Понятно объясняем, где хранить состояние в AI‑приложении: UI, сессии, БД и кэш. Как синхронизировать фронтенд и бэкенд и избегать ошибок.
Состояние — это все данные, которые «помнятся» между действиями пользователя и шагами системы и влияют на то, что произойдёт дальше. Это не только то, что отображается на экране, но и то, что скрыто в логике: кто пользователь, какой у него контекст, какие операции уже запущены и какие правила нужно применить.
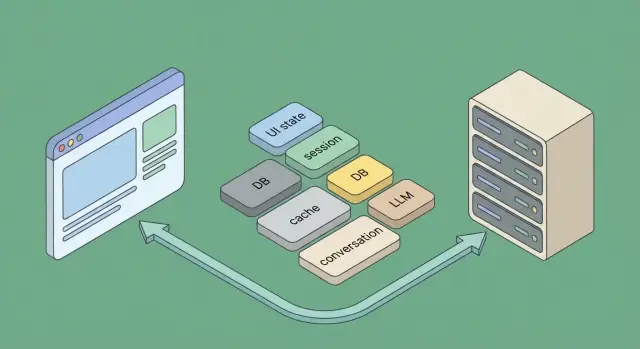
В обычных веб‑приложениях состояние часто выглядит так:
В AI‑приложениях добавляется специфический слой:
AI‑запросы часто длинные, а результат может приходить частями (стримингом). Модель может вызывать инструменты (поиск, БД, внешние API) и делать повторные вызовы — например, если нужно уточнить данные или повторить шаг после ошибки. В таких цепочках легко «потерять» контекст или случайно выполнить действие дважды.
Поэтому состояние в AI‑приложении — это ещё и ответы на вопросы: какой шаг пайплайна сейчас выполняется, какие данные подтверждены, какие версии подсказок/контекста применены.
Чтобы состояние не превращалось в хаос, заранее договоритесь, где что живёт:
Это разделение снижает количество багов, упрощает отладку и делает поведение AI‑сценариев предсказуемым даже при обрывах сети и повторных попытках.
Отдельно полезно помнить: в современных «vibe‑coding» подходах, когда приложение собирается через диалог с платформой (например, TakProsto.AI), архитектурные решения про состояние лучше фиксировать сразу — как часть требований. Тогда генерация интерфейса, API и фоновых задач получается согласованной, а не «слепленной» из разрозненных экранов.
Фронтенд‑состояние — это всё, что нужно, чтобы интерфейс выглядел и реагировал «как ожидается» прямо сейчас, даже если сеть медленная или пользователь случайно обновил страницу. В AI‑приложениях особенно важно отделять удобство интерфейса от «источника правды» (он обычно на бэкенде), иначе легко получить расхождения: UI показывает одно, а сервер считает другое.
Классические примеры UI state:
Это состояние почти всегда безопасно хранить рядом с компонентами (React/Vue/Svelte‑стор, state management‑библиотека), потому что его потеря не ломает бизнес‑логику.
Отдельный слой — клиентский кэш данных, пришедших с бэкенда:
Полезное правило: кэш на клиенте должен быть восстанавливаемым. Если данные критичны, они должны подтверждаться бэкендом.
Достаточно localStorage или IndexedDB, когда вы сохраняете:
Нельзя или рискованно, когда речь о:
Главное практическое правило: храните на клиенте только то, что можно потерять без ущерба. Всё, что влияет на деньги, права, итоговый результат или юридически значимые действия, должно жить на бэкенде и приходить на фронтенд как отображаемая проекция.
Бэкенд — это место, где живёт «истина» о пользователе, его правах и данных. Даже если интерфейс выглядит как простой чат, сервер всё равно нужен: он связывает сообщения с конкретным пользователем, хранит результаты, применяет правила доступа, следит за лимитами и обеспечивает воспроизводимость ответов.
Фронтенд может держать временные значения (ввод, открытые вкладки, черновики), но сервер должен быть источником правды для того, что влияет на продукт и деньги: профиль пользователя, тариф, остаток лимитов, историю оплат, доступ к документам, настройки приватности.
