Структура Go-сервиса без оверинжиниринга: понятные папки, границы слоев handlers/service/repo, правила импорта и запреты, чтобы код не расползался.
В маленькой команде Go-сервис обычно растет рывками: сегодня добавили один эндпоинт, завтра еще два, послезавтра нужно срочно поправить баг в проде. Файлы пухнут, а код начинает жить там, где его «быстрее всего было дописать».
Первый заметный симптом - перепутанные зависимости. HTTP-обработчик тянет SQL-запросы, репозиторий знает про формат JSON-ответа, а бизнес-логика размазана по пяти пакетам. Через пару недель уже страшно менять даже мелочь: непонятно, где «истина», а где временный костыль.
Типичный набор признаков:
При этом «сложная архитектура на будущее» тоже редко спасает. Если три месяца строить идеальные абстракции, а продукт меняется каждую неделю, вы просто платите сложностью за то, что еще не подтверждено реальностью. На старте почти всегда важнее простые, понятные границы, чем набор модных паттернов.
Ключевое слово - границы. Проще говоря: кто кого имеет право вызывать. Например, handler может вызвать service, service может вызвать repo, а repo не должен знать про HTTP и про то, какие кнопки нажимает пользователь.
Дальше - рабочая схема слоев (handlers/service/repo), правила импортов и минимальный набор запретов. Это не «религия», а страховка, чтобы код оставался читаемым, когда фичи выходят быстро - хоть вручную, хоть с помощью vibe-coding платформ вроде TakProsto.
Самая понятная структура для небольшого Go-сервиса держится на одном потоке: запрос приходит по HTTP или gRPC, попадает в handler, дальше в service, а затем в repo. Схема простая, но годами работает, если заранее договориться о границах.
Handler - переводчик протокола. Он принимает вход, достает параметры, читает тело, делает базовую проверку формы данных и превращает все это в понятный сервису запрос. Важно, чтобы handler не решал бизнес-задачи и не ходил в базу напрямую.
Service - место, где живут правила продукта. Он решает, можно ли создать сущность, какие поля обязательны, как считать статусы, как реагировать на конфликты. Сервис не должен знать, что вызов пришел по HTTP: никаких кодов ответов, cookies, headers, деталей роутера. На выходе - доменный результат и доменная ошибка.
Repo - доступ к данным. Он делает запросы в PostgreSQL (или другое хранилище), мапит строки в структуры и возвращает сервису результат. Репозиторий не должен принимать продуктовые решения вроде «если тариф Business, то...», и точно не должен знать, как вы отвечаете по HTTP.
Если зафиксировать «что где лежит», жить становится проще:
Слой - это не папка, а правило импортов: handler может знать про service, service может знать про repo, но не наоборот. Как только сервис начинает импортировать пакет роутера, а репозиторий - пакеты с бизнес-логикой, границы стираются, и проект быстро превращается в кашу.
Для маленькой команды важнее понятные границы, чем идеальная схема. Хорошая структура делает две вещи: показывает точки входа и отделяет внутренний код от того, что вы хотите менять без последствий.
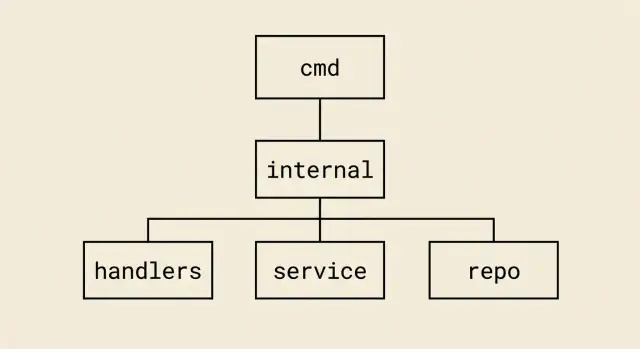
Минимальный набор обычно такой: cmd, internal, иногда configs, migrations. Этого достаточно, чтобы держать порядок и не превращать проект в музей шаблонов.
