Понятно о том, как Тим Бернерс‑Ли придумал Web и почему URL, HTTP и HTML стали фундаментом сайтов, API и мобильных приложений.
Web часто путают с «интернетом», хотя это разные уровни.
Интернет — это сеть сетей: кабели, маршрутизаторы, протоколы передачи данных и способ доставить пакеты от одного компьютера к другому.
Web (Всемирная паутина) — это сервис поверх интернета: правила, по которым мы находим, запрашиваем и отображаем документы и данные. Если интернет отвечает на вопрос «как доставить», то Web — «что именно запрашивать и как это представить человеку (или программе)».
У Web есть три опоры, и каждая закрывала конкретную проблему.
URL дал единый способ адресовать ресурс: «вот где он находится и как к нему обратиться». До этого обмен файлами и документами был слишком привязан к конкретным системам и каталогам.
HTTP стал понятным «языком общения» между клиентом и сервером: как попросить ресурс, как получить ответ, как сообщить об ошибке. Важная особенность — простота: схему запрос/ответ легко реализовать и человеку, и машине.
HTML описал формат документа, который понимает браузер: текст, ссылки, структура. Ссылки сделали Web нелинейным — можно переходить от одного источника к другому, не зная заранее, где они лежат.
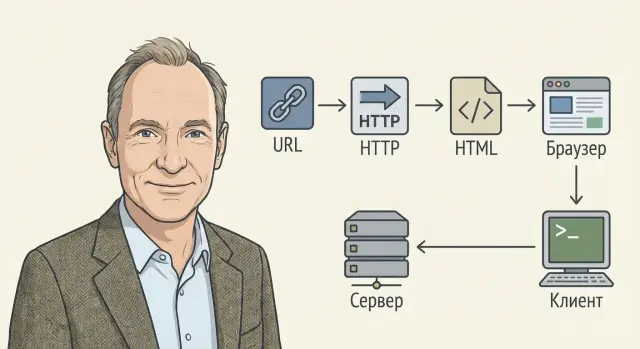
В связке эти три идеи оказались практичными: URL говорит, что и где; HTTP — как запросить; HTML — как показать.
Даже если вы делаете не «сайт», а мобильное приложение, личный кабинет, внутреннюю панель или интеграцию между сервисами — вы почти наверняка опираетесь на web-стандарты: адреса ресурсов, HTTP-запросы, форматы документов и данных, а также инфраструктуру браузера и веб-серверов.
Именно поэтому понимание основ URL/HTTP/HTML помогает не только разработчикам, но и продактам, аналитикам, техписателям и всем, кто проектирует пользовательский путь и интеграции.
Дальше мы по отдельности разберём URL, HTTP и HTML, затем соберём картину целиком (что происходит от ввода адреса до появления страницы), поговорим о том, как из веб-страниц выросли API и веб-приложения, и закончим практическими темами — безопасностью, кэшем и производительностью. Всё — простым языком, без погружения в детали реализации.
К концу 1980-х интернет уже существовал, но он не был «единым местом для чтения и публикации». В научных организациях пользовались электронной почтой, FTP, телеконференциями и закрытыми базами знаний. Проблема была не в отсутствии данных, а в том, что документы жили в разных системах, с разными правилами доступа и разными форматами. Найти нужную версию файла и понять, где она лежит, часто было сложнее, чем её прочитать.
Тим Бернерс‑Ли — инженер и исследователь, работавший в CERN. Он наблюдал, как большие команды теряют время на «стыковку» информации между отделами и проектами.
Его ключевая идея была простой и при этом мощной: сделать систему, где любой документ может ссылаться на любой другой, а переход по ссылке работает одинаково независимо от того, на каком компьютере и в какой сети лежит материал.
В 1989 году Бернерс‑Ли оформил предложение по системе управления информацией, ориентированной на гипертекст. В 1990–1991 годах появились первые практические реализации:
Важно понимать: Web не был одним готовым продуктом. Бернерс‑Ли предложил набор открытых стандартов и подход к публикации, который мог реализовать любой желающий.
Именно выбор в пользу стандартов, а не закрытой платформы, сделал Web масштабируемым: разные браузеры и серверы могли взаимодействовать, потому что опирались на общие правила — как на «грамматику» и «адресную книгу» для документов.
URL (Uniform Resource Locator) — это «адрес» ресурса в Web. Важно слово ресурса: URL может указывать не только на HTML‑страницу, но и на картинку, PDF, видео, JSON‑ответ API, файл для скачивания или конкретный фрагмент внутри документа.