Практическое правило: если после перезагрузки страницы данные должны остаться, а также если их нужно разделять между устройствами — это server state. Храните его в БД и отдавайте фронтенду через API, чтобы избежать «рассинхрона» и неожиданных состояний при обновлениях.
AI‑запрос — это не только текст пользователя. На сервере важно фиксировать:
Зачем это делать на бэкенде: чтобы можно было объяснить результат, повторить запрос при расследовании инцидента и безопасно катить изменения. Если промпт поменялся — новая версия должна быть явно записана, иначе две одинаковые с виду операции начнут давать разные ответы.
Часть операций в AI‑приложениях не укладывается в один HTTP‑запрос: индексация файлов, суммаризация больших документов, батч‑обработка. Для этого удобно заводить очередь задач.
На сервере храните состояние выполнения: queued → running → succeeded/failed/canceled, прогресс (если доступен), дедлайны, количество попыток и причину ошибки. Ретраи должны быть контролируемыми: с экспоненциальной задержкой и ограничением по времени, чтобы задача не «мучилась» бесконечно и не тратила бюджет.
Без бэкенда чат быстро превращается в набор локальных сообщений без гарантий: нельзя надёжно применить лимиты, защитить данные, восстановить историю на другом устройстве, обработать долгие операции и обеспечить стабильную бизнес‑логику. Серверное состояние делает поведение приложения предсказуемым — для пользователя и для команды разработки.
Идентификация — это «ключ» к любому состоянию: истории диалога, лимитам, правам доступа, персональным настройкам. В AI‑приложениях ошибка в этом слое быстро превращается в утечку контекста (пользователь видит чужие ответы) или в странные баги (состояние «прыгает» между устройствами).
Короткая сессия живёт минуты или часы и подходит для частых, но безопасных операций: чат, генерация, просмотр истории. Если токен или cookie утекли, ущерб ограничен временем жизни.
Длинная сессия (дни/недели) удобна для «не спрашивать пароль каждый раз», но требует аккуратного управления: ротации токенов, привязки к устройству и нормального logout. Хороший компромисс: короткий access + более длинный refresh.
Cookies удобны для браузера: они автоматически отправляются на сервер. Для безопасности критично выставлять флаги HttpOnly, Secure, SameSite, иначе растёт риск кражи или подмены. Важно помнить про CSRF: если вы полагаетесь на cookies, нужна защита (например, CSRF‑токен).
JWT/токены часто используют в мобильных клиентах и SPA. Плюс — проще работать с API и кросс‑доменными сценариями. Минус — если хранить токен в небезопасном месте (например, в доступном JavaScript‑хранилище), его легче украсть. Практика: access‑токен короткий, refresh — хранить максимально защищённо.
Обновление (refresh) должно быть предсказуемым: один запрос — одно обновление, без гонок. Серверу полезно вести список активных refresh‑сессий и уметь отзывать их (logout со всех устройств или только с текущего). Logout — это не «удалить токен на клиенте», а ещё и инвалидировать серверную сессию/refresh, иначе пользователь формально остаётся авторизованным.
Храните минимум, который нужен для управления состоянием и доступом:
user_id — кто это;scope/права — что можно делать (например, доступ к моделям, тарифам, рабочим пространствам);exp) и время выдачи — чтобы контролировать устаревание;device/идентификатор сессии — чтобы различать устройства и корректно завершать конкретную сессию.Чем меньше чувствительных данных вы кладёте в токен/сессию, тем проще безопасность и миграции: профиль и настройки лучше подтягивать из бэкенда по user_id.
Диалог с AI — это не просто набор сообщений. Это «состояние», которое определяет, что модель увидит в следующий момент и почему она отвечает именно так. Ошибки здесь обычно выглядят как «модель забыла важное», «ответила не в том тоне» или «повторила уже сделанное действие».
Есть два базовых подхода.
Модель “сообщение‑за‑сообщением”: вы храните полную ленту (user/assistant/system) и каждый раз собираете контекст заново. Плюсы — проще объяснить и отлаживать: видно, что именно было сказано. Минусы — история растёт, дороже отправлять и сложнее контролировать «шум».
