Разбираем, зачем нужны реплики чтения, как они уменьшают нагрузку на базу и в каких сценариях действительно полезны — с рисками и примерами.
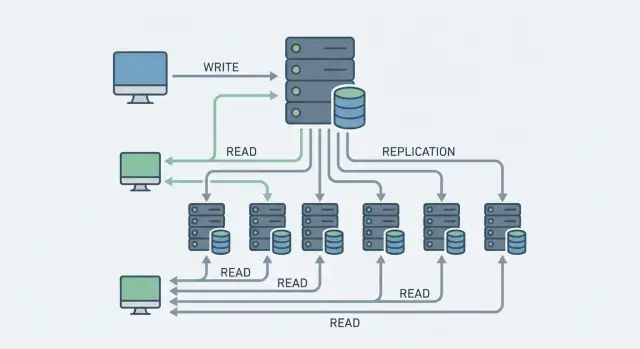
Реплика чтения (read replica) — это копия основной базы данных, на которую отправляют запросы только на чтение. Основная база (её часто называют primary, master или writer) принимает и записи, и чтения, а реплики — обычно только чтения.
Идея простая: разгрузить «главную» точку записи и ускорить ответы там, где данных читают много.
Частый путь к репликам выглядит так: приложение растёт, пользователи чаще открывают страницы, отчёты, ленты, карточки товаров — то есть доля чтений становится сильно выше доли записей. В какой‑то момент база начинает упираться в ресурсы (CPU, диски, соединения), хотя запись при этом не обязательно тяжёлая.
Реплики чтения помогают масштабировать чтение горизонтально: можно добавить ещё одну копию и распределить SELECT‑запросы между ними. Это особенно заметно на «длинных» выборках (аналитические запросы, выгрузки), которые мешают быстрым операциям в основной базе.
Ниже разберём, когда реплики действительно дают прирост, где они бесполезны или вредны, какие ограничения по консистентности придётся принять, и какие есть альтернативы (кэш, оптимизация запросов, витрины данных).
Реплики чтения — это в первую очередь способ разделить нагрузку. Основная база (primary) продолжает принимать записи и критичные операции, а значительная часть чтений (поисковые выдачи, карточки товаров, списки заказов, отчёты для менеджеров) уходит на реплики.
В результате вы перестаёте «соревновать» чтения и записи за одни и те же ресурсы: CPU, диск, кеш и соединения.
Частая ситуация: записи идут ровно, а чтения растут быстрее — например, из‑за новых витрин, аналитики, интеграций или просто увеличения аудитории.
Реплики позволяют масштабировать именно чтение, добавляя ещё один экземпляр базы для запросов SELECT, без радикальных изменений схемы и прикладной логики.
В период распродаж, рассылок или после выхода в медиа нагрузка обычно «взлетает» неравномерно. Реплики дают буфер: вы можете временно распределить чтения между несколькими узлами и выдержать пик без немедленного увеличения мощности primary.
Это особенно полезно, когда апгрейд основной базы требует окна работ, миграций или дорогих ресурсов.
Реплика не исправит плохой запрос. Если узкое место — отсутствие индекса, тяжёлая сортировка, N+1 запросы или «раздутая» выдача, то перенесённый на реплику запрос останется тяжёлым — просто будет нагружать другой сервер.
Реплики хорошо дополняют оптимизацию, но не заменяют её.
Когда часть чтений уходит на реплики, на primary становится меньше конкуренции за ресурсы и соединения. Как следствие — короче очереди запросов, меньше ситуаций, когда чтение мешает записи (и наоборот), и более предсказуемые задержки.
Для бизнеса это превращается в простую вещь: сайт и админка реже «залипают» в моменты нагрузки, а операции записи проходят ровнее.
Представьте базу данных как «центр принятия решений». Primary (главный сервер) принимает все операции записи: INSERT/UPDATE/DELETE, транзакции, блокировки и проверку ограничений.
Реплики чтения (read replicas) — это копии, которые получают изменения с primary и в основном отвечают на SELECT‑запросы.
Primary фиксирует изменения, а затем передаёт их репликам по специальному каналу репликации (в PostgreSQL это журнал WAL, в MySQL — binlog). Реплика применяет эти изменения у себя и становится «почти такой же», но с небольшой разницей во времени.
Важно: реплика обычно не «вычисляет» изменения заново, а воспроизводит их в том же порядке. Поэтому нагрузка на primary снижается именно за счёт вынесения чтений.
На практике часто выбирают «почти всегда асинхронно» и отдельно решают, какие запросы критичны к свежести.
Задержка репликации — это отставание реплики от primary. Причины простые: пики записи, медленное применение изменений, сетевые задержки, обслуживание реплики.
