Пошаговый план: как спроектировать и запустить веб‑приложение для сбора и анализа отзывов, привязанных к функциональным областям и фичам.
Учет фидбэка по фичам — это не «ящик для пожеланий», а инструмент для принятия решений. Хорошее приложение помогает быстро понять, что строить дальше, что срочно чинить и какие ожидания нужно корректно объяснить пользователям (например, почему функция не появится в ближайших релизах).
Что делать дальше: какие фичи дают наибольшую ценность и для каких групп пользователей.
Что чинить: где накопились баги и деградации, которые мешают ключевым сценариям.
Что объяснять: какие вопросы и жалобы повторяются, где не хватает документации, подсказок в интерфейсе или понятных ограничений.
Важно, чтобы итогом были не только «топ‑10 запросов», а конкретные действия: создать задачу в бэклоге, обновить статус, подготовить ответ пользователю, запланировать исследование.
Фидбэк полезно разделять хотя бы на четыре типа: идеи (хочу улучшение), баги (не работает), вопросы (не понимаю, как), жалобы (не устраивает результат/ограничение). У этих типов разные SLA, маршруты и критерии «успеха» обработки.
Функциональная область — это удобная «карта продукта», по которой можно группировать сигналы. Уровень детализации выбирайте под ваши управленческие решения:
Если область определена правильно, одного взгляда на сводку достаточно, чтобы ответить: «где болит» и что делать в следующем цикле планирования.
MVP для учета фидбэка легко «раздувается», если не зафиксировать границы с самого начала. Здесь полезно ответить на два вопроса: что именно мы учитываем и для кого это делаем.
Сразу решите, это:
Практичный подход для MVP: стартовать с одного продукта и поддержать несколько команд простыми полями (например, «владелец области»), без сложной матрицы прав.
Чтобы система реально заработала в ежедневной работе, обычно достаточно пяти блоков:
Если вы хотите быстро собрать такой MVP без длинного цикла разработки и согласований, можно использовать TakProsto.AI: это платформа vibe‑coding, где прототип веб‑приложения (формы, список, карточка, роли, базовые отчеты) можно собрать через чат, а затем при необходимости экспортировать исходники и развивать проект дальше.
На MVP обычно хватает 3 ролей:
Зафиксируйте измеримые ожидания:
Ограничения по бюджету и срокам лучше перевести в definition of done. Например: MVP готов, если команда может принять 100–200 отзывов, найти нужный за минуту, отфильтровать по области и выгрузить простой отчет.
Все, что не влияет на этот сценарий (сложные интеграции, автоматическая кластеризация, продвинутые дашборды), переносите в следующие итерации.
Таксономия — это «карта продукта», на которую вы затем будете накладывать отзывы, запросы и решения. Если структура продумана, команда быстрее понимает, о чем говорит пользователь, а аналитика по функциональным областям не превращается в ручной разбор.
Практичный стартовый шаблон:
Правило простое: подфичи вводятся, когда одна «большая» фича перестает быть управляемой — у нее разные владельцы, метрики или этапы реализации.
Чтобы дерево не расползалось, задайте правила:
Категории (ваша иерархия) должны быть стабильными, потому что на них завязаны отчеты, права доступа и приоритизация.
Теги дают гибкость для временных срезов: «боль», «онбординг», «производительность», «enterprise», «mobile». Теги полезны, когда вы не уверены, что тема станет постоянной частью структуры.
Реальные отзывы часто затрагивают сразу несколько частей продукта. Поэтому отзыв лучше связывать с несколькими фичами, а не пытаться «угадать единственную правильную». Дополнительно можно отмечать основную фичу, чтобы не размывать статистику.
Таксономия будет меняться: фичи объединяются, области дробятся, названия уточняются. Чтобы история не ломалась:
Так вы сможете улучшать структуру постепенно, не теряя накопленный контекст и цифры.
Хорошая модель данных — это «скелет» системы учета фидбэка: она позволяет быстро находить похожие запросы, связывать их с конкретными фичами и объяснять, почему решение было принято именно так.