Модель “снимок контекста”: помимо (или вместо) ленты вы храните актуальное представление состояния: резюме диалога, выбранные параметры, извлечённые факты, текущий шаг сценария. Плюсы — компактно и предсказуемо; минусы — нужно аккуратно обновлять снимок и следить за консистентностью.
На практике часто используют гибрид: полная история для аудита + снимок для быстрых и стабильных ответов.
Контекст всегда ограничен: либо лимитом модели, либо бюджетом на запрос.
Практика:
Чтобы можно было объяснить и повторить ответ, версионируйте:
Хорошее правило: каждое сообщение ассистента должно иметь метку вида prompt_version, model_version, context_build_id. Тогда при жалобе «вчера работало» вы сможете восстановить, что именно изменилось — и исправить это без гаданий.
AI‑запросы часто «живут» дольше обычных HTTP‑операций: модель может отвечать 5–30 секунд, а иногда — минуты (RAG, инструменты, несколько вызовов). Чтобы интерфейс не «зависал», состояние длинной операции нужно фиксировать на бэкенде и аккуратно отражать на фронтенде.
Удобно мыслить генерацию как конечный автомат. Минимальный набор статусов: started, running, failed, done (опционально — cancelled).
generation_id.На бэкенде это «источник правды»: даже если вкладка перезагрузилась, по generation_id можно восстановить текущий статус.
При стриминге важно, чтобы частичный текст в UI соответствовал реальному прогрессу на сервере.
Практика: отправлять события (SSE/WebSocket/чанкованный HTTP), где каждый фрагмент имеет порядковый номер (seq) и, при необходимости, курсор. Фронтенд применяет фрагменты только если seq следующий ожидаемый — так вы избегаете дублей и «перепрыгиваний» при переподключениях.
Полезно хранить на бэкенде промежуточный буфер ответа (или ссылки на чанки), чтобы при реконнекте клиент мог запросить «догрузку с seq=N», а не начинать заново.
На фронтенде отмена — это AbortController/cancel‑кнопка. Но главное — довести отмену до сервера: пометить генерацию как cancelled, остановить стрим, прервать вызовы инструментов, закрыть соединения и освободить ресурсы.
Добавляйте таймауты на уровне запроса и на уровне внутренних шагов (например, поиск/инструменты), чтобы «зависшие» операции не удерживали состояние бесконечно.
Сеть рвётся, пользователи жмут «повторить», браузер может переотправить запрос. Чтобы не запускать две генерации, используйте идемпотентный ключ (например, Idempotency-Key), который клиент генерирует один раз на попытку. Бэкенд сохраняет соответствие ключ → generation_id и при повторе возвращает уже существующую операцию и её текущий статус/стрим.
Итог: UI остаётся отзывчивым, сервер — предсказуемым, а состояние длинных операций не «разъезжается» между фронтендом и бэкендом.
Кэш в AI‑приложении — это не «магическое ускорение», а обмен точности на скорость в пределах, которые вы контролируете. Главное правило: кэшируйте только то, что можно безопасно переиспользовать, и делайте это так, чтобы не смешать данные разных пользователей.
Ответы моделей имеет смысл кэшировать, если запрос детерминирован (одинаковые параметры, температура, системный промпт) и результат не зависит от «живого» состояния пользователя. Хороший пример — справочные ответы по статичному документу одной версии.
Эмбеддинги почти всегда выгодно кэшировать: они дорогие, а повторяются часто (одни и те же тексты, документы, запросы). Обычно кэшируют по хэшу нормализованного текста + версии модели эмбеддингов.
Результаты поиска (внутреннего, по базе знаний, по векторному индексу) тоже подходят для кэша, особенно если выдача зависит от версии индекса и фильтров доступа. Это часто даёт больший выигрыш, чем кэширование финального ответа модели.
На «горячем» пути используйте in‑memory кэш в процессе сервера (самый быстрый, но сбрасывается при рестарте и не разделяется между инстансами).
