Пошаговый план создания веб‑приложения для управления workflow изменений: роли, этапы согласования, модель данных, аудит, интеграции, безопасность и запуск MVP.
Веб‑приложение для управления изменениями (change management) становится нужным, когда изменения в ИТ‑сервисах и бизнес‑процессах перестают «помещаться в почте и чатах». Цель такого решения — сделать поток изменений управляемым: понятно, что меняем, кто согласовал, кто выполняет, когда можно выкатывать и что делать, если что‑то пойдёт не так.
Главная ценность — прозрачность и контроль без лишней бюрократии.
Инициатор создаёт запрос на изменение: описывает цель, затронутые системы, сроки, прикладывает план внедрения и отката.
Согласующий (например, ИБ, архитектура, бизнес) оценивает риски и последствия и принимает решение.
Владелец сервиса подтверждает приоритет и окно работ, помогает снять конфликты.
Исполнитель планирует и выполняет работы, отмечает шаги и результаты.
Аудитор просматривает историю: кто и на каком основании принимал решения.
Успех должен быть измеримым: сокращение среднего времени согласования, меньше экстренных «пожаров», ниже доля откатов и инцидентов после изменений, соблюдение сроков и заранее заданных критериев качества.
В MVP обычно входят: создание и поиск заявок, статусы и базовые согласования, чек‑лист рисков, комментарии и вложения, журнал действий.
Дальше продукт расширяют: гибкие маршруты согласований, шаблоны изменений, SLA и уведомления, отчётность и интеграции (например, с ITSM), чтобы процесс работал стабильно и предсказуемо.
Прежде чем рисовать экраны и выбирать стек, важно договориться о том, что именно приложение делает, а что — нет. Для change management это критично: без границ вы быстро получите «комбайн», который сложно согласовывать, поддерживать и обучать.
Начните с классификации изменений. Обычно выделяют:
От типа изменения зависят обязательные шаги, сроки и набор согласующих.
Заранее определите минимальный состав данных, без которых заявка не может двигаться дальше: сервис/компонент, среда (prod/test), описание, план внедрения и отката, оценка рисков/влияния, контактные лица, предполагаемое окно работ.
Отдельно зафиксируйте требования к вложениям: например, скриншоты, выгрузки из мониторинга, чек‑лист тестов, подтверждения от владельца сервиса. Это снижает количество возвратов «на доработку».
Опишите маршрутизацию по критичности, сервису и среде: разные владельцы, разные уровни согласования, разные требования к проверкам.
Параллельно задайте ограничения: SLA на этапы (например, оценка риска за 8 часов), окна изменений, блокировки на праздничные периоды, зависимости (нельзя выпускать изменение, пока не закрыта связанная задача).
Сформируйте список «как должно работать»: производительность (время открытия карточки), доступность (целевой аптайм), хранение и сроки ретенции данных, резервное копирование, логирование и требования к поиску по заявкам. Эти пункты позже станут критериями приёмки и выбора архитектуры.
Чтобы процесс управления изменениями не превращался в «общий чат», важно заранее зафиксировать ролевую модель: кто и что может делать, в каких пределах и как система ведёт себя при отсутствии ключевых людей.
Минимальный набор ролей на практике выглядит так:
Важно разделять «кто согласует» и «кто внедряет»: это снижает риск ошибок и конфликт интересов.
Доступы удобнее выдавать не «по людям», а по зонам ответственности:
Так вы избегаете ситуации, когда сотрудник видит и может менять чужие заявки «просто потому что у него роль».
Выдавайте минимально необходимый набор прав: просмотр, комментирование, редактирование, согласование, запуск внедрения, закрытие. Админ‑функции (управление справочниками, настройка ролей, политики доступа, массовые операции) лучше выделить в отдельную роль и логировать отдельно.
Продумайте два механизма:
В заявке должно быть видно, кто согласовал «за кого» и на каком основании — это важно для проверок.
Если в компании есть единый вход, поддержите SSO и синхронизацию пользователей/групп через LDAP/AD: меньше ручной работы и быстрее отзыв доступов при увольнении.
