасть автор, но сам комментарий остается)Если таблица связей хранит дополнительные поля (например, order_items.quantity, order_items.price, project_members.role), это уже не «чистая» N-N, а полноценная сущность. Зафиксируйте это заранее, тогда при генерации меньше шансов упереться в переделку структуры.
Чтобы избежать «сирот» и дублей, закрепите правила в базе: внешние ключи с нужным ON DELETE и UNIQUE там, где повторяться нельзя (например, один и тот же товар не должен дважды появиться в одном заказе).
Если закрепить базовые правила прямо в Postgres, дальше будет меньше сюрпризов: данные не «поедут», а модели и эндпоинты будут соответствовать реальности. Полезно заранее выписать, какие значения допустимы, что должно быть уникальным и какие связи нельзя нарушать.
NOT NULL ставьте там, где отсутствие значения почти всегда ошибка: идентификаторы, ссылки на владельца, сумма, валюта, статус, дата создания. Если поле иногда неизвестно (например, телефон клиента), лучше оставить NULL и отдельно продумать, где это допустимо в интерфейсе.
CHECK помогает зафиксировать простые бизнес-правила без кода. Например: сумма > 0, количество >= 1, дата окончания позже даты начала, статус только из ограниченного набора. UNIQUE нужен не только для email или номера заказа. Он защищает от дублей в «естественных ключах», например (user_id, external_id) или (project_id, name), если имя должно быть уникальным внутри проекта.
Минимум: у каждой таблицы есть PRIMARY KEY, и все связи оформлены FOREIGN KEY. Сразу решите поведение при удалении: RESTRICT (безопаснее по умолчанию), CASCADE (когда дочерние записи должны исчезнуть вместе с родителем), SET NULL (когда связь может быть разорвана).
Проще держать правило: «нельзя ссылаться на то, чего нет». Тогда даже при ручных правках или импорте данных база не позволит создать «висячие» записи.
Дефолты тоже лучше закреплять в схеме. Обычно это created_at по умолчанию, статус по умолчанию (например, 'draft') и иногда updated_at. updated_at часто требует триггера, но на старте можно обойтись обновлением из приложения и добавить триггер позже, когда модель устоится.
Триггеры и сложную логику стоит откладывать, если они не защищают критичную целостность. Хороший старт: ограничения, ключи, дефолты. Сложные правила (например, «нельзя менять статус назад» или «сумма заказа должна равняться сумме позиций») сначала фиксируйте как правило, но реализуйте в коде и тестах, а в базу переносите, когда требования стабилизируются.
Индекс - это не «ускоритель всего», а подсказка для конкретных запросов. Поэтому сначала фиксируйте, как люди и сервисы будут читать данные: где ищут, по чему фильтруют, как сортируют, что выводят списком. Если вы не можете назвать 3-5 самых частых запросов, индексировать пока рано.
Обычно повторяются четыре паттерна: поиск по идентификатору (id), фильтр по статусу, выборка по пользователю и сортировка по времени. Для равенства и диапазонов почти всегда хватает B-tree: user_id = ..., created_at >= ..., price BETWEEN ....
Помните про составные индексы и порядок колонок. Индекс (user_id, created_at) хорошо работает, когда вы выбираете записи пользователя и сортируете или ограничиваете по дате. А индекс (created_at, user_id) для такого запроса часто бесполезен, потому что первая колонка другая. Удобная практика: рядом с таблицей записывать «основная выборка: по user_id, сортировка: created_at desc», а уже из этого выводить индекс.
Уникальные индексы - это не про скорость, а про защиту от дублей. Если у вас есть email, номер заказа или внешний идентификатор из платежки, уникальность лучше закрепить в базе, а не надеяться на проверки в коде.
Индекс может и вредить. Он замедляет вставки и обновления, потому что его тоже нужно поддерживать, и занимает место. Три признака лишнего индекса: запрос редкий, таблица часто обновляется, индекс включает поля «на всякий случай». Начните с минимального набора под реальные экраны и API, а остальное добавляйте после первых замеров.