Для общего кэша между инстансами подойдёт Redis‑подобное хранилище: проще контролировать TTL, лимиты и ключи.
CDN — только для статики (JS/CSS, картинки, публичные файлы). Для персонализированных AI‑ответов CDN опасен из‑за рисков утечки.
Рабочая комбинация:
tenant_id:user_id:... — чтобы исключить пересечения.model_version, prompt_version, index_version, doc_version в ключ. Тогда обновления не ломают старый кэш — он просто перестаёт находиться.Риск №1 — устаревшие ответы: лечится TTL + версионирование данных/промптов.
Риск №2 — утечки между пользователями: всегда включайте в ключ контекст доступа (тенант, пользователь, роль) и не кэшируйте «персональные» ответы в общих слоях.
Если сомневаетесь — кэшируйте не финальный ответ, а промежуточные артефакты (эмбеддинги, поиск). Это ускоряет без потери корректности и приватности.
Когда в AI‑приложении появляется несколько компонентов (UI, API, воркеры, LLM‑провайдер), «состояние» перестаёт быть одним объектом. Практично разделять: где хранится источник правды, где — временные статусы, а где — производные структуры для ускорения.
БД — лучший кандидат на роль источника правды для бизнес‑сущностей: пользователи, чаты, платежи, права доступа, версии промптов, итоговые ответы, метаданные документов.
Транзакции помогают удерживать целостность: например, создать сообщение, зафиксировать списание лимита и записать ссылку на задачу генерации нужно либо всё вместе, либо никак.
Аудит важен для разбора инцидентов: кто изменил настройки ассистента, какая версия контекста использовалась, какой результат вернулся. Часто достаточно таблицы событий (append-only) или полей created_at/updated_at + actor.
Очередь или шина событий подходит для длительных операций: извлечение текста, индексирование, генерация, оценка качества. Здесь «состояние» — это статус задачи и её прогресс: queued → running → succeeded/failed/canceled.
Ключевое — ретраи и идемпотентность. Повторная доставка сообщения нормальна, поэтому обработчик должен уметь безопасно «доделать» или понять, что всё уже сделано (например, по idempotency key и записи в БД).
Векторный индекс почти всегда производен: его можно пересобрать из исходных документов и настроек эмбеддингов. Поэтому критичнее хранить «первичку» в БД/объектном хранилище: текст, версии, права доступа, параметры чанкинга.
Сам индекс — оптимизация для поиска. Относитесь к нему как к кэшу с правилами пересборки: при смене модели эмбеддингов или разбиения на чанки индекс нужно обновить, иначе контекст будет «ехать».
Eventual consistency уместна для фоновых частей: индекс может обновиться через минуту после загрузки файла, и это нормально, если UI честно показывает статус.
Строгая согласованность нужна там, где ошибки дорогие: списание лимитов, контроль доступа, фиксация финального ответа, связывание сообщения пользователя с конкретной версией контекста. В таких местах держите источник правды в БД и обновляйте остальные хранилища как производные.
Когда AI‑приложение общается с сервером часто (поиск, генерация, стриминг), основные проблемы состояния обычно не «в модели», а между вкладкой и API: повторные запросы, гонки ответов и тихие перезаписи данных.
Пользователь ожидает мгновенной реакции, поэтому UI часто обновляют оптимистично: показывают новое сообщение, статус «в работе», списывают лимит. Важно хранить локальный «черновик» операции (temporary id, payload, время) и уметь откатывать его при ошибке.
Практика: добавляйте явный статус у каждой операции/сообщения — pending → confirmed → failed, чтобы откат был не «магическим», а предсказуемым.
Дубли появляются из‑за повторной отправки формы, повторного открытия вкладки или ретраев сети. Решение — идемпотентность:
conversationId + clientRequestId).Idempotency-Key (или clientRequestId) и возвращайте уже созданный результат, если ключ повторился.Если два устройства редактируют один диалог/настройки, «последний записавший» может затереть изменения. Минимальный контроль — версии:
version/etag;If-Match: <etag>;Для простых сущностей иногда достаточно last-write-wins, но это должно быть осознанным выбором.
