Пошаговый план создания веб‑приложения для коммуникаций при сбоях: роли, шаблоны, статусы инцидента, каналы уведомлений, интеграции и безопасность.
Веб‑приложение для коммуникаций при сбоях решает одну ключевую задачу: сделать сообщения об инцидентах предсказуемыми и управляемыми. Когда система «падает» или работает нестабильно, проблема часто не только в технике, но и в хаосе коммуникаций: разные команды пишут разное, обновления запаздывают, а клиенты не понимают, что происходит и чего ждать.
Главный эффект — «единый источник правды». Все обновления статуса, формулировки, таймлайн и ожидаемые сроки фиксируются в одном месте и распространяются по нужным каналам.
Не менее важны скорость и согласованность: шаблоны и заранее настроенные потоки позволяют выпустить первое сообщение за минуты, а не за час. История изменений и авторство помогают объяснить, почему было сказано именно так — это критично для доверия и последующих разборов.
Минимальный набор: деградация (медленно/частично), частичный простой (не работает часть функций), полный простой, а также плановые работы.
Для каждого сценария важно заранее определить:
Обычно это:
Если эти артефакты формируются из одной «карточки инцидента», риск расхождений резко снижается.
Чтобы коммуникации при сбоях были быстрыми и безопасными, в приложении важно заранее разделить роли и аудитории. Тогда команда не спорит «кто публикует», а клиент получает ровно ту информацию, которая ему нужна.
Обычно достаточно пяти ролей:
Сегментация нужна, чтобы один инцидент мог иметь разные сообщения для разных групп:
Минимальная матрица выглядит так: автор создает и редактирует черновики, апрувер публикует и при необходимости откатывает публикации, администратор может всё, наблюдатель и читатель — только просмотр.
Отдельно стоит включить право «публикация без согласования» — и выдавать его крайне ограниченно (например, только дежурному Incident Commander и только для внутренних каналов).
Журнал действий — обязательная часть: система должна хранить, кто и когда создал инцидент, поменял статус, отредактировал текст, изменил аудиторию, отправил уведомления, сделал откат.
Для доверия и разборов после инцидента полезно фиксировать также «до/после» текста и причину изменения (короткий комментарий).
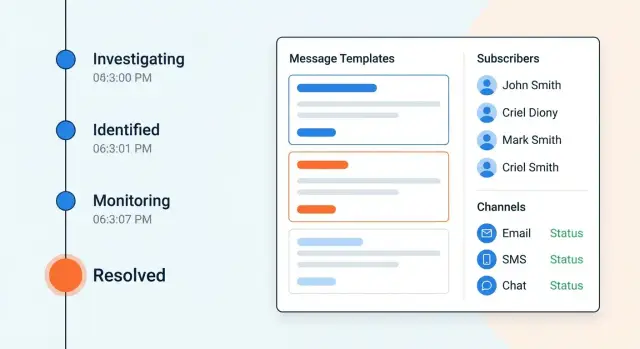
Хорошая коммуникация при сбоях начинается с одинакового понимания: что считается инцидентом, какие данные обязательны, и как меняются статусы. Если модель размыта, сообщения становятся противоречивыми, а пользователи теряют доверие.
Удобный жизненный цикл — это не «красивые слова», а подсказка команде, что писать и каких ожиданий придерживаться. Практичный пример цепочки:
Исследуем → Причина найдена → Исправляем → Наблюдаем → Решено
Заранее задайте правила: например, обновлять статус каждые N минут, даже если новостей нет (в таком случае — «работы продолжаются, следующий апдейт в …»).
В приложении стоит сделать таймеры и автонапоминания автору/дежурному: уведомление за 2–3 минуты до дедлайна и эскалацию, если обновление пропущено.
Минимальный набор: заголовок, влияние (кого и как затронуло), затронутые сервисы/компоненты, время начала, ETA, ссылки (на дашборды, тикеты, постмортем, чат‑обсуждение).
Эти поля помогают писать ясные обновления, упрощают аудит и снижают вероятность «потерять контекст» при смене дежурного.
Система должна поддерживать несколько инцидентов одновременно и связи «родитель–дочерний» между компонентами. Так вы сможете показать пользователям, что проблема в одном сервисе вызывает деградацию другого, не плодя дубликаты и не путая статусы.
Чтобы приложение действительно помогало при сбоях, ключевые действия должны выполняться быстро, последовательно и без потери контекста. Ниже — основные потоки, которые стоит заложить в UX с самого начала.