Planning mode удобен тем, что вы сначала договариваетесь о данных, а уже потом жмете кнопку генерации. Это снижает число переделок: вы не гоняетесь за ошибками в моделях и эндпоинтах, потому что база уже описана как надо.
Начните с черновика. Выпишите 3-7 сущностей и их ключевые поля, без деталей. Например, для сервиса заказов: user, order, order_item, product. На этом шаге важно понять, что является «объектом учета», и какие поля точно нужны для жизни (id, дата, статус, сумма).
Дальше уточняйте схему по шагам:
Если вы делаете проект в TakProsto, зафиксируйте план и согласуйте его с командой. Потом генерация кода (React, Go, PostgreSQL, Flutter) становится механической, а не «угадайкой», и откат через snapshots помогает, если что-то упустили.
Миграции - это дневник изменений схемы. Если вы проектируете Postgres-схему в planning mode, заранее решите, как будете фиксировать каждый шаг, чтобы потом спокойно генерировать модели и эндпоинты и не переписывать их заново.
Хорошее правило: одно логическое изменение - один файл миграции с понятным названием и датой/версией. Так легче откатиться, понять, когда добавилось поле и почему появилось ограничение. Важно хранить миграции рядом с кодом, чтобы окружения (локально, тест, прод) были в одинаковом состоянии.
На проде почти никогда нельзя «просто пересоздать таблицу»: там есть данные, внешние ключи, фоновые процессы и клиенты, которые читают и пишут прямо сейчас. Безопаснее делать изменения поэтапно, даже если это занимает 2-3 миграции.
Пример: вы хотите заменить поле status (text) на status_id (ссылка на справочник).
status_id (nullable) и таблицу справочника.status_id по данным из старого status (скриптом миграции).status_id.Такой подход снижает риск простоя и неожиданных ошибок.
Справочники (статусы, роли, страны, типы оплаты) часто требуют начальных данных. Но сидировать все подряд не стоит: тестовые данные пользователей и заказов лучше держать отдельно.
Сидирование имеет смысл, если значения нужны для работы приложения сразу после деплоя, на них завязаны ограничения и внешний ключ, а список меняется редко и контролируется вами.
Если вы работаете в TakProsto, заранее отметьте, какие таблицы требуют миграций с данными (seed), а какие - только схему. Это помогает сгенерировать код ближе к реальности и избежать болезненных переделок после первых релизов.
Представьте простое приложение: пользователь регистрируется, выбирает товары, оформляет заказ и оплачивает. В planning mode важно не пытаться сразу описать «все на свете» (доставка, промокоды, возвраты), а собрать схему для первой рабочей версии, которую потом легко расширить.
Для минимального MVP обычно достаточно пяти таблиц. users хранит аккаунты. products - каталог. orders - шапка заказа (кто, когда, статус). order_items - строки заказа (какой товар и сколько). payments - попытки и факты оплаты (один заказ может иметь несколько попыток).
Почему так: вы отделяете то, что «один раз на заказ» (статус, итоговая сумма), от того, что «много раз на заказ» (позиции). А платежи выносите отдельно, чтобы не переписывать модель, когда появятся повторные списания, отмены или разные провайдеры.
Ограничения лучше закрепить в базе сразу, чтобы генерация моделей и API меньше расходилась с реальностью:
users.email UNIQUE NOT NULL (и сразу решите, храните ли вы его в нижнем регистре).orders.status как TEXT с CHECK (status IN ('new','paid','canceled')), либо отдельный enum-тип, если вы уверены в наборе статусов.payments.amount > 0 через CHECK (amount > 0); для денег удобно NUMERIC(12,2) и запрет NULL.Индексы стоит проектировать под первые реальные экраны и запросы. В заказах почти всегда нужны: список заказов пользователя, фильтр по статусу и сортировка по дате.
orders(user_id, created_at DESC) для «Мои заказы».orders(status, created_at DESC) для админки или списка «Новые/Оплаченные».order_items(order_id) чтобы быстро поднимать позиции конкретного заказа.В TakProsto удобно зафиксировать это в planning mode текстом: какие таблицы, ключи, статусы, проверки и какие запросы должны работать быстро. Потом уже генерировать модели и эндпоинты и реже возвращаться к переделкам.