Именно благодаря URL любая сущность в Web получает ссылку, которой можно поделиться, сохранить в закладки, вставить в письмо или использовать в коде.
Типичный URL собирается из нескольких частей. Проще всего понять их на примере:
https://example.com/products/shoes?color=black&size=42#reviews
https — как именно обращаться к ресурсу (чаще всего http или https).example.com — где находится ресурс (домен/сервер)./products/shoes — «папка/маршрут» внутри сайта или сервиса.?color=black&size=42 — уточнения: фильтры, сортировка, пагинация, режимы.#reviews — ссылка на место внутри страницы (обычно обрабатывается браузером и не отправляется на сервер).В реальных продуктах к этому добавляются порт (например, :8080) и иногда пользовательские части, но базовая логика остаётся той же: URL фиксирует способ доступа, место и конкретный вариант ресурса.
https://example.com/docs/start. Её используют, когда нужно однозначно указать ресурс вне контекста текущей страницы: в письмах, документации, внешних интеграциях./docs/start или ../assets/logo.svg. Она удобна внутри сайта и приложений: при переносе между доменами или окружениями (dev/stage/prod) такие ссылки часто «живут» стабильнее.URL — часть интерфейса продукта. Хорошие адреса:
/products/12345 лучше, чем /index.php?id=12345./orders/781), настройки выборки — в query (?page=2&sort=date).Для эндпоинтов API те же принципы особенно важны: читаемые URL упрощают поддержку, а стабильные экономят время командам и клиентам, которые на них завязаны.
HTTP (HyperText Transfer Protocol) — это набор правил, по которым браузер и веб‑сервер обмениваются сообщениями. Если URL — это «куда идти», то HTTP — «как разговаривать», чтобы получить результат.
Клиент — тот, кто инициирует запрос (обычно браузер или мобильное приложение). Сервер — тот, кто принимает запрос, выполняет работу (например, ищет данные в базе) и возвращает ответ.
Важно: сервер не «угадывает», чего вы хотите. Он отвечает только на конкретные запросы.
Общение происходит парами: request → response.
Заголовки (headers) — это служебные параметры. Они помогают договориться о формате и условиях обмена: какой тип данных отправляется (Content-Type), можно ли кэшировать ответ (Cache-Control), каким языком предпочитает пользоваться клиент (Accept-Language) и т.д.
Метод влияет не только на смысл, но и на ожидания: например, GET обычно не должен изменять данные, а POST — может.
Коды — это быстрый «диагноз»: они помогают отличать проблему контента (404) от проблемы инфраструктуры (500) и правильно выстраивать мониторинг.
HTML (HyperText Markup Language) — это язык разметки. Он не описывает «алгоритмы» и не выполняет вычисления сам по себе, как это делает программирование. Его задача проще и фундаментальнее: сообщить браузеру, что именно находится в документе и как элементы связаны между собой.
Если представить веб-страницу как книгу, то HTML — это оглавление и типографская разметка: где заголовок, где абзац, где список, где цитата. Такая структура нужна не только для красоты. Она помогает браузеру корректно отобразить страницу, поисковым системам — понять смысл, а вспомогательным технологиям (например, экранным дикторам) — озвучить контент.
Даже самый простой HTML-документ строится вокруг нескольких базовых идей:
Важно: HTML не «рисует» интерфейс в точных пикселях. Он задаёт семантику и структуру, а визуальные правила передаются другим инструментам.
Когда браузер получает HTML, он не просто выводит его как текст. Он разбирает разметку и строит внутреннюю модель страницы — DOM (Document Object Model). Упрощённо это дерево: документ → секции → элементы → текст. Затем браузер по этой модели рассчитывает расположение элементов и отображает результат.
DOM важен тем, что это «живая» структура: её можно читать и изменять во время работы страницы.
Но роль HTML остаётся центральной: без понятной разметки сложнее обеспечить доступность, поддержку разных устройств и предсказуемую работу браузера. Хороший веб-интерфейс почти всегда начинается с аккуратного HTML‑каркаса, а уже затем «обрастает» стилями и интерактивностью.
Web — это не «магия браузера», а цепочка понятных шагов. Если понимать их в общих чертах, проще находить узкие места и улучшать скорость и стабильность продукта.
Когда вы вводите URL и нажимаете Enter, обычно происходит следующее:
GET /), вместе с заголовками — языки, поддерживаемые форматы, куки, кеш-условия.Браузер отвечает за сетевые запросы, хранение кеша, выполнение JavaScript и отображение интерфейса.