Самый частый сценарий — дежурный видит проблему и должен запустить коммуникации, не собирая текст по кусочкам.
Практичный поток:
Важно: сразу показывайте предпросмотр для публичной страницы статуса и для уведомлений, чтобы автор понимал, как сообщение увидят клиенты.
Коммуникации почти всегда требуют контроля, особенно для крупных клиентов и при жестких SLA.
Поток должен поддерживать:
Полезно добавить «план обновлений» (например, каждые 30 минут), чтобы команда не забывала про коммуникации.
Параллельно с внешними сообщениями идет внутренняя работа. Нужна единая лента: статусы, отправленные уведомления, решения, ссылки на тикеты, заметки.
Отдельно: внутренние комментарии (не попадают клиентам) и отметки «внешнее сообщение готово/ожидает согласования». Это снижает риск, что две команды опубликуют разное.
После закрытия инцидент не должен «пропадать». Поток постмортема включает:
Так вы превращаете инциденты в накопление опыта, а не в разрозненные сообщения.
Хорошая структура данных делает коммуникации при сбоях предсказуемыми: можно быстро собрать статус по сервисам, найти нужные обновления, доказать, кто и что менял, и при этом не утонуть в ручной работе.
Если вы проектируете систему «с нуля», полезно сразу думать о будущем: мульти‑проектности, интеграциях и экспортируемости. Например, в TakProsto.AI такие продукты часто собирают как полноценное React‑приложение с backend на Go и PostgreSQL, а потом при необходимости экспортируют исходники и разворачивают в своей инфраструктуре — это удобно, когда статус‑сервис должен жить независимо от основного продукта.
Incident — карточка инцидента: заголовок, описание, текущий статус (investigating/identified/monitoring/resolved), время начала/окончания, уровень влияния, владелец, теги, клиентский сегмент (если коммуникации отличаются).
Component — сервис/часть системы, на которую подписываются и по которой фильтруют: название, критичность, порядок отображения, статус компонента.
Update — обновление по времени (таймлайн): текст сообщения, публичность (публичное/только для внутренних), временная метка, автор, «снимок» статуса на момент публикации.
Subscriber — подписчик: идентификатор (email/телефон/вебхук), подтверждение (double opt-in), признак активен/отписан, принадлежность к сегменту.
Channel — канал доставки: email, SMS, webhook, push и т. п., плюс технические параметры (провайдер, лимиты, настройки ретраев).
Template — шаблон: язык, тип сообщения (первичное/обновление/закрытие), переменные, версия.
Approval — согласование: кто должен утвердить, статус (pending/approved/rejected), комментарий, время.
Связь Incident ↔ Component обычно many-to-many через таблицу incident_components (в одном инциденте может пострадать несколько компонентов, и компонент участвует в разных инцидентах).
Incident ↔ Update — one-to-many: обновления сортируются по времени, при этом полезно хранить номер версии и ссылку на предыдущую редакцию.
Для аудита — отдельная таблица AuditLog (или история версий): сущность, действие (create/update/delete/publish), кто, когда, что изменилось (diff). Это сильно помогает при разборе инцидентов и для внутреннего контроля.
Подписки лучше хранить как связь Subscriber ↔ Component с настройками: какие каналы разрешены, «тихие часы», язык, частота (например, только major‑инциденты). Технически это удобно разнести на subscriptions и subscriber_channel_preferences.
Для операционной работы критичны индексы и фильтры:
incident_components);Если планируются сложные запросы по тексту обновлений, добавьте полнотекстовый поиск для Incident.title и Update.body. Это ускорит поддержку и снизит риск пропустить похожий повторяющийся сбой.
Шаблоны — это способ быстро выпускать понятные обновления и не «утонуть» в согласованиях во время инцидента. Хороший редактор помогает не столько красиво писать, сколько удерживать единый стандарт: коротко, по делу, без лишних деталей и с предсказуемым ритмом обновлений.
Минимальный набор стоит покрыть четырьмя стадиями:
Чтобы шаблоны были универсальными, добавьте переменные:
{service} — какой сервис затронут{impact} — как это влияет на пользователей{eta} — ожидаемое время восстановления (если известно){next_update_time} — когда будет следующее сообщениеПример (стадия «Исследуем»):
Замечаем проблемы в {service}. Влияние: {impact}. Команда уже разбирается. Следующее обновление — {next_update_time}.
Полезные функции редактора:
{next_update_time} по вашему регламенту обновлений.Пишите:
Не пишите:
Хорошо:
В {service} возможны задержки. Мы уже работаем над восстановлением. Следующее обновление — {next_update_time}.