Точки входа лучше держать отдельно, чтобы сразу было видно, какие бинарники собираются и где у них старт. Самый простой вариант - cmd/<service-name>/main.go. Даже если сервис пока один, это помогает не смешивать запуск с логикой приложения.
internal - сердце проекта. Сюда складывайте все, что не должно использоваться снаружи и что вы хотите спокойно менять без оглядки на чужие импорты. Когда почти весь код живет в internal, поддерживать границы слоев заметно легче.
Пример названий, которые обычно хорошо читаются:
internal/http - роуты, хендлеры, middleware, DTO для HTTPinternal/app - сборка приложения: создание зависимостей, запуск, graceful shutdowninternal/storage - репозитории, SQL, работа с PostgreSQLpkg часто не нужен. Он имеет смысл, только если вы действительно делаете библиотеку для других проектов или выносите общий код, который будет импортироваться извне. В рамках одного сервиса pkg нередко превращается в «общую» свалку, где все зависит от всего.
Отдельно полезно держать конфиги и миграции: configs - для шаблонов и примеров настроек (без секретов в репозитории), migrations - для SQL-миграций. Тогда новый человек в команде быстрее понимает, как сервис запускается и где живет база.
Если вы собираете сервис в TakProsto, эту же схему удобно повторить в экспортируемом исходном коде: после выгрузки структура остается узнаваемой, и проект проще поддерживать вручную.
Нормальная структура держится на простом правиле: каждый слой отвечает за свой тип решений. Тогда через полгода проект все еще читается.
Handlers (HTTP, gRPC, очереди) должны заниматься только границами протокола. Они читают запрос, валидируют форму (обязательные поля, формат, лимиты), собирают команду для сервиса и превращают ошибки в понятный ответ.
Пример: handler принимает email и password, проверяет, что email похож на email и длина пароля в пределах, вызывает AuthService.Login(...), а дальше мапит ошибки: неверные данные в 401, конфликт в 409, остальное в 500. В handler не должно быть SQL, правил скидок, расчетов лимитов и сложных условий по ролям.
Service описывает поведение системы: что можно, когда можно и кому можно. Здесь живут проверки прав, бизнес-валидация (смысловая, а не «строка не пустая»), оркестрация нескольких репозиториев и внешних клиентов, а также транзакции на уровне сценария.
Если нужно «создать заказ, списать бонусы, записать аудит», это работа сервиса. Он решает порядок шагов и где откатиться при ошибке. Транзакцию обычно открывает именно сервис, потому что только он понимает границы сценария.
Repo отвечает за доступ к данным: SQL-запросы, маппинг строк в структуры, работу с индексами и базовую оптимизацию. Repo не должен решать, «можно ли пользователю удалять запись». Это решение сервиса.
Удобно держать в repo методы в стиле GetByID, List, Create, UpdateStatus и возвращать различимые ошибки (например, «не найдено», «конфликт уникальности»).
Про модели и DTO лучше договориться заранее, иначе круговые импорты почти гарантированы:
Ошибки тоже лучше сделать единым языком. Практичный вариант: пакет internal/errs с типами вроде NotFound, Forbidden, Conflict, а сервис возвращает их наружу. Handler только переводит их в статус-коды и текст ответа.
Чтобы проект не расползался, договоритесь о направлении зависимостей. Самая простая модель: транспортный слой (handlers) вызывает бизнес-логику (service), а бизнес-логика обращается к данным (repo). И только так.
Главные запреты скучные, но экономят месяцы. Репозиторий не должен знать ничего о хендлерах и сервисах: никаких импортов ваших пакетов handler/service, никаких типов из них, никаких ошибок, «заточенных» под HTTP-ответ. Иначе repo начнет «подсказывать», как отвечать пользователю, и ответственность смешается.
Так же важно, чтобы service не тянул транспорт. Если в service появляются net/http, gin, grpc, middleware или детали контекста роутера, бизнес-логика привязывается к конкретному способу доставки. Завтра вы захотите дергать тот же код из очереди или cron, и придется переписывать половину.
Обычно цикл начинается, когда service хочет «умный repo», а repo хочет «удобные ошибки сервиса». Лечится просто: интерфейсы объявляйте в service, а реализацию держите в repo. Тогда service зависит от абстракции, а repo реализует ее и не тянет сервисные пакеты.