Если SSO нет, задайте понятную политику паролей: минимальная длина, запрет повторов, ограничение попыток входа, обязательная двухфакторная аутентификация для привилегированных ролей (администраторы, владельцы изменений).
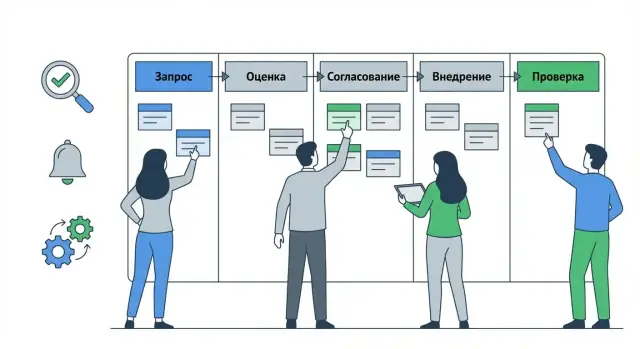
Workflow — «скелет» change management: он фиксирует, где сейчас находится изменение, кто должен принять решение и какие проверки обязательны. Чем точнее заданы статусы и правила переходов, тем меньше ручных уточнений и тем предсказуемее сроки.
Практичный набор статусов, который покрывает большинство процессов:
Согласование часто выполняет не один человек, а группа — важно формализовать политику:
Для параллельных согласований заранее определите, что происходит при первом отказе: стоп процесса, возврат на доработку, либо запрос дополнительных данных без смены статуса.
Один workflow «на все случаи» обычно неудобен. Лучше сделать шаблоны под разные типы изменений (стандартные, нормальные, экстренные) с разным набором обязательных шагов.
Добавьте условия переходов: по риску, влиянию, стоимости, затрагиваемым системам. Например: если риск высокий или затронуты критичные сервисы — автоматически включается дополнительное согласование безопасности и требуется план отката.
Регламент со временем меняется, и приложение должно переживать это без хаоса. Практика такая:
Так вы сохраните сопоставимость отчётов и сможете объяснить, почему два изменения проходили разные шаги.
Данные — основа приложения для управления изменениями: если модель продумана, согласования не теряются, поиск работает быстро, а аудит не вызывает вопросов.
Обычно достаточно базовых объектов:
Как правило, один Change Request связан с множеством Approval и Task. Комментарии и вложения также привязаны к запросу (и при необходимости — к конкретной задаче).
Отдельно стоит поддержать зависимости между изменениями: «блокирует», «зависит от», «связан с». Это помогает избегать конфликтов при параллельных релизах.
Справочники (статусы, сервисы, типы риска) лучше хранить отдельно, чтобы не плодить дубликаты. Для быстрого поиска критичны индексы по:
Историю правок полей удобно вести отдельной таблицей событий: кто / что изменил / когда / старое значение / новое значение. Это облегчает расследования и отчётность.
Вложения чаще хранят в объектном хранилище, а в БД — только метаданные и ссылку. Если требования строгие, допускается хранение в БД, но это дороже для резервного копирования.
Сразу задайте ограничения по размеру и типам файлов (например, PDF/DOCX/PNG), правила антивирусной проверки и сроки хранения.
Интерфейс change management «живёт или умирает» на скорости: насколько быстро пользователь находит «своё» изменение, понимает, что от него требуется, и не ошибается в данных. Поэтому UX/UI лучше проектировать вокруг типовых ролей (инициатор, согласующий, CAB, исполнитель) и их ежедневных задач.
Базовый набор экранов обычно такой:
Важно, чтобы список работал как «панель управления»: массовые действия (назначить, запросить уточнение), быстрый предпросмотр, понятные метки приоритета и риска.
Форма создания изменения должна вести пользователя по шагам: подсказки, примеры, и обязательные поля только там, где без них нельзя управлять рисками. Хорошо работают:
В карточке нужен виджет, который мгновенно отвечает на вопросы: какой этап, кто сейчас согласует, какой дедлайн, что блокирует переход.
