Разбираем soft delete в Postgres: флаг, archived_at и отдельные таблицы. Как не сломать уникальность, индексы, отчеты и восстановление данных.
Soft delete (мягкое удаление) - это когда запись не удаляют из таблицы физически, а помечают как неактивную. Для пользователя она как будто исчезла, но в базе остается и при необходимости может быть восстановлена.
Физическое удаление (DELETE) со временем освобождает место, упрощает запросы и снижает риск случайно «подмешать» лишние данные. Но оно необратимо без бэкапа: вы теряете след, кто и когда удалил запись, и часто - состояние данных до удаления.
Мягкое удаление оправдано, когда важны обратимость и история. Типовые случаи:
Проблемы начинаются, когда soft delete включают «на всякий случай». Через несколько месяцев таблицы разрастаются, запросы усложняются, а ошибки становятся тихими: внешне все работает, но цифры в отчетах уже не те.
Первая боль - рост таблиц. «Удаленные» строки продолжают жить в тех же индексах, замедляют выборки и раздувают бэкапы. Это особенно заметно в сущностях с частыми удалениями: сессии, черновики, временные записи.
Вторая боль - сложность запросов. Почти в каждом SELECT нужно помнить фильтр «только активные». Один забытый WHERE - и в выдаче появляются «мертвые» сущности. Часто это всплывает не сразу, а после доработок.
Третья боль - отчеты и аналитика. В одном месте считают только активные, в другом - активные плюс архив, а в третьем случайно считают все подряд. Через 6-12 месяцев команда уже не помнит исходный смысл поля, и метрики начинают расходиться.
Особенно часто soft delete ломается там, где:
archived_at, часть без soft delete);Если вы точно знаете, зачем храните удаленные строки (аудит, возврат, история), soft delete полезен. Если цель только «на всякий случай», часто лучше честное удаление плюс журналирование изменений или отдельная история событий.
Soft delete в Postgres сводится к одному: запись не должна участвовать в обычной работе системы, но должна оставаться доступной для истории, аудита и восстановления.
Важно заранее договориться, что именно означает «удалено» в вашей бизнес-логике. Например: скрыто из пользовательского интерфейса, не попадает в операционные расчеты, но доступно в админке по правам и может быть восстановлено.
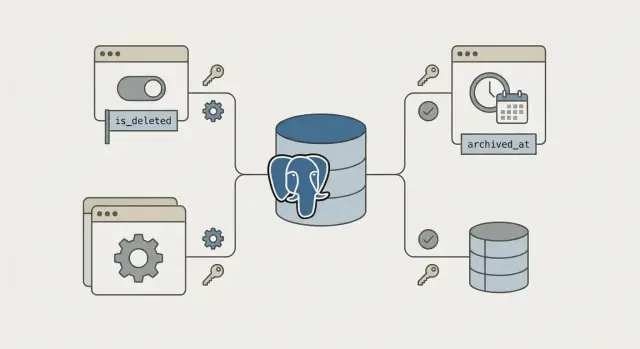
Самый простой вариант: добавить столбец is_deleted boolean not null default false и везде фильтровать where is_deleted = false. Он удобен, когда удаление строго бинарное и дата удаления не важна.
Плюсы: быстро внедряется, легко объяснить. Минусы: код со временем обрастает забытыми фильтрами, а отчеты «за период» сложнее, потому что неизвестно, когда именно запись стала неактивной.
Вместо флага используется archived_at timestamp null. Пока значение null, запись активна. При «удалении» вы ставите дату.
Этот вариант выигрывает, когда нужны отчеты и сроки хранения: можно посчитать, сколько сущностей «удаляли» в прошлом месяце, или чистить архив старше N дней. Аналитикам его тоже проще объяснить: «активные - это archived_at IS NULL».
Минусы: нужно договориться о времени (UTC или локальное) и о том, что делать при восстановлении (сбрасывать в null или фиксировать отдельным событием).
Идея: активные данные лежат в основной таблице, архивные уезжают в отдельную (например, orders и orders_archive) или в партицию. При удалении вы переносите строку транзакцией.
Плюсы: активная таблица меньше, индексы компактнее, запросы по «живым» данным быстрее и проще. Минусы: усложняются код и миграции, отчеты чаще требуют объединения данных, а перенос нужно делать аккуратно, чтобы не потерять связи.