// package service
type UserRepo interface {
GetByID(ctx context.Context, id int64) (User, error)
Save(ctx context.Context, u User) error
}
type UserService struct {
repo UserRepo
}
Задайте один вопрос: «Могу ли я заменить транспорт, не трогая бизнес-логику?» Если ответ «нет», значит в service просочились детали хендлеров.
Еще два быстрых сигнала:
Если вы генерите заготовки в TakProsto, эти правила стоит закрепить сразу: так проще экспортировать код и не разгребать зависимости, которые выросли «по пути».
Если вы начинаете новый Go-сервис маленькой командой, цель на первый вечер простая: договориться о границах и собрать минимально рабочий скелет, который не будет мешать через месяц.
Сначала выберите 1-2 доменных модуля и назовите их так, как вы говорите о них в задачах. Например: users и orders. Не дробите на микромодули заранее: потом проще выделить, чем склеивать обратно.
Дальше сделайте каркас, где понятно, где вход, где сборка зависимостей, а где бизнес-логика:
cmd/api/main.go
internal/app/app.go
internal/users/handler.go
internal/users/service.go
internal/users/repo.go
internal/orders/...
internal/platform/db/...
Теперь проложите самый важный шов: сервис не должен знать про базу напрямую. В service описываете интерфейс репозитория, а реализацию подключаете при сборке в internal/app.
Набор действий на вечер обычно укладывается в 5 шагов:
users, orders) и заведите по папке на модульcmd для точки входа и internal/app для сборки зависимостей (конфиг, логгер, БД, сервисы и хендлеры)service опишите нужные методы и интерфейс Repo, а в repo сделайте первую реализацию (PostgreSQL или временно in-memory)handler: разберите вход, вызовите сервис и отдельно решите, как ошибки сервиса превращаются в HTTP-ответы (один файл с маппингом сильно помогает)Конкретный пример: вы делаете POST /users и GET /users/{id}. Вечером достаточно, чтобы сервис возвращал понятные ошибки вроде ErrNotFound и ErrValidation, а хендлер переводил их в 404 и 400. На следующий день вы уже сможете расширять функциональность, не переписывая структуру проекта и не споря «куда это положить».
Маленькая команда обычно выигрывает скоростью, но проигрывает дисциплиной границ. Пара неудачных решений, и через месяц уже страшно трогать код: непонятно, где правда, а где временный костыль.
Одна из самых частых проблем - смешать структуры для внешнего API и внутренние модели хранения. Сначала удобно: одна struct и для JSON, и для базы. Потом появляются поля, которые нужны только клиенту или только таблице, и вы начинаете городить теги, указатели, omitempty и хаки для миграций. Хороший признак, что пора разделять: вы боитесь добавить поле, потому что не уверены, что сломаете.
Вторая ловушка - прятать бизнес-правила в handlers. Там быстро появляются проверки статусов, расчеты, лимиты, правила доступа. В итоге handler превращается в мини-сервис, а service слой пустой. Держите простое правило: handler знает про HTTP, авторизацию и валидацию формата, но не знает, «как устроен бизнес».
Третья ловушка - ранняя абстракция. Десятки интерфейсов «на будущее» выглядят красиво, но добавляют шум: сложно понять, что реально меняется, а что просто декорация. Интерфейс нужен, когда у вас есть минимум две реализации или когда без него нельзя нормально тестировать. Во всех остальных случаях лучше начать с конкретного типа и вынести интерфейс позже.
Еще две типичные мины - глобальные синглтоны и бесконечные util-пакеты. Синглтоны усложняют тесты и делают зависимости неявными. А общий util со временем становится свалкой: там лежат и форматирование дат, и парсинг токенов, и куски бизнес-логики.
Небольшая памятка, чтобы не скатиться:
Если вы собираете сервис в TakProsto, эти правила особенно полезны: платформа быстро дает рабочий каркас, и именно договоренности по границам помогают сохранить понятный код при быстрых итерациях.