Для разных ролей полезны сохранённые фильтры («Мои на согласование», «Просроченные», «Готово к CAB») и быстрый поиск по номеру/сервису/ключевым словам.
Статусы должны быть однозначными и читаться без расшифровок: одинаковые цвета и названия на всех экранах, предупреждения перед критическими действиями (например, «Отправить в внедрение»), минимизация ручного ввода через справочники и автозаполнение. Это снижает «шум» в данных и повышает доверие к отчётам и SLA.
Уведомления — «нервная система» change management: они сокращают время согласования, помогают соблюдать SLA и уменьшают риск, что критичное изменение останется без внимания. Интеграции же устраняют ручной перенос данных между системами и повышают качество учёта.
Практичный базовый набор:
Сразу предусмотрите настройки: кто и какие типы событий получает, «тихие часы», а также возможность приглушать шумные уведомления без потери критичных.
В change management чаще всего нужны уведомления по событиям:
Полезно различать «информирование» и «требуется действие». Во втором случае текст должен отвечать на три вопроса: что сделать, до какого времени и куда перейти.
Шаблоны сообщений удобно собирать как конструктор: переменные (номер изменения, сервис, риск, окно работ, ссылка на карточку), короткое резюме и блок «следующие шаги». Если у компании несколько языков, закладывайте локализацию текста уведомлений и единый глоссарий терминов (например, «изменение», «RFC», «окно работ»), чтобы не возникало двусмысленности.
Типовые сценарии интеграций:
Удобнее строить обмен данными на событийной модели: приложение публикует события (например, change.created, change.status_changed, sla.breached), а внешние системы подписываются.
Чтобы обмен был надёжным, заложите:
Такой подход делает интеграции предсказуемыми: даже если одна из систем «просела», данные догоняются без ручных разборов.
Change management почти всегда упирается не только в удобный workflow, но и в доказуемость: кто что сделал, когда и на основании чего. Поэтому аудит и отчётность лучше проектировать сразу, а не «прикручивать» после первых инцидентов.
К журналу обычно предъявляют три базовых требования: неизменяемость, полнота и возможность экспорта.
Неизменяемость — защита от «подчистки хвостов». На практике помогает подход append‑only (только добавление), технические ограничения на редактирование, а также фиксация контрольных сумм/цепочек событий на уровне хранения.
Полнота — перечень событий, которые реально нужны проверяющим и владельцам процесса. Помимо создания заявки и смены статусов, обычно фиксируют:
Сроки хранения задаются регламентом: например, 1–3 года для обычных изменений и дольше — для критичных контуров. Полезно предусмотреть архивирование (чтобы не перегружать основную БД) и удаление по регламенту с подтверждаемым актом: кто инициировал, на каком основании, что именно удалено.
Отчёты должны отвечать на вопросы: как согласовывали, почему отклонили, как часто откатывались и где нарушали SLA. Минимальный набор: история согласований по изменению, статистика причин отказов, анализ откатов по системам/командам.
Для проверок выделите роль аудитора: доступ только на чтение, расширенный поиск, фильтры и готовые выгрузки в CSV/PDF. Хороший ориентир — возможность собрать пакет доказательств по одному изменению за пару минут, без запросов к разработчикам.
Безопасность в приложении для управления изменениями — это не только «пароли и доступ», а гарантия того, что согласования нельзя подменить, данные не утекут, а действия пользователей можно восстановить по следам. Ниже — практичный минимум, который стоит заложить ещё на этапе проектирования.
Начните со стандартной «гигиены» веб‑приложения:
Для change management критичны три класса рисков:
Отсюда следуют требования: строгая ролевая модель, неизменяемый аудит и ограничения на критичные операции (например, запрет редактировать заявку после перевода в определённый статус).
Логи приложения нужны для диагностики (ошибки, производительность) и обычно живут в системе логирования. Аудит — юридически и операционно значимый след: кто и когда создал change, изменил поля, перевёл статус, дал/отозвал согласование, приложил файл.
Аудит лучше хранить отдельно от «обычных» таблиц (или хотя бы как неизменяемые записи), с привязкой к пользователю, роли, времени, IP/устройству и корреляционному ID запроса.
