План разработки веб‑приложения: метрики внедрения, сбор событий, расчёт adoption health score, дашборды, сегменты, алерты, доступы и качество данных.
Adoption Health Score — это сводный показатель того, насколько активно и «правильно» клиент использует ваш продукт и движется ли он к обещанной ценности. Проще: это оценка внедрения, которая превращает разрозненные сигналы (логины, ключевые действия, подключённые интеграции, прогресс онбординга) в одну понятную шкалу — например, от 0 до 100.
Главная польза score — он помогает действовать заранее, а не постфактум.
B2B SaaS: внедрение часто зависит от нескольких ролей (админ, менеджер, исполнитель). Score подсказывает, подключились ли нужные пользователи и выполняются ли ключевые сценарии.
Сервисы с подпиской: важно отследить регулярность полезных действий между платежами — это снижает churn risk.
Enterprise: внедрение идёт волнами по департаментам. Score помогает видеть прогресс по подразделениям и не терять инициативу после пилота.
NPS и опросы измеряют восприятие и ожидания, но часто запаздывают и зависят от настроения. Финансовые метрики (выручка, просрочки, расширения) отражают коммерческий итог, но не объясняют, что происходит в продукте.
Adoption Health Score — про поведение и использование: он показывает механические причины риска или роста и даёт конкретные точки приложения усилий.
Прежде чем считать adoption health score, важно договориться, какие решения будет поддерживать веб‑приложение. Это не «витрина метрик», а рабочий инструмент для Customer Success и смежных команд: он должен быстро отвечать на вопросы «где риск?» и «что делать дальше?».
Обычно в систему заходят несколько групп, и каждой нужна своя подача данных:
Отсюда следуют ключевые сценарии: карточка одного клиента, портфель с фильтрами, динамика по времени и разрезы по сегментам.
На практике полезно заранее зафиксировать 8–10 вопросов, например: «какие клиенты просели за неделю?», «какие модули не активированы?», «кто не завершил онбординг?», «где рост активности без роста ключевого результата?».
Определите, насколько данные должны быть свежими: почти real‑time оправдан, если команда реагирует в течение часов (например, в онбординге). Для большинства B2B‑кейсов достаточно ежедневного обновления, что упрощает интеграции и снижает стоимость.
Успех лучше измерять не «точностью формулы», а влиянием на процессы: сокращение времени реакции на риск, рост доли клиентов, дошедших до «первой ценности», снижение churn risk в целевом сегменте.
Сразу зафиксируйте ограничения по срокам, бюджету и доступным ресурсам (аналитик, backend, интеграции), а также минимальный набор функций для MVP, чтобы не пытаться «сделать всё» в первой версии.
Чтобы health score был стабильным и сравнимым, начните с простой и однозначной модели данных. Частая ошибка — считать метрики то «по пользователям», то «по компаниям», а затем пытаться склеить это задним числом.
Заранее выберите основную единицу, по которой вы будете строить скоринг и отчёты: аккаунт/организация (customer), рабочее пространство/проект (workspace), лицензия/подписка (subscription) или пользователь (user). Обычно score считают по организации, а детализацию делают по workspace и user.
На старте достаточно пяти сущностей:
Заложите стабильные ключи и их иерархию:
customer_id — главный идентификатор для агрегаций.user_id — уникален в рамках системы; храните также customer_id.workspace_id — привязан к customer_id (и иногда к subscription_id).plan_id — ссылка на тариф из справочника.Важно: события должны содержать как минимум customer_id и timestamp, иначе их сложно использовать в скоринге.
Оптимальный формат события: event_name, timestamp, properties (JSON), source (web/app/api). В properties держите контекст: модуль, функция, объект (например, document_id), результат (успех/ошибка), количество (например, items_count).
Отдельно заведите справочники тарифов, модулей/фич, команд/сегментов. Тогда в отчётах будет легко ответить: «score упал у клиентов на тарифе X» или «рост adoption связан с модулем Y».
Хороший adoption health score начинается не с формулы, а с правильных метрик. Ошибка многих команд — измерять «всё подряд» и потом удивляться, что оценка здоровья клиента не объясняет churn risk и не помогает Customer Success.
Активность — базовый слой мониторинга внедрения, но сама по себе не равна ценности.
Важно заранее определить 3–7 «ключевых действий», которые действительно отражают внедрение, а не просто навигацию.