Даже если вы работаете в planning mode и пока не генерируете код, ошибки на этапе схемы потом обходятся дороже всего. Часто проблема не в Postgres, а в том, что в первый план смешивают разные уровни: что хранить, как проверять и как должен работать сервис.
Одна из частых ловушек - пытаться спрятать бизнес-логику в структуру таблиц уже в первой версии. Например, делать отдельные поля под каждое «состояние» заказа, десятки флагов или хранить «итоговую сумму» без понятных правил пересчета. В схеме лучше закреплять факты (что произошло) и правила целостности, а поведение оставить уровню приложения.
Еще одна ошибка - усложнять связи ради «правильности»: добавлять N-N связи и промежуточные таблицы без реальной нужды. Если у вас пока нет сценария, где один объект должен принадлежать многим и наоборот, начните с 1-N. Потом усложнить связь обычно проще, чем сразу поддерживать лишние таблицы и миграции.
Почти всегда больно аукнется отсутствие ограничений. Если не поставить NOT NULL, уникальность и внешние ключи там, где они обязательны, вы быстро получите мусор в данных, а затем странные баги в API. Особенно это заметно, когда вы генерируете модели и эндпоинты: приложение начинает «лечить» то, что должна была не пропускать база.
С индексами другая крайность: ставить их «на всякий случай». Это замедляет записи и усложняет поддержку. Перед добавлением индекса полезно зафиксировать 2-3 главных запроса, например: поиск заказа по user_id и статусу, сортировка по created_at.
И, наконец, миграции. Если в плане нет отката, ошибка в поле или типе превращается в долгий ремонт. Договоритесь заранее, как вы отменяете изменения: переименование, добавление новых колонок вместо удаления, временные значения по умолчанию.
Короткая проверка перед генерацией в TakProsto: есть ли у каждой таблицы понятный ключ, минимальный набор ограничений, и индексы только под реальные запросы.
Перед тем как нажать «сгенерировать», стоит потратить 10 минут на быстрый самоконтроль. Это дешевле, чем потом править модели, API и миграции по цепочке.
Проверьте базовые вещи, которые чаще всего вызывают переписывания:
Небольшой практический тест: попробуйте мысленно пройти путь пользователя. «Создал заказ», «изменил статус», «удалил товар», «посмотрел историю». Если в этом сценарии возникают вопросы к данным, они всплывут и в коде.
В planning mode удобно фиксировать эти решения до генерации: вы сначала договариваетесь о правилах, а потом получаете модели и эндпоинты, которые реже приходится переделывать.
Когда схема и стратегия миграций продуманы, не спешите сразу жать генерацию. Зафиксируйте план как единый документ: список таблиц, ключевые поля, связи, ограничения, индексы и 2-3 типовых сценария запросов. Это проще согласовать с командой и заказчиком, чем спорить по коду и сломанным данным.
Проверьте план по короткому маршруту и только потом переходите к прототипу:
Дальше выберите один контрольный сценарий и прогоните его мысленно от API до базы: например, «создать заказ», «добавить позицию», «пересчитать сумму», «показать историю». Если в сценарии появляются костыли (например, нужно «угадать» значение или хранить два источника правды), лучше поправить план сейчас.
В TakProsto удобно сначала обсудить схему в planning mode, а затем сгенерировать прототип: фронтенд на React, бэкенд на Go и базу PostgreSQL. Это снижает число переписываний, потому что вы генерируете модели и эндпоинты уже из утвержденной структуры.
После первой генерации сделайте две вещи: зафиксируйте результат снапшотом и держите понятный путь отката, если спорное изменение «не зашло». Когда прототип начинает жить, часто нужны практичные шаги: экспорт исходников для работы вне платформы, деплой и хостинг, а для тестов с реальными людьми - подключение своего домена.
Если вы ведете каждую правку схемы через planning mode, затем миграцию, затем новый снапшот, прототип растет спокойно и предсказуемо. А если нужно собрать все это в одном месте, проще ориентироваться, когда проект ведется в TakProsto на takprosto.ai: там план, генерация и откаты лежат рядом и не расползаются по разным документам.