Обычно достаточно следующих объектов:
У фидбэка полезно выделить минимум, который поддержит triage и аналитику:
Важно разделять «то, что сказал пользователь» (text, вложения) и «нашу интерпретацию» (тип, приоритет, теги, привязки к фичам).
Фидбэк часто относится к нескольким фичам, а одна фича собирает десятки отзывов — это связь многие‑ко‑многим. Для этого делайте таблицу связок feedback_features (feedback_id, feature_id, confidence, created_at). Аналогично можно связать Feedback с FeatureArea, если не всегда удается определить конкретную фичу.
Историю изменений лучше хранить отдельно: feedback_status_history (feedback_id, old_status, new_status, changed_by, changed_at). Так вы сможете отвечать на вопросы «когда взяли в работу?» и «сколько времени отзыв был в ожидании?» без догадок.
На практике дублей много. Подход без сложного ML:
Сначала индексируйте то, чем пользуются фильтры каждый день:
Для поиска по тексту используйте полнотекстовый индекс (например, PostgreSQL tsvector) по text + normalized_text. Это ускорит дедупликацию и поиск по ключевым словам, а также позволит строить отчеты по темам без постоянных «тормозов» в интерфейсе.
Качество дальнейшей аналитики и приоритизации зависит от того, насколько одинаково вы принимаете входящий фидбэк. Цель этого слоя — собрать отзывы из разных источников, привести их к единому формату и сразу дать команде «чистый» материал для триажа.
Начните с каналов, которые уже есть у продукта, и добавляйте новые по мере роста:
Важно, чтобы все каналы сходились в одну очередь и создавали одну и ту же сущность «сообщение фидбэка», а не разрозненные записи.
Нормализация — это не «красота текста», а снижение шума. Минимальный набор:
Если вы храните исходник, не теряйте его: оставляйте «сырой текст» рядом с нормализованным.
Дайте системе шанс сделать первичную классификацию:
Автопривязка должна быть объяснимой: показывайте, почему выбрана область, чтобы команде было проще поправить.
Для публичных форм добавьте rate limit и CAPTCHA только при необходимости, чтобы не ухудшать конверсию.
Дубликаты ловите по «похожему тексту + той же области + близкому времени», предлагая объединение.
Вложения (скриншоты, логи) храните отдельно с лимитами по размеру и сроком жизни, а в карточке — ссылки и метаданные. Это упростит безопасность и снизит стоимость хранения.
Хороший учет фидбэка — это не только «куда сложить идеи», но и понятный маршрут для каждой записи: кто смотрит, когда отвечает, что считается решением. Воркфлоу нужен, чтобы команда одинаково трактовала входящие запросы и могла быстро отделять полезные сигналы от шума.
Практичная схема для списка/канбана: «новое → в разборе → принято → в работе → сделано/отклонено».
Важно: статус должен отвечать на один вопрос — что делать дальше, а не «насколько нам нравится идея».
Выделите отдельную очередь триажа: все новое сначала проходит через нее. Для дисциплины задайте простые правила:
Разведите публичные комментарии (видимые клиенту/автору) и внутренние заметки (для обсуждения реализации, рисков, связей с другими фичами). Поддержите:
Готовые шаблоны ответов ускоряют коммуникацию и помогают сохранять единый тон — насколько это позволяет исходный канал.
При закрытии обязательно фиксируйте причину: дубликат, не планируется, уже решено, недостаточно данных. Это улучшает аналитику и снижает повторные обращения: команда видит, какие темы «болят», а пользователи получают прозрачное объяснение.