На практике выбор обычно такой:
archived_at - если важна дата и аналитика по удалению;Перед выбором ответьте на несколько вопросов: нужно ли восстановление, должны ли «удаленные» попадать в финансы и KPI, кто и как их видит, будет ли физическая очистка архива по сроку хранения. Эти ответы важнее, чем конкретный тип столбца.
Самый частый сюрприз soft delete в Postgres появляется там, где есть уникальность: email у пользователя, артикул у товара, номер договора, slug в блоге. Пока строка физически не удалена, она продолжает участвовать в уникальных ограничениях, и «создать заново» с тем же значением не получится.
Есть три бизнес-варианта, и важно выбрать один до миграций:
Если нужен второй или третий вариант, обычный UNIQUE constraint часто не подходит. Практичный путь - частичный уникальный индекс, который проверяет уникальность только среди активных строк. Например, для схемы с archived_at:
CREATE UNIQUE INDEX users_email_active_uq
ON users (email)
WHERE archived_at IS NULL;
Так активные пользователи не смогут поделить один email, но после архивации старой записи вы сможете создать новую с тем же email. Для подхода с boolean-флагом условие будет WHERE is_deleted = false.
В мультиарендных (multi-tenant) схемах сюрпризы усиливаются. Почти всегда уникальность должна быть «внутри арендатора», иначе один клиент может случайно заблокировать другого. Тогда индекс делают составным (tenant_id + email, tenant_id + sku) и добавляют то же условие по активным строкам.
Внешние ключи тоже могут «сломаться» не технически, а логически. Если вы разрешили повтор значения (например, SKU), отчеты и история заказов могут внезапно начать показывать новую сущность вместо старой, если связывание идет по «человеческому» полю, а не по id. Исторические данные должны ссылаться на стабильный первичный ключ, а «удаленность» объекта нужно учитывать в запросах и интерфейсах.
Хороший компромисс для истории: не трогать внешние ключи, не переназначать id, а для повторного использования значения опираться на частичный уникальный индекс. Тогда связи остаются целыми, а бизнес-правило уникальности работает так, как ожидает пользователь.
Soft delete в Postgres почти всегда добавляет в запросы условие вроде WHERE is_deleted = false или WHERE archived_at IS NULL. Если оставить все как есть, база начнет чаще ходить по большому индексу (или даже по всей таблице), потому что в данных появляются две «зоны»: актив и архив.
Боль проявляется не сразу. Пока архив небольшой, условие хорошо отсекает. Через полгода-год архив разрастается, селективность падает: активных строк может остаться 5-20%, а все остальное превращается в «мертвый груз» для большинства запросов.
Если 90% запросов читают только активные строки, лучший ход - частичный индекс только по активу. Он меньше по размеру, быстрее помещается в память и ускоряет планы запросов.
CREATE INDEX users_email_active_idx
ON users (email)
WHERE archived_at IS NULL;
Такой индекс особенно полезен, когда:
archived_at IS NULL).Если же запросы регулярно смешивают актив и архив, частичный индекс будет использоваться реже. Тогда нужен либо обычный индекс, либо другая стратегия (например, архив в другой таблице).
archived_at полезен не только как маркер удаления. По нему часто делают отчеты «за период», задачи очистки «удалить архив старше 180 дней» или фоновые проверки.
CREATE INDEX users_archived_at_idx
ON users (archived_at);
Если выборки обычно выглядят как WHERE archived_at < now() - interval '180 days', такой индекс помогает не трогать лишние страницы таблицы.
Soft delete увеличивает стоимость хранения, даже если вы «не удаляете физически». Обновление флага или установка archived_at создают новые версии строк. Старые версии остаются до очистки, таблица и индексы пухнут, растет число страниц, которые нужно читать.
VACUUM и autovacuum становятся важнее, потому что растет число мертвых версий строк и раздуваются индексы. Без частичных индексов запросы по активу начинают читать больше лишних блоков.
Практичный ориентир: если у вас есть «горячие» таблицы (заказы, события, пользователи) и вы добавляете мягкое удаление, сразу планируйте частичные индексы для активных данных и отдельные индексы для типичных архивных выборок. Это обычно дешевле, чем потом искать причину, почему отчеты или простые списки внезапно стали медленными.