Ценность отвечает на вопрос: клиент получил обещанный результат?
Примеры: первая успешно завершённая задача, запуск первого проекта, настройка интеграции, достижение определённого объёма данных. Такие события обычно лучше предсказывают удержание, чем голые DAU.
Даже высокая активность может сопровождаться плохим опытом.
Сюда входят: ошибки и падения, деградация скорости выполнения задач, «залипание» в шагах онбординга, рост обращений в поддержку по одним и тем же темам. Эти сигналы полезны для ранних алертов по рискам.
Для B2B особенно важны признаки совместной работы: приглашения коллег, рост числа активных пользователей, совместное редактирование/комментарии, расширение на новые отделы.
Продления, апгрейды и просрочки платежей полезны, но не должны «перекрывать» продуктовые метрики. Иначе оценка здоровья клиента превращается в финансовый индикатор и перестаёт объяснять причины.
Практическое правило: выбирайте метрики, которые (1) понятны бизнесу, (2) связаны с успешным онбордингом пользователей, (3) можно улучшить конкретными действиями команды.
Хороший adoption health score — это понятная для команды «температура» внедрения: из каких сигналов она состоит, как считается и что делать при изменении. Начните с простой, объяснимой формулы и оставьте место для усложнения позже.
Самый практичный старт — взвешенная сумма: каждому сигналу задаётся вес, затем всё приводится к шкале 0–100.
Поверх чисел удобно наложить уровни: зелёный/жёлтый/красный. Например: 80–100 — зелёный, 50–79 — жёлтый, ниже 50 — красный.
ML‑модели лучше подключать позже — когда накопятся данные и появится стабильная «истина» (например, факты оттока и успешного продления), иначе модель будет воспроизводить шум.
Чтобы score был честным, метрики нормализуют:
Считайте показатели в окнах 7/30/90 дней и сравнивайте периоды: не только «сколько было», но и «как меняется». Падение активности за последние 7 дней при норме в 30 — ранний сигнал риска.
Разделите score на блоки: Активность + Достижение ценности + Риски.
Health = 0.45*Activity + 0.40*Value + 0.15*(100 - Risk)
Где Activity — доля активных пользователей и частота ключевых действий, Value — выполнение «моментов ценности» (например, настроили интеграцию, создали первый отчёт), Risk — просрочки, частые ошибки, снижение использования.
Храните рядом с числом «расшифровку»: вклад каждого блока и топ‑3 факторов изменения за период. Это помогает команде доверять score и объяснять его клиентам без споров про «магическую цифру».
Чтобы health score отражал реальное внедрение, важнее всего правильно организовать сбор данных. На этом этапе вы решаете, какие источники подключать, как стандартизировать события и как доставлять их в хранилище без потерь.
Обычно сигнал о внедрении складывается из нескольких потоков:
Даже если вы стартуете с MVP, заложите возможность подключать источники постепенно — без переписывания модели событий.
Для продуктовой аналитики чаще всего комбинируют:
Типовая схема: на фронтенде генерируется anonymous_id, после логина он «склеивается» с user_id. Дальше каждый пользователь маппится на customer_id (аккаунт/организацию). Важно хранить историю маппинга (например, если пользователь переехал между аккаунтами) и явно отмечать источник истины (CRM или продукт).
Практичная цепочка выглядит так: трекинг → очередь/ETL → хранилище → витрины. Очередь (или буфер) сглаживает пики, ETL нормализует схему и обогащает события данными из CRM/биллинга, а витрины готовят агрегаты для скоринга и дашбордов.
Зафиксируйте простые стандарты:
invited_user, created_project),event_name, timestamp, user_id/anonymous_id, customer_id, source,event_version) и правила обратной совместимости,Эти договорённости экономят недели, когда вы начинаете объяснять клиенту, почему score изменился.
Чтобы health score был полезным, его нужно не только «посчитать один раз», но и стабильно пересчитывать, хранить историю и быстро отдавать в интерфейс. Для этого важно выбрать место, где живут события и агрегаты, и где выполняются расчёты.
Для MVP чаще всего хватает PostgreSQL: он понятный, недорогой в эксплуатации и хорошо подходит для ежедневных агрегатов. Сырые события можно хранить в отдельной таблице (или даже в упрощённом виде), а основную нагрузку перенести на предрассчитанные срезы.