Веб‑сервер/приложение принимает HTTP-запрос, решает «что вернуть», проверяет права, формирует ответ. Если нужны данные, приложение обращается к базе данных (или кэш‑хранилищу), собирает результат и упаковывает его в HTML/JSON.
Важно: база данных почти никогда не «разговаривает» напрямую с браузером — она спрятана за сервером и его логикой.
Кэш может быть:
Обычно самые доступные улучшения такие: уменьшить «вес» страниц и ресурсов, сократить количество запросов, настроить корректные заголовки кеширования, убрать лишние редиректы, следить за временем ответа сервера и за медленными запросами к базе. Эти точки дают заметный эффект даже без погружения в низкоуровневые детали.
Парадокс Web в том, что он не привязан к конкретному языку программирования, операционной системе или устройству. Его «суперсила» — в простых общих правилах: URL как адрес, HTTP как способ договориться о запросе и ответе, HTML как базовый формат представления.
Эти стандарты важнее любого фреймворка: технологии меняются каждые несколько лет, а договорённости о том, как находить ресурс и как обмениваться данными, остаются.
В практической разработке это особенно заметно в продуктах «из чата в приложение». Например, в TakProsto.AI вы описываете интерфейс и бизнес‑логику словами, а платформа собирает полноценное веб‑приложение (React на фронтенде, Go + PostgreSQL на бэкенде). Но в основе всё равно те же базовые контракты: маршруты (URL), обмен (HTTP) и структура страниц/шаблонов (HTML).
Если вы пишете сервис на любом стеке — хоть на Java, хоть на Go — он всё равно может говорить с миром через HTTP и быть доступным по URL. Это создаёт эффект совместимости «по умолчанию»: один и тот же серверный продукт становится доступен тысячам разных клиентов без специальных SDK.
Изначально Web был про гипертекстовые страницы. Но как только браузеры научились исполнять сценарии, обновлять части страницы и хранить состояние, Web стал платформой для приложений: почта, карты, банковские кабинеты.
Параллельно те же принципы перешли в сервисы: API используют URL для идентификации ресурса и HTTP-методы для действий. По сути, веб-приложение и REST API стоят на одном фундаменте — меняется только «упаковка» данных.
HTTP оказался удобным общим языком:
Это снижает стоимость разработки: серверной части не нужно знать, кто именно клиент — важно лишь соблюдать контракт.
Web сознательно принимает компромиссы: сетевые задержки, ограничения безопасности браузера (песочница, политики доступа), необходимость учитывать кэширование и версионирование.
Но эти ограничения предсказуемы и стандартизованы — поэтому команды часто выбирают Web не «потому что идеально», а потому что масштабируемо по совместимости и понятно, как обслуживать и развивать.
Когда Web начинался, основным «контентом» были документы: HTML‑страницы, которые открывались в браузере. Но фундамент — URL + HTTP — оказался универсальным. Если по URL можно получить страницу, то по тому же принципу можно получить и данные.
Так родились API: интерфейсы, где ресурсом становится не «страница», а, например, заказ, пользователь или список товаров.
Полезная ментальная модель: URL адресует вещь, а не действие. Тогда /users/42 — это конкретный пользователь, /orders/2025-12 — набор заказов за период, а не «выполнить операцию». Такой подход упрощает навигацию, документацию и поддержку.
API использует тот же «язык общения», что и веб‑страницы, просто меняется содержание ответов.
GET — получить представление ресурса (прочитать данные)POST — создать новый ресурс или запустить процессPUT/PATCH — обновить ресурс (целиком или частично)DELETE — удалитьКоды ответов помогают клиенту понять результат без чтения «простыней текста»:
200 OK, 201 Created, 204 No Content — успех400 Bad Request, 401 Unauthorized, 403 Forbidden, 404 Not Found — ошибки клиента409 Conflict — конфликт состояния (например, дубль)500 Internal Server Error — ошибка сервераHTML удобен для интерфейса человека. Для программ чаще возвращают JSON, файлы или другие форматы — это определяется заголовками и типом содержимого.
GET /api/v1/users/42
Accept: application/json
HTTP/1.1 200 OK
Content-Type: application/json
{"id":42,"name":"Анна"}
Версионирование (например, /api/v1/...) защищает клиентов от внезапных поломок. Пути должны быть последовательными: одинаковые сущности — одинаковые шаблоны URL.
Ошибки стоит делать «читаемыми» и для человека, и для программы: краткое сообщение, стабильный код ошибки, детали для исправления. Тогда API становится таким же понятным «разделом Web», как и обычные страницы — просто адресованным приложениям.