Представим маленький сервис «Заявки»: создать заявку, получить список, поменять статус. Три эндпоинта: POST /requests, GET /requests, PATCH /requests/{id}/status. Этого достаточно, чтобы увидеть границы слоев и не плодить сущности.
Для такого набора обычно хватает нескольких файлов, привязанных к одному модулю (requests): handler для транспорта, service для правил и сценариев, repo для SQL. Если модели хранения заметно отличаются от доменных, имеет смысл держать их в repo отдельным файлом.
В обработчике важно делать только то, что связано с протоколом: распарсить JSON, прочитать id из пути, вернуть корректный код ответа. Проверки «статус входит в набор допустимых» и «пользователь может менять эту заявку» должны жить в сервисе, а не в handler и не в repo.
type CreateInput struct {
Title string
Description string
}
func (s *RequestsService) Create(ctx context.Context, userID int64, in CreateInput) (Request, error) {
if strings.TrimSpace(in.Title) == "" {
return Request{}, ErrValidation
}
// Правило: по умолчанию статус New
params := CreateParams{Title: in.Title, Description: in.Description, AuthorID: userID, Status: "New"}
return s.repo.Create(ctx, params)
}
type CreateParams struct {
Title, Description, Status string
AuthorID int64
}
func (r *RequestsRepo) Create(ctx context.Context, p CreateParams) (Request, error) {
// Только запись и чтение из БД, без бизнес-правил
// INSERT ... RETURNING id, ...
}
Чтобы меньше спорить о названиях, заранее выберите простой паттерн:
CreateInput - то, что сервис принимает от handlerCreateParams - то, что repo получает для записиRequest - сущность, которую сервис возвращает наружуUpdateStatusInput и UpdateStatusParams - по той же схемеТак код остается предсказуемым: handler переводит HTTP в Input, service принимает решения, repo молча читает и пишет.
В маленькой команде тесты должны помогать двигаться быстрее, а не становиться отдельным проектом. Проще всего держать фокус на трех местах, где баги появляются чаще всего: бизнес-правила, работа с БД и границы HTTP.
Тесты сервиса должны быть быстрыми и точными. Репозиторий здесь лучше подменять простым ручным мок-объектом, чтобы проверять именно логику и ошибки.
Например: CreateUser не должен создавать пользователя, если email пустой; должен вернуть понятную доменную ошибку; должен вызвать repo.Save один раз при корректных данных.
Репозиторные тесты ловят то, что не поймают сервисные: неправильные поля, JOIN, порядок параметров, конфликт уникального индекса. Варианта два: поднять тестовую базу и прогонять реальные запросы, либо делать контрактные проверки (например, что запрос возвращает нужные колонки и корректно маппится).
Чтобы не утонуть, выберите минимум проверок:
Хендлеры стоит тестировать по краям: парсинг входа, коды ответов, маппинг ошибок сервиса в HTTP. Обычно хватает 2-3 тестов на хендлер: валидный запрос, плохой JSON/параметр и доменная ошибка (например, «email занят» -> 409).
Фикстуры и фабрики лучше держать в тестах, а не в прод-коде: helper-функции в файлах *_test.go, плюс testdata для JSON-примеров. Так вы не тащите тестовые зависимости и данные в сборку.
Главное правило экономии: вместо попытки покрыть все ветки сделайте несколько ключевых сценариев end-to-end по смыслу (создать, обновить, получить). Если эти сценарии стабильны, рефакторинг по слоям становится безопаснее.
Перед мерджем полезно на пару минут пройтись по простым правилам. Они не про «красоту», а про предсказуемость: чтобы новые фичи добавлялись быстро и одинаково.
Проверьте изменения по списку:
if про статусы, права, лимиты и переходы по сценариюfmt.Errorf("404") и случайных строк по проекту)Мини-сценарий для самопроверки: вы добавили «блокировку пользователя». Если repo сам решает, что админов блокировать нельзя, и возвращает «нельзя» строкой - это красный флаг. Repo должен уметь прочитать пользователя и сохранить новый статус, а запрет «админов нельзя» живет в service и выражается доменной ошибкой.