Когда объём растёт (миллионы событий в день, много клиентов, сложные отчёты), логично добавить DWH (опционально): ClickHouse/BigQuery/Snowflake и т.п. В таком варианте PostgreSQL остаётся «витриной» для приложения (dashboard‑serving), а тяжёлые джойны и пересчёты уходят в хранилище.
Практичный подход — считать ежедневные срезы:
Эти агрегаты позволяют строить тренды и объяснять итоговый score без обращения к сырому логу.
Обычно score пересчитывают по расписанию (например, раз в сутки) и дополняют инкрементом в течение дня для свежести. Инкрементальный режим — это пересчёт только тех клиентов/пользователей, у кого появились новые события, а не всего массива.
История score по дням нужна, чтобы видеть динамику (улучшение/ухудшение) и корректно ловить деградации после релизов или изменений в онбординге.
Для производительности используйте индексы по customer_id и дате, партиционирование таблиц по времени (когда объёмы выросли) и кэширование «горячих» запросов для дашбордов. Это обеспечивает быстрый отклик интерфейса даже при регулярных пересчётах.
Backend для health score — это «единый источник правды»: он отдаёт актуальные метрики, события и рассчитанный score, а также гарантирует, что каждый видит только свой портфель клиентов.
Если вы хотите быстро собрать рабочий прототип без классического цикла «дизайн → программирование → релиз», удобно использовать vibe‑coding подход. Например, в TakProsto.AI можно описать требования к сущностям (customers/users/events), витринам и эндпоинтам, а затем итеративно доработать API и интерфейс через чат — с экспортом исходников и возможностью отката по снапшотам.
Практичный минимальный набор API обычно выглядит так:
GET /api/clients — список клиентов (с краткими полями: сегмент, владелец, текущий score, риск).GET /api/clients/{clientId} — профиль клиента: атрибуты, тариф, ответственный менеджер.GET /api/clients/{clientId}/metrics — агрегаты (WAU/MAU, активации ключевых фич, глубина использования).GET /api/clients/{clientId}/events — лента событий (с пагинацией и диапазоном дат).GET /api/clients/{clientId}/score — текущий score + вклад факторов (что сильнее всего тянет вверх/вниз).POST /api/score-config — настройки формулы, порогов и весов (только для админов).Чтобы дашборд реально помогал работать, в GET /api/clients добавляют фильтры: по риску (красный/жёлтый/зелёный), сегменту, менеджеру, динамике score за период, а также сортировки по падению/росту score.
Заранее задайте роли: админ (настройки формулы и порогов), CS‑менеджер (видит и комментирует свой портфель), просмотр (только чтение).
Отдельно важен аудит: кто и когда смотрел карточку клиента, кто менял веса/пороги и какие значения были «до/после». Это упрощает разбор спорных случаев и повышает доверие к score.
Для ручной работы полезен экспорт CSV и, при необходимости, выгрузка в таблицы.
Для автоматизаций добавьте webhooks: например, событие score_dropped при падении ниже порога, чтобы запускать задачи и уведомления в других системах.
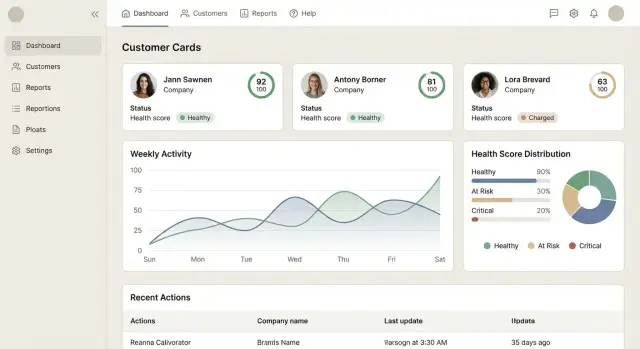
Интерфейс — это «операционная панель» Customer Success: он должен быстро показывать, где риск, где рост, и что делать дальше. Хорошая визуализация важнее количества графиков: лучше меньше, но так, чтобы по каждому экрану было понятно следующее действие.
Главная страница работает как список приоритетов на день. Вверху — поиск по компании и тегам, ниже — таблица/карточки клиентов с ключевыми полями: текущий adoption health score, изменение за период (например, 7/30 дней), сегмент, ответственный менеджер и ближайший риск/алерт.
Фильтры должны быть практичными: «score упал за неделю», «нет активности N дней», «высокий потенциал, но низкое внедрение», «в онбординге». Сортировка по «что горит» помогает команде не спорить о важности — приоритет уже посчитан и виден.