Плохо:
Падает кластер X из‑за проблемы с Y, возможно, поможет перезапуск, ETA неясно.
Так шаблоны и редактор вместе дают главное: единый тон, меньше ошибок и стабильные обновления, которые понятны пользователям и поддерживают доверие.
Выбор каналов уведомлений определяет, насколько быстро и надежно клиенты узнают о сбое. Хорошая практика — поддерживать несколько способов доставки и давать пользователю возможность выбрать удобные.
Чаще всего начинают с email: он дешевый, привычный и хорошо подходит для подробных обновлений и пост‑мортемов. Для срочных алертов добавляют SMS — коротко, быстро, но дороже и с ограничениями по длине.
Дальше идут веб‑хуки (для B2B‑клиентов и интеграций) и чат‑уведомления (например, в корпоративные мессенджеры): они удобны для команд, которые реагируют в своих рабочих инструментах. RSS можно оставить как опциональный канал для тех, кто предпочитает подписки без регистрации — его обычно подключают позже.
Нужны три механики:
Планирование отправки (например, «сегодня в 10:00 по Москве») — полезно для заранее известных работ.
Повторные рассылки — когда инцидент развивается, важно отправлять обновления тем же подписчикам, но без спама.
Дедупликация — защита от повторов при ретраях и сбоях провайдера: одно событие = одно уведомление на адрес/номер/endpoint. Для этого обычно используют idempotency‑ключи и журнал отправок.
У каждого канала должны быть понятные настройки: частота (только критичные / все обновления), выбор компонентов, язык, часовой пояс.
Для email обязательна отписка в один клик и хранение истории согласий. Для SMS — понятная инструкция «STOP/СТОП» (или требования вашего провайдера), плюс подтверждение подписки при необходимости.
Сделайте витрину статусов отправки: «в очереди», «отправлено», «доставлено», «ошибка», «отписан». Ошибки важно классифицировать (временные/постоянные) и настроить повторные попытки с увеличивающейся задержкой и финальным «dead letter» для разбора.
Полезно связать уведомления со страницей статуса (например, /status), чтобы в каждом сообщении был единый источник правды и актуальные обновления.
Страница статуса — это «единое окно», куда пользователи идут за правдой, когда что-то не работает. Важно разделить её на публичную часть (для клиентов и внешних пользователей) и приватную (для сотрудников, поддержки и менеджеров), чтобы одновременно сохранять прозрачность и не раскрывать лишнее.
Публичная часть должна быть максимально простой и понятной с первого экрана:
Даже в MVP полезно предусмотреть базовый брендинг: логотип, цвета, короткое описание сервиса.
Если продукт это поддерживает — настройку кастомного домена/поддомена и понятный заголовок в браузере. Это снижает вероятность, что пользователи воспримут страницу как «чужую».
Страница статуса должна открываться быстро даже при высоком трафике. Помогают простая верстка, минимальный JavaScript, кэширование.
Дополнительно можно предусмотреть офлайн‑кэш (например, показ последней успешной версии страницы), чтобы пользователь видел хотя бы последний известный статус.
Делайте человекопонятные URL (например, /incidents/2025-12-incident-123) и не прячьте архив. Это улучшает поиск по прошлым сбоям и снижает нагрузку на поддержку: вместо «что происходит?» пользователи получают ссылку на конкретное обновление.
Приватная зона дополняет публичную: внутренние заметки, черновики, таймлайн действий, ссылки на мониторинг и постмортем, а также быстрые кнопки для публикации следующего апдейта.
Главное правило: всё, что может навредить безопасности или репутации, остаётся внутри, а наружу выходит проверенная, понятная информация.
При инциденте цена ошибки в тексте почти такая же, как цена ошибки в техработах: неверный статус, лишние детали или обещания без сроков быстро подрывают доверие. Поэтому в веб‑приложении для коммуникаций при сбоях стоит заложить строгий, но быстрый процесс согласования и контроля качества.
Хорошая схема — настраиваемая цепочка подтверждений по типу инцидента и аудитории. Например:
Важно, чтобы порядок был явным (кто следующий), а публикация в публичные каналы была возможна только после нужных отметок. Для внутренних каналов можно разрешить «быстрый апдейт» с последующим согласованием.
Сообщения должны жить как документы:
Отдельно храните «опубликованную версию» и «рабочий черновик», чтобы правки не меняли уже отправленный клиентам текст.