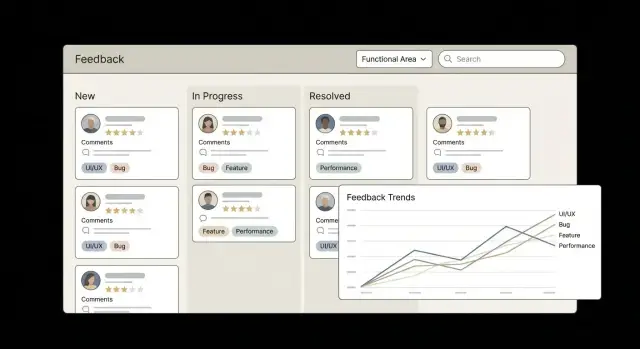
Хороший интерфейс для учета фидбэка решает две задачи одновременно: помогает быстро «поймать смысл» каждого отзыва и позволяет находить нужные группы запросов без ручной сортировки. Ниже — набор экранов и UX‑паттернов, которые обычно дают максимальный эффект.
Слева удобно держать дерево функциональных областей продукта (например, «Онбординг → Регистрация», «Отчеты → Экспорт»). Внутри области — список фич с быстрым переходом к их сводке: сколько отзывов, какая динамика за период, какие статусы преобладают.
Чтобы навигация не превращалась в «простыню», добавьте:
Карточка — это рабочее место. В ней важно показывать не только текст, но и контекст:
Отдельно полезны ссылки на связанные объекты: компания/пользователь, тикет поддержки, задача в трекере. Это экономит время на «расследование».
В списке отзывов фильтры должны быть комбинируемыми и сохраняемыми как пресеты:
Поиск — не только по тексту, но и по меткам и по пользователю/компании. В идеале — с подсказками и быстрыми операторами (например, tag:экспорт status:новый).
Когда отзывов много, выигрывают команды, которые могут обрабатывать пачками: объединить дубликаты, массово сменить статус, назначить ответственного, добавить тег. Важно показывать превью изменений и возможность отката, чтобы люди не боялись «нажать не туда».
Собранный фидбэк начинает приносить пользу, когда его можно сравнивать и объяснять: где «болит», что растет, какие темы дают максимальный эффект для продукта и бизнеса. Поэтому аналитика должна работать не только по отдельным фичам, но и по функциональным областям (например, «Онбординг», «Оплата», «Отчеты»).
На уровне функциональной области удобно держать набор простых индикаторов:
Важно заранее договориться о правилах подсчета: что считается отзывом (уникальный пользователь? уникальный кейс?), как объединяются дубликаты, как учитывается история статусов.
Голое «количество голосов» часто обманывает. Лучше использовать взвешенный скоринг, который учитывает контекст:
Практичный подход: хранить отдельные коэффициенты и итоговый балл, чтобы в отчете было видно, почему приоритет именно такой.
Сегментация помогает избежать ошибочных решений «для всех сразу». Минимальный набор срезов:
Тогда становится видно, что одна и та же фича критична, например, только для enterprise‑клиентов или для конкретной роли.
В интерфейсе полезны дашборды: топ‑фич по спросу, «горящие» проблемы (высокая серьезность + рост), время обработки (от первого сигнала до решения). Для стейкхолдеров добавьте экспорт и регулярные отчеты (CSV, при необходимости PDF) — так проще синхронизировать приоритизацию бэклога без доступа в систему.
Дополнительно стоит предусмотреть ссылку на /blog/workflow-triage для единого понимания статусов и SLA.
Интеграции — это способ сделать учет фидбэка «живым»: отзывы не лежат отдельно, а превращаются в задачи, связываются с клиентами и автоматически обновляются по мере работы команды.
Самый частый сценарий — создать задачу прямо из отзыва: выбрать проект, тип (bug/feature), заполнить заголовок и описание, приложить контекст (ссылку на карточку отзыва, функциональную область, число голосов, примеры формулировок).
Важно сразу создавать двустороннюю связь:
Так вы избежите ситуации, когда команда обсуждает задачу в одном месте, а пользователи ждут обновлений в другом.
Определите один источник правды для статусов разработки. Обычно им является трекер задач: он отражает реальное состояние работы (To Do → In Progress → Done).
В приложении для фидбэка статус может быть «пользовательским» (например, «В рассмотрении», «Запланировано», «В работе», «Доставлено»). Тогда нужно правило маппинга и понятная политика: какие изменения разрешены вручную, а какие приезжают только из интеграции.