Если вы делаете сервис в TakProsto, удобно держать такой чеклист прямо в описании шаблона модуля, чтобы новые части проекта рождались одинаковыми и без лишних обсуждений.
Чтобы проект не расползся через месяц, договоренности нужно не просто проговорить, а зафиксировать. Достаточно одного файла в репозитории на 2-3 страницы: что такое handler/service/repo именно у вас и что запрещено.
Хорошая практика для маленькой команды - делать решения по умолчанию простыми. Тогда спорные случаи становятся редкими, а код-ревью идет быстрее.
Что обычно дает максимальный эффект без лишней бюрократии:
user_handler.go, user_service.go, user_repo.go), чтобы поиск был предсказуемымШаблон важен не из-за папок, а из-за скорости. Например, вы добавляете новый ресурс «Coupons»: копируете заготовку, меняете интерфейсы, и уже через час понятно, где будет валидация, где транзакции, а где SQL.
Усложнять стоит только по сигналам. Если в service появляется много правил, которые не относятся к HTTP и БД, и они нужны в нескольких местах, значит пора выделять отдельный пакет домена (например, domain/coupon) с чистыми типами и логикой.
Если хочется быстро собрать каркас и не тратить вечер на рутину, можно использовать TakProsto (takprosto.ai): в режиме планирования описываете сущности и сценарии, платформа генерирует структуру и заготовки, а затем вы экспортируете исходники и ведете проект как обычный Go-репозиторий.
Полезное правило напоследок: любые исключения из границ должны быть явными и редкими. Если исключения становятся нормой, значит границы нужно пересмотреть, а не «терпеть» их в коде.
Обычно виноваты размытые границы ответственности: хендлеры лезут в SQL, репозитории знают про JSON, а бизнес-правила размазаны по проекту. Самый быстрый фикс — договориться, кто кого может вызывать, и придерживаться этого в каждом новом изменении.
Handler должен заниматься только транспортом: разобрать вход, проверить формат, вызвать сервис и перевести доменные ошибки в ответ протокола. Если в handler появляется SQL или продуктовые правила, он начинает разрастаться и становится самым хрупким местом.
Service — это место для бизнес-правил и сценариев: проверки прав, смысловая валидация, порядок шагов, реакции на конфликты, границы транзакций. Он не должен знать, что его вызвали по HTTP, поэтому коды ответов, JSON и детали роутера там лишние.
Repo должен только читать и писать данные: SQL-запросы, маппинг строк в структуры, обработка ошибок доступа к данным. Как только repo начинает решать «можно/нельзя» по тарифам, ролям или статусам, он превращается в второй сервис, и отладка становится тяжелее.
Начните с простого: cmd для точки входа, internal для всей логики, отдельно migrations и при необходимости configs. Если почти все живет в internal, держать границы проще, а «общие» пакеты не превращаются в свалку.
Самое понятное правило — зависимости только вниз: handler вызывает service, service вызывает repo, и никак иначе. Важно фиксировать это на ревью, потому что одна «удобная» правка (например, SQL в handler) обычно тянет за собой новые нарушения.
Обычно цикл появляется, когда repo хочет использовать ошибки или типы из service, а service — реализацию repo. Практичный подход: интерфейсы репозитория объявляйте в service, а реализацию держите в repo; тогда service зависит от абстракции, а repo не тянет сервисные пакеты.
Разделяйте модели по назначению: DTO для API живут рядом с handler, доменные типы — рядом с service, модели хранения (если нужны отдельно) — в repo. Это чуть больше кода на маппинг, зато меньше сюрпризов, когда меняется формат ответа или схема таблицы.
Сделайте один маленький модуль (например, users) с тремя файлами: handler/service/repo, и проведите один сценарий end-to-end вроде «создать и прочитать». Зафиксируйте правила импортов и типы ошибок сразу — тогда новые ресурсы будут добавляться по тому же шаблону без споров «куда класть».
Быстрее всего окупаются тесты сервиса на бизнес-правила и маппинг ошибок, плюс несколько проверок repo на реальные запросы и контракты с БД. Для handler обычно достаточно тестов на границы: валидный запрос, плохой ввод и перевод доменной ошибки в нужный статус.