Главный вопрос для отчетов: что считается правдой - только активные строки или активные плюс архив. Для операционных экранов почти всегда нужен только актив. Для финансовых и исторических отчетов важен полный след: что было, когда появилось и когда «исчезло».
Если это не зафиксировать заранее, отчеты начинают «плавать». Один запрос считает архивные строки как живые, другой случайно отрезает часть истории. В итоге цифры не сходятся, а разбор занимает больше времени, чем само удаление.
Обычно встречаются три вида вопросов:
Если у вас есть archived_at, отчеты «на дату» становятся проще: активные на момент времени T - это строки, где created_at <= T и (archived_at is null или archived_at > T). Если вместо этого только флаг is_deleted, вы теряете момент, когда запись перестала быть активной, и отчеты превращаются в догадки.
Лучше устроить правила так, чтобы ошибиться было сложно:
archived_at (или deleted_at) и единый смысл (null = активна).*_active, где фильтр уже встроен.Пример из жизни: менеджер просит отчет по товарам «в наличии». Если запрос берет таблицу без фильтра, туда попадут и архивные товары, и вы получите «лишние» позиции. Если же запрос всегда режет по archived_at is null, то исторический отчет «какие товары были в каталоге в прошлом квартале» внезапно потеряет половину строк.
Когда команда фиксирует, какие отчеты работают по активу, а какие - по полной истории, становится проще и разработчикам, и аналитикам.
Начинайте не с миграции, а с правил. Самый частый источник багов - когда команда по-разному понимает, что значит «удалено»: скрыто ли оно для пользователя, видно ли в админке, участвует ли в поиске, можно ли восстановить, и как это влияет на связанные сущности.
Опишите 2-3 сценария простыми фразами: «обычный пользователь не видит», «админ видит с пометкой», «в отчеты попадает/не попадает по умолчанию». Отдельно решите, что происходит с зависимыми записями (например, удаленный товар в прошлых заказах).
Для простого скрытия подходит is_deleted boolean not null default false. Если важно знать, когда удалили, и удобно чистить архив по времени, лучше archived_at timestamptz null.
На старте оставьте значение «не удалено» по умолчанию, чтобы старый код не начал неожиданно скрывать данные.
Дальше полезно идти в таком порядке (чтобы релиз был предсказуемым):
archived_at is null);Опасный момент - когда часть запросов уже фильтрует архив, а часть нет.
Практичный прием: сделать слой доступа к данным (репозитории/методы) или представление (view) «только активные», и перевести основные сценарии на него. Для админки и отчетов оставьте явный режим «включая архив», чтобы это было осознанным выбором.
Если поддерживаете восстановление, заранее решите, что делать с конфликтами уникальности. Пример: пользователь восстановил запись, но за это время появилась новая с тем же email/sku.
Нужны понятные правила: запретить восстановление, предложить переименовать, восстановить в «черновик».
Аудит проще всего вести отдельными полями (archived_by, archived_reason) или таблицей событий.
Сначала выкатите миграцию, потом код, который пишет поле при удалении, и только затем - код, который начинает фильтровать.
Добавьте простые проверки: количество активных не должно резко упасть, отчеты должны совпасть с контрольными выборками, а восстановление должно быть протестировано на реальных ограничениях.
Представьте интернет-магазин с тремя таблицами: products (товары), orders (заказы) и order_items (позиции в заказе). Самый частый конфликт возникает, когда товар нужно "убрать", но история продаж должна остаться точной.
Кейс 1. Товар больше не продается, но старые заказы должны открываться без сюрпризов. Если вы делаете soft delete в products, важно не ломать связи: order_items.product_id по-прежнему указывает на товар. Поэтому физически удалять строку нельзя. На практике удобно хранить archived_at (или is_deleted) в products и фильтровать активные товары в витрине, но не фильтровать их в админке и в истории заказов.
Кейс 2. Товар сняли с продажи, а потом завели снова с тем же SKU. Здесь всплывает уникальность. Если у вас UNIQUE(sku) на всю таблицу, повторное создание не пройдет. Обычно решают так: делают уникальность только для активных строк.
CREATE UNIQUE INDEX products_sku_active_uq
ON products (sku)
WHERE archived_at IS NULL;
Так старый архивный товар не мешает завести новый, но среди активных SKU остаются уникальными.