Интеграция с CRM/службой поддержки полезна, когда важно понимать «кто просит»: компания, тариф, CSM, история обращений.
Минимум — хранить внешний идентификатор аккаунта/контакта и подтягивать базовые поля (имя компании, сегмент, MRR/тариф, ответственный). Это помогает фильтровать запросы «топ‑клиентов» и массовые боли.
Публичный API стоит строить вокруг событий и ресурсов: отзывы, фичи, функциональные области, связи с задачами. Обязательный набор вебхуков: created/updated/closed (или resolved) для отзывов и связанных сущностей.
Заранее заложите:
Почти всегда есть «наследие»: таблицы, экспорт из поддержки, метки в трекере. Дайте импорт CSV/JSON с режимом сопоставления полей и дедупликацией (по email+дате, по hash текста, по внешнему ID).
Практичная стратегия миграции — поэтапная: сначала импортировать «сырые» обращения, затем привязать их к таксономии фич, и только после этого включить автоматическое создание задач и вебхуки.
Система учета фидбэка быстро становится общим рабочим пространством: туда заходят продакты, поддержка, руководители, иногда — подрядчики. Поэтому доступ и безопасность лучше спроектировать сразу, иначе позже придется «латать» хаос с правами и утечками.
Базовый вариант — вход по email с подтверждением и восстановлением доступа. Для компаний удобнее SSO (например, через корпоративного провайдера), чтобы управлять доступом централизованно.
Отдельно задайте политику сессий: время жизни, авто‑выход при бездействии, ограничение числа активных сессий и принудительный выход при смене пароля. Это снижает риск, когда кто‑то оставил открытый аккаунт на общем компьютере.
Роли стоит сделать простыми и понятными:
Если в компании несколько продуктов или направлений, добавьте доступ по командам/пространствам: пользователь видит только «свои» функциональные области и фичи.
Минимальный набор: шифрование в передаче (TLS) и шифрование на хранении для базы и бэкапов. Ведите аудит логинов и критичных действий.
Аудит должен отвечать на вопрос «кто и что менял»: статусы, связи, поля, комментарии, настройки. Полезно дать экспорт журнала аудита (например, CSV) для внутренних проверок.
Собирайте только то, что нужно для работы: вместо полного профиля клиента часто достаточно источника и идентификатора обращения.
Поддержите маскирование (например, скрывать email/телефон для роли «только просмотр») и настраиваемые сроки хранения: автоматическое удаление или анонимизация через N дней. Это упрощает соответствие внутренним политикам и снижает риски при утечках.
Даже «простое» веб‑приложение для учета фидбэка быстро становится критичным: в нем живут решения по приоритизации, история коммуникаций и договоренности с командами. Поэтому эксплуатацию стоит продумать заранее — хотя бы на уровне базовых принципов.
Для MVP чаще всего достаточно монолита: один репозиторий, один деплой, меньше точек отказа и проще отладка. Микросервисы имеют смысл, когда появляются независимые команды, разные циклы релизов и нагрузка по отдельным доменам (например, поиск и аналитика растут быстрее остального).
По хранению данных почти всегда выигрывает SQL: связи «фича → область → голоса/комментарии → источники» естественно ложатся в реляционную модель, а миграции прозрачны. Для поиска по тексту отзывов добавьте полнотекстовый поиск (встроенный в БД или отдельный поисковый движок) и очередь задач для фоновых операций: индексация, отправка уведомлений, импорт из интеграций.
Если вы собираете систему на TakProsto.AI, типовая связка получается практичной для такого класса задач: React на фронтенде, Go на бэкенде и PostgreSQL для данных (включая полнотекстовый поиск), с возможностью выгрузить исходный код, настроить деплой, домен, а также использовать снапшоты и откат.
Контейнеризация упрощает одинаковое поведение в dev/stage/prod. Важно разделить окружения и правила доступа, а секреты (ключи API, пароли БД) хранить в менеджере секретов или переменных окружения, а не в коде.