Перед отправкой показывайте короткий чек‑лист, который можно адаптировать под вашу политику:
Если время следующего обновления прошло, система должна автоматически:
Такой контроль снижает риск молчания в момент, когда пользователям особенно важна прозрачность.
Интеграции превращают статус‑приложение из «ручного редактора сообщений» в рабочий инструмент поддержки: инциденты появляются вовремя, статусы обновляются без лишнего копирования, а клиенты получают одинаковые формулировки во всех каналах.
Самая полезная автоматизация — создавать черновик инцидента при критическом алерте. Важно не «публиковать за человека», а:
Чтобы не получить десятки дублей, добавьте дедупликацию: один инцидент на ключ (сервис + тип алерта) в заданном окне времени, и объединение повторных срабатываний в ленту событий.
Если у вас есть CMDB или каталог сервисов, импортируйте оттуда компоненты, их владельцев и зависимости. Тогда оператор выбирает не «абстрактный продукт», а конкретный элемент (API, биллинг, очередь), а приложение может автоматически подсказать потенциально затронутые части.
Это экономит минуты в начале сбоя и снижает риск забыть важный компонент.
Интеграция с тикет‑системой нужна для двух вещей: прозрачности и дисциплины. Практичный минимум:
Публичная страница статуса — не единственный потребитель. Дайте партнерам веб‑хук на события: incident.created, status.changed, message.published, incident.resolved.
Веб‑хук должен быть надежным: подпись запроса, ретраи с экспоненциальной паузой, идемпотентность (чтобы повторная доставка не ломала интеграцию) и журнал доставок для поддержки.
Хороший принцип: автоматизация ускоряет подготовку и доставку, но финальное публичное сообщение всегда остается под контролем ответственного человека.
Коммуникации при сбоях — чувствительная зона: одно неверное действие (например, случайная публикация черновика) может создать больше проблем, чем сам инцидент. Поэтому безопасность и надежность здесь — не «добавка», а часть продукта.
Начните с понятной схемы входа и строгих ролей. Для корпоративных клиентов чаще всего ожидаемы SSO/SAML или OAuth, а для администраторов и редакторов — обязательная MFA.
Важно разделять доступ не только по ролям, но и по контексту: команды, проекты, окружения (prod/stage), отдельные статус‑страницы. Это снижает риск, что человек из одной команды опубликует обновление не в тот канал или не тому сегменту пользователей.
Технические ограничения должны поддерживать процесс:
Логи аудита — это ответы на вопросы «кто/что/когда изменил» для статусов, шаблонов, списка получателей и настроек каналов. Продумайте хранение, поиск и разграничение доступа к этим логам, а также настраиваемую политику ретенции (сроки и правила зависят от требований компании и регуляторов).
Уведомления должны отправляться предсказуемо даже при пиковых нагрузках:
Если вы планируете интеграции с мониторингом, ограничивайте права токенов, валидируйте входящие события и фиксируйте все автоматические действия в аудите — так автоматизация не станет «черным ящиком».
Запуск такого продукта проще всего делать через MVP: минимальный набор функций, который уже снижает хаос во время сбоя и дисциплинирует коммуникации. Важно не пытаться «закрыть всё» — лучше быстрее выйти в эксплуатацию, собрать реальные сценарии и итеративно улучшать.
На первом релизе достаточно трёх вещей:
И добавьте простую status page: публичная страница с текущим состоянием и списком активных/недавних инцидентов. Даже без сложного дизайна она сразу отвечает на главный вопрос клиента: «у вас всё сломалось или только у меня?»
Если задача — запустить MVP быстро, такой класс приложений удобно собирать на платформах vibe‑coding: например, в TakProsto.AI можно описать роли, статусы, шаблоны и каналы в виде требований в чате, получить рабочее веб‑приложение, а затем донастроить интеграции, деплой и кастомный домен. Для российских команд часто важно, что платформа разворачивается на серверах в России и не отправляет данные за рубеж.
Чтобы понять, работает ли MVP, измеряйте не «количество функций», а качество коммуникаций:
Прогоните сценарии «как в жизни»: быстрый инцидент на 10 минут, затяжной на несколько часов, серия обновлений, отмена ложной тревоги.
Отдельно проверьте:
Дальше развивайте продукт по мере появления запросов:
Для коммерческой части и следующих шагов удобно завести отдельные материалы на /pricing и в /blog — так пользователи будут понимать и цену, и дорожную карту без лишних писем.
Лучший способ понять возможности ТакПросто — попробовать самому.