Кейс 3. Отчет по продажам за прошлый квартал должен включать и архивные товары, иначе суммы и названия разъедутся. Ошибка - применять фильтр archived_at IS NULL автоматически везде. В отчетах лучше явно решать, что считаем, и тянуть факты из order_items и orders, а products подключать для названий и атрибутов, даже если товар архивный.
Что обычно выбирают в этом сценарии:
products часто удобнее archived_at, потому что дает дату архивации и помогает аналитике;products огромный и активные запросы страдают, но тогда усложняется поддержка и join.Минимальный набор индексов здесь обычно такой: частичный уникальный индекс по SKU для активных, плюс индекс по archived_at (или частичный) если часто ищете только активные товары или чистите архив по дате.
Проблема soft delete проста: запись «удалили», но она продолжает жить в базе, а значит влияет на API, UI, отчеты и ограничения. Ошибки обычно не в самом поле deleted или archived_at, а в том, как команда договорилась (или не договорилась) им пользоваться.
Если в одном месте вы фильтруете archived_at is null, а в другом забыли, пользователи увидят «удаленные» сущности в списках, автодополнении, корзине или админке. Особенно опасны фоновые задачи: отправка писем, пересчет остатков, выдача прав.
Полезная привычка: для важных сущностей иметь один очевидный способ получать «активные» записи (view или единый репозиторий), а не копировать фильтр по коду.
В Postgres логически удаленная строка все еще занимает уникальный ключ. Типичный симптом: вы не можете создать нового пользователя с тем же email, потому что старый «удален» флагом.
Чаще всего спасает частичный уникальный индекс, который учитывает только активные записи (например, уникальность по email, где archived_at is null). Но важно заранее решить, что означает «уникальность»: среди активных или среди всех, включая архив.
Soft delete увеличивает объем таблиц, а значит и стоимость сканов, сортировок и join. Если запросы на «актив» не подкреплены частичными индексами, планировщик чаще уходит в тяжелые планы.
Проверьте, что у вас есть индексы под реальную выборку: активные по ключам поиска и по внешним ключам, которые участвуют в join.
Логическое удаление не отменяет вопрос: когда удалять физически. Если политика хранения не определена, «архив» превращается в бесконечную свалку, бэкапы растут, миграции замедляются.
Плохой сигнал: в одной таблице is_deleted, в другой archived_at, в третьей записи переносятся в отдельную таблицу, а в коде все называется «удалить». Через полгода никто не помнит, что означает дата: факт удаления, время архивации, или «скрыть из интерфейса».
Короткий пример: в интернет-магазине товары мягко удаляют через archived_at, а категории - через флаг. Потом в UI пропадает категория, но товары в ней продолжают считаться активными, и отчеты по продажам начинают «плясать». Лучше выбрать единый смысл и задокументировать его, а для исключений сделать явные правила.
Перед релизом договоритесь об одном: что именно считается «активной» записью. Это должно быть закреплено не только словами, но и технически: в SQL (представления, политики, частичные индексы) и в коде (фильтры в репозиториях, общие скоупы, правила в админке). Если определение разъедется, отчеты и API начнут показывать разное.
Проверьте уникальность на реальных сценариях. Самый частый сюрприз: вы «удалили» пользователя с email, а потом не можете создать нового с тем же email, потому что уникальный индекс смотрит на всю таблицу. Решение обычно одно из двух: частичный уникальный индекс только по активным, либо включение признака архивности в ключ уникальности (если это допустимо по бизнес-правилам).
Ниже короткий список проверок, которые стоит закрыть до выката:
archived_at IS NULL или is_deleted = false) и оно используется одинаково: запросы, API, фоновые задачи, админка;archived_at (например, для чистки или отчета);Отдельно проверьте отчеты и аналитику. Решите заранее, какие метрики считают только активные записи, а какие должны включать архив. Хорошая практика - явно называть параметры вроде include_archived, чтобы аналитик или разработчик не угадывал «как тут принято».
Чтобы soft delete не стал вечной «особенностью» базы, правила лучше зафиксировать письменно. Обычно хватает короткой заметки на 1-2 страницы: какой подход выбран (флаг, archived_at или отдельные таблицы), как выглядит «активная» выборка по умолчанию, и какие запросы команда должна использовать в типовых местах.