В карточке клиента на первом экране — крупно текущий score и тренд. Рядом — объяснение, почему он такой: 3–5 факторов, которые внесли наибольший вклад в рост/падение.
Полезный паттерн: блок «Что сделать сейчас» — короткий список рекомендаций, связанных с факторами (например: «пригласить ещё 3 пользователей», «завершить настройку X», «запланировать обучение»). Кнопки действий ведут в задачи/письма/заметки внутри продукта.
Покажите метрики, из которых складывается score, в понятном виде: текущее значение, норма/цель, вес в скоринге и динамика. Важно объяснять человеческим языком: «активные пользователи ниже цели», а не «DAU/WAU 0.12».
Таймлайн связывает цифры с реальностью: ключевые события продукта, релизы, этапы онбординга, обращения в поддержку, встречи, изменения тарифа. Когда score падает, таймлайн помогает за минуту проверить гипотезы.
Каждый виджет должен отвечать на два вопроса: «Что это значит?» и «Что я могу сделать дальше?». Если виджет не ведёт к решению (фильтру, списку клиентов, задаче, сценарию коммуникации), его лучше убрать или спрятать глубже, например на /customers/{id}/drivers.
Health score сам по себе — это просто число. Польза появляется, когда вы превращаете его в сегменты, причины и конкретные следующие шаги для Customer Success, продаж и онбординга.
Практичный набор сегментов, который легко объяснить бизнесу:
Важно: сегмент — это не только диапазон score, но и контекст (тариф, размер клиента, этап жизненного цикла). Иначе вы будете одинаково «тушить пожары» у всех.
Начните с простых правил и постепенно усложняйте:
Алерты должны попадать туда, где команда реально работает: email, Slack/Teams (если нужно), задача в CRM с владельцем и дедлайном. Хорошая практика — один алерт = один ответственный.
Для «красного» — быстрый контакт, диагностика причины (какое событие исчезло), согласование плана восстановления. Для «жёлтого» — профилактика: подсказки в продукте, письмо с конкретным следующим шагом, короткая сессия по настройке.
Храните журнал срабатываний: правило, причина, данные, кому отправили, статус (в работе/закрыто), повторные срабатывания. Это помогает избегать спама (дедупликация, cooldown) и объяснять, почему система решила, что клиент в риске.
Health score полезен ровно настолько, насколько ему можно доверять. Поэтому качество данных и понятное объяснение «почему получилось так» — не опциональные улучшения, а часть продукта.
Начните с простых автоматических проверок и сделайте их видимыми в интерфейсе (например, в карточке клиента):
Оценка здоровья — это модель. Она упрощает реальность и зависит от выбранных метрик, весов и периода. В UI полезно показывать вклад факторов: какие метрики подняли score, а какие снизили (в стиле «разбор полётов»), чтобы CS мог быстро проверить гипотезу.
Проверьте, не «наказывает» ли формула:
Нормализация по размеру, сегментация и разные пороги для разных типов аккаунтов часто дают более честную картину.
Заложите цикл обратной связи от Customer Success: пометка «ложный риск/ложный успех», комментарий причины, предложение корректировок весов и порогов.
И обязательно поддерживайте словарь метрик и правила расчёта: определения, окна времени, источники событий, исключения. Это можно оформить как внутреннюю страницу /docs/metrics, чтобы новые участники команды трактовали score одинаково.
Health score почти всегда опирается на пользовательские события, а значит затрагивает данные, которые могут считаться персональными или коммерчески чувствительными. Если продумать безопасность позже, придётся переделывать трекинг, модель данных и доступы.
Собирайте только то, что прямо нужно для метрик внедрения: факт события, время, контекст (например, тип функции), привязку к аккаунту и роли. Избегайте лишних атрибутов вроде «полного текста», содержимого документов, необязательных IP/геоданных. Чем меньше полей, тем ниже риски утечек и проще соблюдать сроки хранения.
Если для расчёта score не требуется знать реальное имя пользователя, храните внешние идентификаторы в псевдонимизированном виде: например, user_id как случайный UUID, а email — отдельно или не хранить вовсе. Для связки с внешними системами можно использовать хэш (с солью) или таблицу соответствий, доступную ограниченному числу сервисов.