Не полагайтесь на клиентское время для порядка событий. Используйте серверное время и/или монотонные идентификаторы (например, возрастающие sequence‑номера сообщений в диалоге). Тогда поздно пришедший ответ не «перепрыгнет» более новый и UI сможет корректно игнорировать устаревшие результаты.
AI‑приложения ломаются не только «как обычные»: модель может вернуть неожиданный формат, внешний провайдер — временно отказать, а пользователю важно понять, что произошло, и не потерять состояние (ввод, выбранные настройки, черновик сообщения).
Полезно заранее разделить ошибки на несколько типов — и для каждого определить текст, действия и судьбу состояния:
Важно: фронтенд не должен «угадывать» тип ошибки по тексту. Пусть бэкенд возвращает нормализованный код (например, error_type, error_code) и человекочитаемое message.
Повторы должны быть контролируемыми: ограничение числа попыток, экспоненциальная пауза, джиттер, и обязательная идемпотентность по idempotency_key, чтобы повтор не создал дубликаты (заказ, списание, запись в историю диалога).
Для дорогих операций (LLM, поиск, распознавание) добавьте бюджетные предохранители: лимит токенов/вызовов на запрос и «мягкую остановку», если стоимость растёт из-за повторов.
Когда часть системы недоступна, лучше предложить ограниченный сценарий, чем «падать целиком». Примеры: отключить инструменты/плагины и сделать ответ «только моделью», временно убрать персонализацию, использовать более короткий контекст. В UI это должно быть явно отмечено: «работаем в упрощённом режиме», чтобы ожидания совпадали с результатом.
Для расследования «потерянного состояния» нужны сквозные идентификаторы:
request_id — на каждый запрос (включая ретраи)trace_id — на весь пользовательский сценарий/цепочку вызововЛогируйте (с маскированием чувствительных данных) входные параметры: выбранную модель, настройки, размер контекста, ключи кэша, а также версию промпта/шаблона. Тогда поддержку можно свести к короткому вопросу пользователю: «Пришлите request_id из экрана ошибки» — и быстро воспроизвести проблему без догадок.
Когда состояние «плывёт», пользователи видят странные эффекты: кнопка «Отправить» снова активна, хотя запрос уже идёт; прогресс завис на 80%; ответ в чате пришёл дважды; а после обновления страницы «контекст» внезапно пропал. Наблюдаемость помогает быстро понять, на каком участке цепочки это произошло: в UI, в сети, на сервере, в очереди задач или при стриминге.
Логи должны фиксировать не «всё подряд», а ключевые переходы состояния:
Важно: не логируйте чувствительные данные (полный текст промпта, токены, cookies/JWT). Лучше хранить хэши/маски и технические идентификаторы.
Минимальный набор метрик, который показывает, где «застревает» состояние:
Чтобы не гадать, какой серверный лог относится к конкретному клику, используйте распределённую трассировку и единый correlation id.
Практика:
correlation_id при пользовательском действии (например, на «Отправить»).X-Correlation-Id) и в сообщения очереди.В результате вы сможете открыть один id и увидеть полный путь: «клик → запрос → постановка в очередь → старт генерации → стриминг → сохранение результата», а значит — точно найти место, где состояние «теряется».
Управление состоянием в AI‑приложении почти всегда связано с чувствительными данными: тексты диалогов, пользовательские файлы, результаты классификации, токены доступа, промежуточные ответы модели. Ошибки здесь обычно не «косметические»: они приводят к утечкам, подмене контекста или выполнению действий не тем пользователем.
Храните только то, что нужно для сценария, и только на нужное время. Для истории диалога и промежуточных статусов задавайте TTL (время жизни) и политику удаления. Для отладки — отдельный режим с явным согласием и маскированием.
Практика: разделяйте «операционное состояние» (например, progress долгой операции) и «аудит» (кто и что сделал). Операционное состояние может быть короткоживущим и агрегированным, аудит — неизменяемым и ограниченным по доступу.