Шифрование в транзите обеспечивает HTTPS. Шифрование при хранении включайте по необходимости: когда есть персональные данные, коммерческая тайна, требования регуляторов или размещение в облаке. Отдельно продумайте управление ключами и доступ к резервным копиям.
Определите ориентиры:
Далее настройте регулярные бэкапы базы и файлов, периодически проверяйте восстановление на тестовом контуре и фиксируйте результаты. Это часто важнее, чем «идеальная» схема на бумаге.
Архитектура change management‑приложения должна поддерживать два противоположных требования: быстрое развитие на старте и предсказуемое масштабирование, когда появятся интеграции, SLA и отчётность.
Для MVP чаще всего разумен модульный монолит: один деплой и единая база, но код разделён на доменные модули (Заявки, Согласования, Календарь изменений, Уведомления, Интеграции). Так проще поддерживать целостность workflow и аудита.
Когда продукт «обрастает» внешними системами и нагрузкой, отдельные модули можно выносить в сервисы (например, уведомления или интеграции) без переписывания всего приложения.
API — это контракт между фронтендом, интеграциями ITSM и внутренними автоматизациями.
Независимо от выбора заложите:
/api/v1/...), чтобы изменения не ломали интеграции;Workflow change management почти всегда требует асинхронных задач: рассылки, синхронизации, пересчёта метрик SLA, генерации отчётов.
Используйте очереди задач (например, RabbitMQ, Kafka, Redis Streams) и воркеры для:
Это снижает время отклика интерфейса и делает систему устойчивее к сбоям внешних API.
Практичный набор: фронтенд на React/Vue/Angular; бэкенд на Node.js (Nest), Java (Spring), .NET или Python (Django/FastAPI); база данных — чаще PostgreSQL. Для быстрого поиска по журналу и комментариям может пригодиться Elasticsearch/OpenSearch.
Чтобы понимать, «где болит», нужны:
Наблюдаемость стоит закладывать сразу: в change management важно не только обработать изменение, но и доказать, что процесс контролируемый.
Если задача — быстро собрать рабочий MVP и при этом не «просесть» по безопасности, журналированию и ролям, удобно стартовать с платформы, которая ускоряет создание web‑приложений и типовой инфраструктуры.
Например, TakProsto.AI — vibe‑coding платформа для российского рынка: приложение собирается из диалога в чате, а под капотом используется агентная архитектура и LLM. На практике это помогает быстрее пройти путь от прототипа до работающего контура (формы, роли, статусы, уведомления, базовые интеграции), сохраняя возможность экспорта исходников, деплоя и хостинга, а также снимков и отката (rollback).
Для change management обычно особенно полезны:
Хороший план разработки для change management начинается не с технологий, а с договорённости: что именно считается «работает» в первой версии и как измеряется успех. MVP должен закрыть базовый контур процесса и сразу давать пользу операционным командам.
В MVP обычно входят:
Важно: лучше сделать один тип процесса «сквозным», чем пять типов «частично».
Формулируйте требования как пользовательские истории: «Как инициатор я хочу… чтобы…». К каждой истории добавляйте критерии приёмки: какие статусы меняются, какие поля обязательны, кому приходит уведомление, что пишется в журнал. Это снижает разночтения и ускоряет тестирование.
До начала программирования соберите кликабельный прототип ключевых экранов (создание заявки, карточка, лента согласования, журнал). Проведите короткий тест с 5–7 пользователями из разных ролей: где они «застревают», какие поля непонятны, что должно быть видно сразу.
Разбивайте работу на небольшие задачи, вводите обязательные ревью и единые стандарты (именование полей, события аудита, ошибки). Планируйте релизы итерациями 1–2 недели, фиксируя состав версии и правила отката.
Самые частые риски — интеграции (ITSM, почта/мессенджеры), миграция данных и требования безопасности. Заложите время на доступы, тестовые стенды, согласование форматов и модель прав. Риск снижает ранний «сквозной» прототип: от создания заявки до уведомления и записи в журнал.