Минимальный набор:
Алерты полезно строить не только по ошибкам, но и по задержкам: например, рост p95 времени ответа или «застрявшие» задания в очереди.
Регулярные бэкапы БД (с проверкой восстановления) важнее, чем сам факт их наличия. Зафиксируйте RPO/RTO, опишите короткий runbook: как откатить релиз, как восстановить данные, кого уведомлять.
Сфокусируйтесь на ключевых сценариях: создание/объединение запросов, смена статусов, права доступа, импорт из интеграций.
Так вы снизите риск регрессий и сможете масштабировать продукт без постоянных «пожаров».
Запуск системы учета фидбэка лучше рассматривать как короткий цикл: вы выпускаете минимально полезную версию, измеряете, где пользователи «спотыкаются», и быстро докручиваете процесс. Цель — чтобы команда реально начала жить в этом инструменте, а не держала запросы в чатах и таблицах.
В первые 2–4 недели сфокусируйтесь на том, что поддерживает ежедневную работу:
Отложите на следующий этап: сложные права доступа по проектам, витрины для клиентов, автоматическую классификацию, сложные дашборды. Это важно, но часто тормозит выпуск, не добавляя ценности в первый месяц.
Чтобы улучшать продукт осмысленно, заложите минимум телеметрии и опросов:
Важно сразу договориться, какие данные вы не собираете (например, содержимое приватных комментариев), и описать это в /privacy.
Когда MVP стабильно используется, добавляйте функции, которые экономят время:
Сделайте короткий командный пакет: глоссарий функциональных областей/фич, правила триажа (когда объединяем, когда отклоняем, как фиксируем «ожидаемую ценность»), примеры хороших формулировок запросов.
Раз в спринт или раз в месяц проводите обзор: какие области «горят», что попало в план, что отклонено и почему. Итоги превращайте в понятную коммуникацию изменений: заметки релиза, обновления статусов на портале идей и ссылки на решения в /changelog. Это замыкает цикл «фидбэк → решение → объяснение», и доверие к процессу растет.
Начинайте с того, какие решения должна поддерживать система:
Если на выходе нет действий (задача в бэклоге, статус, ответ пользователю, план исследования), значит вы ведете «ящик пожеланий», а не инструмент управления.
Минимум — четыре типа с разными ожиданиями обработки:
Сразу заведите поле type и разные шаблоны действий по каждому типу (эскалация, ответ, создание задачи).
Это «карта продукта», по которой вы группируете сигналы так, чтобы одним взглядом понимать, где болит.
Уровни детализации можно комбинировать:
Чтобы MVP не «раздулся», зафиксируйте границы:
Практичный старт: один продукт + несколько команд через простое поле вроде «владелец области», без сложной матрицы прав и пространств.
Обычно достаточно пяти блоков:
новый → в разборе → принято/в работе → закрыто (с причиной).Если это закрывает сценарий «принять 100–200 отзывов и найти нужный за минуту», MVP уже полезен.
Для MVP обычно хватает 3 ролей:
Дальше усложняйте только если появились реальные конфликты доступа (несколько продуктов, подрядчики, регуляторные ограничения).
Сделайте иерархию и правила владения:
А для временных тем используйте теги, а не бесконечное дробление дерева.
Базовый набор сущностей:
Feedback, FeatureArea, Feature, Source, User/Account, Comment, Attachment.Без сложных моделей можно сильно улучшить качество:
fingerprint);canonical_feedback_id или сущность Topic.Важно: дубликаты лучше не удалять, а объединять — чтобы сохранялась история источников и сегментов.
Определите единый маршрут:
дубликат, не планируется, уже решено, .Правило: выбирайте детализацию под решения, которые вы реально принимаете каждую неделю/месяц.
Ключевые связи:
feedback_features.feedback_status_history).Так вы сможете отвечать на вопросы «когда взяли в работу?» и «почему закрыли?» без потери контекста.
недостаточно данныхДля единообразия статусов и SLA удобно зафиксировать правила в документации (например, на странице /blog/workflow-triage) и использовать шаблоны ответов.