Вводите принцип наименьших привилегий: Customer Success видит агрегаты и список клиентов, аналитика — обезличенные события, админ — управление справочниками и правами. Разделяйте dev/stage/prod и не копируйте прод‑данные в тестовые среды без обезличивания.
Храните ключи и токены в менеджере секретов, регулярно ротируйте. Включите журналирование доступа: кто и когда смотрел выгрузки, менял правила алертов, экспортировал данные.
Заранее определите основания обработки (согласия/договор), сроки хранения, правила удаления и экспорт по запросу. Важно: лучше формулировать требования вместе с юристами и ИБ, не обещая «полное соответствие» конкретным нормам без официальной проверки.
MVP для Adoption Health Score — это не «урезанная версия мечты», а проверка, что score действительно помогает принимать решения. Важно начать с минимального набора сигналов и понятного действия по результату.
Выберите один ключевой сценарий, где стоимость ошибки невысока, а польза видна быстро:
Ограничьте набор метрик (3–7 штук): активные пользователи, ключевое событие (например, создание проекта), частота использования, доля приглашённых пользователей. Сделайте понятные пороги и расшифровку: что именно «просело».
Если задача — быстро собрать такое MVP как отдельное веб‑приложение (портфель → карточка клиента → алерты), TakProsto.AI подходит как практичный вариант: можно описать бизнес‑логику скоринга и экраны в planning mode, а затем получить React‑интерфейс, Go‑backend и PostgreSQL‑схему с возможностью деплоя, хостинга и экспорта исходников.
Запустите пилот на части клиентов или на одной Customer Success‑команде. Зафиксируйте процесс: кто смотрит score, как часто, какие действия предпринимаются, где фиксируется результат. Первые 2–4 недели собирайте обратную связь на уровне «сигнал → действие → итог».
Оценивайте MVP не по красоте дашборда, а по эффекту:
Дальше улучшайте постепенно: A/B‑тестируйте пороги и веса, добавляйте драйверы (роль пользователя, стадия внедрения, план/тариф), улучшайте UX объяснения — «почему score упал» и «что сделать дальше».
Следующие шаги: прогноз риска, рекомендации действий (playbooks), новые интеграции и автосинхронизация статусов. Связанные материалы можно собрать в /blog, а планы и упаковку продукта — на /pricing.
Adoption Health Score — это сводная оценка (например, 0–100), которая показывает, насколько клиент продвигается к ценности продукта на основе фактического использования.
В отличие от разрозненных метрик, score помогает быстро ответить на два вопроса: где риск и что делать дальше.
NPS и опросы отражают восприятие и часто запаздывают, а выручка и платежи показывают коммерческий итог, но не объясняют причины.
Adoption Health Score измеряет поведение в продукте (действия, прогресс онбординга, использование фич) и поэтому лучше подходит для ранних действий команды Customer Success.
Начните с 3–7 сигналов, которые можно улучшить конкретными действиями команды:
Избегайте «метрик ради метрик»: навигационные клики обычно не отражают внедрение.
Практичный старт — взвешенная сумма с нормализацией и шкалой 0–100.
Пример логики:
Важно хранить «расшифровку»: вклад блоков и топ‑факторы изменения за период, чтобы score был объяснимым.
Используйте окна 7/30/90 дней и сравнение периодов: это помогает ловить тренды, а не только текущий уровень.
Практика:
Отдельно полезно отслеживать изменение score (дельту), например −20 пунктов за 7 дней.
Заранее выберите основную единицу анализа: чаще всего организация (customer), а детализацию делайте по workspace и пользователям.
Минимальные сущности для старта:
В событиях держите минимум: , , , плюс идентификаторы пользователя.
Типовая цепочка: трекинг → очередь/ETL → хранилище → витрины.
Чтобы не «сломать» скоринг:
event_version и правила совместимостиДля большинства B2B сценариев достаточно ежедневного пересчёта: он дешевле, проще и обычно соответствует скорости реакции команды.
Почти real‑time имеет смысл, если:
В интерфейсе полезно показывать «актуальность данных» и лаг загрузки, чтобы избежать неверных выводов.
Минимум, который реально помогает работать:
UX‑правило: каждый показатель должен вести к действию (фильтр, задача, следующий шаг).
Начните с простых правил и назначайте одного ответственного на каждый алерт:
Снижайте шум:
customer_idtimestampevent_nameevent_time и ingestion_time, чтобы учитывать задержки доставки данных