Даже хорошо спроектированный workflow управления изменениями может «сломаться» на реальных данных и привычках людей. Поэтому важны три вещи: проверка ключевых сценариев, аккуратный запуск и понятный процесс улучшений.
Начните с юнит‑тестов на правила переходов и валидации: статусные ограничения, обязательные поля, расчёт сроков/SLA, права ролей.
Интеграционными тестами проверьте связки: создание change‑заявки → уведомления → запись в аудит → синхронизация с ITSM/каталогом сервисов.
E2E‑тесты (сквозные) должны повторять «живые» истории: срочное изменение, стандартное изменение по шаблону, отклонение с возвратом на доработку, экстренный откат.
Нагрузочное тестирование делайте по узким местам: список заявок, фильтры, массовые уведомления, отчёты. Часто достаточно модели «пикового окна» — например, еженедельного CAB.
Согласующие редко готовы экспериментировать в боевой системе. Дайте им отдельную среду с обезличенными примерами, типовыми шаблонами изменений и «копией» маршрутов. Хорошая практика — фиксированный набор тест‑кейсов, который прогоняют перед каждым релизом.
Запуститесь на одной команде или сервисе с понятными границами: какие типы изменений ведём в системе, а какие — пока нет. Собирайте обратную связь не «в целом», а по метрикам: время согласования, доля возвратов на доработку, количество ручных действий, просрочки SLA.
Если переходите со старых инструментов, определите минимум для миграции: активные изменения, справочники, шаблоны, пользователей. Исторические данные часто достаточно загрузить как архив (read‑only) или прикреплённые файлы, чтобы не усложнять модель.
Назначьте владельца продукта и регламент обработки инцидентов: приоритеты, время реакции, канал обращений. Улучшения планируйте по данным — отчёты по этапам, причинам отклонений и узким местам. Периодически пересматривайте правила workflow: бизнес меняется, и маршруты должны меняться вместе с ним.
Начните с фиксации целей процесса: что считается «успешным изменением» (сроки, инциденты после внедрения, доля откатов, соблюдение окна). Затем опишите роли и минимальный workflow (статусы + правила переходов).
Практичный первый контур: карточка изменения → согласования → планирование окна → выполнение → проверка → закрытие с неизменяемым аудитом.
Ключевой признак — изменения перестали «помещаться» в почте/чатах: теряются решения, непонятны ответственные, трудно восстановить историю.
Если регулярно возникают споры «кто согласовал» и «почему выкатывали», или участились экстренные внедрения без пост‑фиксации — пора переносить процесс в систему с карточками, статусами и аудитом.
Обычно выделяют:
От типа изменения зависят обязательные поля, состав согласующих, SLA на этапы и требования к плану отката.
Минимальный набор, без которого заявка не должна двигаться дальше:
Сразу определите требования к вложениям (чек‑листы, подтверждения, выгрузки), чтобы снизить «возвраты на доработку».
Разделяйте минимум: инициатор, согласующие, исполнитель, ответственный за закрытие.
Назначайте доступы не «по людям», а по зонам ответственности (команда/сервис/подразделение/среда). И фиксируйте принцип наименьших привилегий: просмотр ≠ редактирование ≠ согласование ≠ закрытие.
Обязательно продумайте:
В карточке изменения должно быть видно, кто согласовал «за кого» и на каком основании. Это снижает риск блокировок и помогает при проверках.
Практичный набор статусов:
Дополнительно: Отклонено (с причиной) и Отменено (если остановили после старта). Главное — чётко описать, какие поля обязательны для каждого перехода и кто имеет право переводить статус.
Задайте политику принятия решения:
Отдельно решите, что происходит при первом отказе: стоп процесса, возврат на доработку или запрос уточнений без смены статуса.
Минимальная модель данных обычно включает:
Обязательно заложите:
Для аудита удобна отдельная таблица событий: кто/что/когда/старое/новое.
Разделите логи и аудит: логи — для диагностики, аудит — доказуемый след действий.
В аудит обычно пишут:
Для надёжности используйте подход append-only (только добавление) и экспорт в CSV/PDF для проверок.