Рядом с правилами полезно держать пару реальных примеров SQL: как безопасно получить только активные записи, как искать по архиву для поддержки, как восстанавливать запись, как строить отчет «включая архив». Это заметно снижает шанс, что кто-то забудет условие WHERE archived_at IS NULL и начнет показывать пользователю «удаленное».
Soft delete чаще начинает болеть не сразу, а когда таблицы вырастают и архивных строк становится много. Поэтому заранее задайте простые метрики и пороги:
Дальше запланируйте миграции и тесты отчетов на объемах, близких к боевым. Особенно важно прогнать реальные отчеты и сверки: там чаще всего всплывают сюрпризы, когда «удаленные» строки попадают в агрегаты или меняют уникальность.
Если нужно быстро проверить подход, полезно сделать мини-прототип: таблица, индексы, пара отчетов, имитация роста данных. Так проще увидеть, где именно начинает мешать архив, и какие индексы реально дают эффект.
Если вы делаете прототип через TakProsto (takprosto.ai), удобно сразу проговорить правила soft delete в одном месте и проверить изменения схемы в planning mode, а затем откатываться через snapshots и rollback, если выбранный вариант дает неожиданные планы запросов.
Заранее определите «точку развилки», когда текущий подход пора усложнять. Например: архивных строк стало больше 70-80%, время отчетов растет, VACUUM не успевает, или частичные индексы стали слишком громоздкими. Тогда следующий шаг обычно один из трех: вынос архива в отдельные таблицы, партиции по дате archived_at, или отдельное хранилище для аналитики.
Soft delete — это когда запись не удаляют из таблицы физически, а помечают как неактивную. Для пользователя она пропадает из интерфейса, но в базе остается и может быть восстановлена, а также участвовать в аудите и разборе инцидентов.
Используйте soft delete, когда важны обратимость и история: восстановление «случайно удалили», аудит «кто и когда сделал», юридические сроки хранения или когда нельзя ломать связи между таблицами. Если цель только «на всякий случай», чаще проще делать обычный DELETE и отдельно писать историю изменений.
Флаг подходит, когда удаление строго бинарное и дата не нужна: быстро внедрить и легко объяснить. Минус в том, что вы не знаете момент удаления, а это усложняет отчеты «на дату» и последующую очистку архива.
archived_at удобен, когда важны аналитика и сроки: можно понять, когда запись стала неактивной, строить отчеты по периодам и чистить архив старше N дней. По умолчанию активные записи — это archived_at IS NULL, что обычно проще поддерживать в запросах.
Обычный UNIQUE смотрит на всю таблицу, включая «удаленные» строки, поэтому вы не сможете создать новую запись с тем же email или SKU. Практичное решение — частичный уникальный индекс, который проверяет уникальность только среди активных строк, чтобы архив не блокировал создание новой сущности.
Если вы разрешаете повторное использование значения после архивации, риск в том, что история может начать показывать «новую» сущность вместо старой, если где-то связывание сделано по человеческому полю, а не по id. Безопасный подход — хранить связи по стабильному первичному ключу и отдельно решать уникальность через частичный индекс для активных.
Архивные строки остаются в таблице и индексах, поэтому со временем запросы по активным данным начинают читать больше лишних страниц, а бэкапы и обслуживание растут. Обычно помогает частичный индекс по активным данным и отдельный индекс по archived_at, если вы часто выбираете или чистите архив.
Потому что меняются версии строк: при установке флага или archived_at создается новая версия записи, а старая становится «мертвой» до очистки. Если autovacuum не успевает, таблицы и индексы раздуваются, планы запросов ухудшаются и растет время операций.
Сначала определите, что считается активным и кто видит архив, затем добавьте поле и индексы, после этого обновите уникальность и только потом включайте фильтрацию в чтении. Такой порядок снижает риск, что релиз внезапно «спрячет» данные или сломает создание новых записей из-за ограничений.
Главная защита — заранее зафиксировать, какие отчеты считают только активные записи, а какие обязаны включать архив, и не смешивать эти режимы случайно. Для «обычных» экранов удобно иметь единый способ получать активные записи, а для отчетов делать явный выбор «включая архив», чтобы цифры не начинали расходиться.