Административные действия (сброс диалога, просмотр чужих сессий, повторная отправка задач) должны быть защищены отдельными ролями и более узкими scope. Проверяйте права на бэкенде даже если кнопка скрыта на фронтенде.
Важно: привязывайте любое состояние к владельцу (user_id/tenant_id) и проверяйте это на каждом запросе чтения/записи. Это особенно критично для ключей conversation_id и job_id.
API‑ключи провайдеров, секреты подписи JWT, ключи шифрования — только на сервере. Включайте ротацию, ограничивайте права ключей (минимальные разрешения), используйте разные ключи для разных окружений. Если на фронтенде нужен идентификатор — передавайте безопасный токен/ID, а не секрет.
Проверяйте не только «счастливый путь», но и восстановление:
Полезно держать отдельные интеграционные тесты на «сквозной» сценарий: фронтенд → API → очередь/воркер → хранилище → фронтенд, с инъекцией ошибок на каждом шаге.
Если вы делаете AI‑приложение в формате «чат + файлы + фоновые задачи», то описанная модель состояния (UI state на фронтенде, server state в БД, статусы генераций и идемпотентность) хорошо ложится на современные стеки.
Например, в TakProsto.AI этот подход обычно фиксируют уже на этапе проектирования в planning mode: какие сущности живут в PostgreSQL, какие статусы есть у генераций, как устроены ключи идемпотентности и что именно стримится в интерфейс. Это помогает быстрее собрать связку React‑фронтенд + Go‑бэкенд + PostgreSQL, включить деплой и хостинг, а затем безопасно итеративно менять поведение через снимки (snapshots) и откат (rollback). Если нужно — можно экспортировать исходники и развивать проект дальше в своей инфраструктуре.
Для российского рынка также часто важны требования к данным: TakProsto.AI работает на серверах в России и использует локализованные и opensource‑модели, что упрощает обсуждение хранения состояния, логов и доступа в командах, где комплаенс — не формальность, а обязательное условие.
Это все данные, которые сохраняются между действиями пользователя и шагами системы и влияют на дальнейшее поведение.
В AI-сценариях это не только UI-настройки, но и контекст диалога, параметры генерации, статусы задач, версии промптов и результаты вызовов инструментов.
Потому что запросы часто длинные и приходят частями (стриминг), а пайплайн может включать инструменты, очереди и повторы.
Без явного состояния легко:
Держите на фронтенде только то, что можно потерять без ущерба:
Все, что влияет на права, деньги, «истинный» контекст и финальный результат, должно подтверждаться бэкендом.
Храните там безопасные и восстанавливаемые вещи:
Не храните в браузерных хранилищах:
Фиксируйте минимум, который делает результат воспроизводимым:
Практично записывать метки вроде prompt_version, , рядом с каждым ответом ассистента.
Используйте понятную модель состояний и один идентификатор операции:
started → running → done/failed (опционально cancelled),generation_id (или job_id) как ключ восстановления после перезагрузки вкладки.Тогда UI может в любой момент спросить сервер «что сейчас с операцией?» и не полагаться на локальные догадки.
Отправляйте чанки с порядковым номером seq (и при необходимости курсором/offset).
На клиенте применяйте только следующий ожидаемый seq, чтобы избежать дублей и «перепрыгиваний» при реконнекте.
Полезно хранить на сервере промежуточный буфер, чтобы клиент мог догрузить «с seq=N», а не начинать заново.
Сделайте отмену «сквозной»:
cancelled, остановка стрима, прерывание инструментов и освобождение ресурсов.Добавляйте таймауты на внешний запрос и на внутренние шаги, чтобы «зависшие» операции не держали состояние бесконечно.
Нужна идемпотентность.
Idempotency-Key (или clientRequestId) один раз на попытку.generation_id и при повторе возвращает уже существующую операцию.Это защищает от двойных кликов, ретраев сети и повторной отправки браузером.
Минимальный практичный набор:
request_id на запрос и trace_id/correlation_id на сценарий,Чувствительные данные лучше не логировать целиком — используйте маскирование и технические ID.
model_versioncontext_build_id