Когда Web стал местом для покупок, переписок и рабочих сервисов, «просто открыть страницу» стало недостаточно. Нужны гарантии: что вы подключились к нужному сайту, что данные по пути никто не подменил, и что логин/пароль не утекут в сеть.
HTTPS — это HTTP поверх шифрования (TLS). Он решает три практичные задачи:
Важно: HTTPS защищает передачу данных, но не делает сам сайт «безопасным по определению» — ошибки приложения и утечки на сервере он не отменяет.
HTTP по своей природе не хранит состояние: каждый запрос — как новый. Чтобы сайт узнавал вас между переходами, используются куки — небольшие значения, которые браузер хранит и автоматически отправляет на тот же сайт.
Обычно в куке лежит не «вся информация о пользователе», а идентификатор сессии. Сервер по нему понимает, кто вы, и какие права у вас есть.
Иногда браузер «не даёт» странице вызвать чужой API. Это CORS: правило, которое ограничивает запросы со страницы к другому домену, если сервер явно не разрешил такой доступ.
Это защита пользователя: вредная страница не должна тихо читать ответы от сервисов, где вы уже авторизованы.
Скорость веб-продукта часто упирается не в «мощность сервера», а в то, сколько раз клиенту приходится ходить по сети и сколько данных он каждый раз тянет. Хорошая новость: HTTP изначально умеет помогать — через кэширование, условные запросы и сжатие.
Кэш — это сохранённая копия ответа, которую браузер (или CDN) может использовать повторно.
Лучше всего кэшируются «статические» ресурсы: CSS, JS-бандлы, шрифты, иконки, изображения. Их можно отдавать с долгим сроком жизни, потому что они редко меняются.
Обычно для этого задают правила в заголовках (не обязательно знать их наизусть, важно понимать смысл):
Cache-Control: public, max-age=31536000, immutable
Это говорит: «можно хранить долго и не проверять заново». Чтобы обновления всё же доходили до пользователей, применяют версионирование в URL (например, app.8f3a1c.js), тогда новая версия — это новый адрес, и кэш не мешает.
Для данных, которые меняются иногда (HTML, JSON, изображения без хэша в имени), полезны условные запросы. Сервер сообщает маркер версии (ETag) или дату изменения (Last-Modified). Клиент при повторном запросе спрашивает: «ничего не изменилось?» — и если так, получает короткий ответ 304 без тела.
ETag: "v3"
Last-Modified: Tue, 10 Dec 2024 12:00:00 GMT
Результат: тот же URL, но почти нулевой трафик.
Сжатие (gzip/brotli) уменьшает размер HTML/JSON/JS — это особенно заметно на мобильных сетях. Для больших списков и лент важнее не сжатие, а сокращение объёма ответа: пагинация, лимиты, выбор полей, «ленивая» подгрузка.
Частые проблемы:
Vary (например, забыли про Accept-Encoding): кэш отдаёт не тот вариант ресурса.Практическое правило: HTML и API кэшировать осторожно (коротко и с валидацией), а статические ассеты — долго, но только с версионированием в URL.
Этот чек-лист помогает быстро проверить, что ваш продукт «говорит на языке Web» так, как ожидают браузеры, поисковые системы, интеграции и люди. Он не про конкретный фреймворк — про фундамент: URL, HTTP, HTML и безопасность.
Если вы собираете продукт в формате «быстро проверить гипотезу → довести до продакшена», этот фундамент особенно важен: он уменьшает количество сюрпризов при релизах. В TakProsto.AI для этого есть удобные механики — планирование изменений (planning mode), снапшоты и откат (rollback), экспорт исходников и развёртывание с собственным доменом; при этом данные и инфраструктура остаются в России.
Хороший URL можно отправить коллеге, сохранить в закладки и открыть через год.
/blog/kak-rabotaet-http, а не /p?id=12345.HTTP — это договор о том, «что произошло» и «что делать дальше».
Даже если у вас SPA, базовая структура важна.
h1 на страницу, корректная иерархия заголовков.label, у изображений — осмысленный alt (или пустой, если декоративное).<a href> (а не клики по div), чтобы работали клавиатура, вкладки и копирование адреса.Secure, HttpOnly, адекватные SameSite.500 без текста или 200 с сообщением “error”./offer, завтра /offer2 без редиректов./pricing для тарифов, /blog для материалов.Лучший способ понять возможности ТакПросто — попробовать самому.