Следствие — на реплике вы можете прочитать данные, которые были актуальны секунду (или больше) назад. Поэтому и говорят: «данные могут быть не самые свежие».
Чтобы всё работало, запросы нужно направлять правильно:
Ключевой момент: для операций, где важно увидеть результат только что выполненной записи (например, после оформления заказа), чтение лучше временно отправлять на primary. Иначе вы столкнётесь с эффектом «я записал, но не вижу».
Реплики чтения дают максимальную отдачу там, где нагрузка почти целиком состоит из SELECT, а качество сервиса важнее абсолютной «свежести» данных в каждую миллисекунду.
Ниже — ситуации, в которых read replicas обычно окупаются быстро.
Классический сценарий: пользовательские интерфейсы, где люди часто открывают списки, фильтруют, переходят по страницам. Записей сравнительно мало (публикации, обновления цен, остатки), а чтений — на порядок больше.
Перенос части чтений на реплики помогает:
Отчётность часто выглядит как тяжёлые агрегации, широкие сканы таблиц, сортировки и сложные JOIN. Даже если они запускаются редко, в момент выполнения могут заметно замедлить основную базу.
Вынос отчётов на реплику позволяет отделить «операционную» нагрузку от аналитической. Важно заранее принять, что цифры могут отставать из‑за задержки репликации.
Выгрузки для бухгалтерии, партнёров, CRM, регулярные синхронизации и фоновые проверки — типичные кандидаты на реплику. Такие задачи часто выполняют длинные чтения и держат соединения, увеличивая давление на primary.
На реплике это обычно менее рискованно для пользовательского опыта.
Если пользователи часто фильтруют по одним и тем же полям, реплика может забрать большую часть однотипных чтений. Это полезно, когда кэш ограничен (разные параметры, быстро меняющийся ассортимент) или данные слишком объёмные.
Если узкое место в записи (частые UPDATE/INSERT, блокировки, высокий WAL/бинлог), реплики не увеличат «пропускную способность» primary по записи.
Более того, при очень высокой скорости изменений реплики могут начать отставать, и выигрыш от распределения чтений окажется меньше ожидаемого.
Реплики чтения ускоряют выдачу данных и разгружают primary, но за это почти всегда платят задержкой репликации: изменения сначала записываются в primary, а на реплики доезжают через некоторое время.
Типичный кейс: человек обновил профиль (имя, аватар, телефон), получил сообщение «сохранено», а на следующей странице или после перезагрузки видит старые данные.
Запись уже в primary, но чтение пошло с реплики, которая ещё не успела применить изменения.
Реплики чаще всего дают «почти сразу» или «в итоге» — и это нужно честно закладывать в поведение продукта.
Есть несколько практичных паттернов:
Для критичных операций лучше не рисковать неактуальными данными: платежи, остатки/балансы, права доступа, одноразовые коды, антифрод-лимиты.
Там чтение «старого» может стоить денег или безопасности.
В интерфейсе и ответах поддержки полезно объяснять эффект без технических обещаний: «Обновление может отобразиться не сразу и занять до N секунд». Это снижает тревожность и количество обращений, даже если задержка случается редко.
Реплики чтения часто выглядят как «добавили пару узлов — и стало быстрее». На практике вы покупаете не только производительность, но и новую порцию операционных задач.
И чем больше реплик, тем больше «мелких» деталей, которые внезапно становятся критичными.
Во‑первых, больше узлов — больше всего остального: мониторинг, алерты, обновления, управление доступами, секретами и ролями.
Отдельная статья — бэкапы: реплика не равна бэкап, но хранить и проверять резервные копии всё равно нужно. Иногда бэкапы делают именно с реплик, чтобы не нагружать primary.
Во‑вторых, сеть. Репликация — это постоянный поток изменений. При больших объёмах записи и при размещении в разных зонах/регионах растут задержки и стоимость трафика, а узкие места в сети начинают влиять на «свежесть» данных на репликах.
Самый частый риск — отставание реплики (replication lag). Пользователь может записать данные и тут же не увидеть их в интерфейсе, если чтение ушло на реплику. Это превращается в «призрачные» баги: всё работает, но иногда «пропадают» свежие изменения.
Есть и риск разъезда схемы: миграции, новые индексы и изменения типов должны доходить и применяться одинаково. Если часть запросов начинает выполняться на реплике со старой схемой, получите ошибки, которые сложно воспроизвести.
Отдельный класс проблем — ошибки маршрутизации чтений. Неправильные настройки пула соединений, драйвера или прокси могут отправлять «не то» чтение «не туда»: например, часть запросов снова уходит на primary и перегружает его, а вы долго ищете причину, почему реплики «не помогают».
Реплика — плохая замена базовой гигиене производительности. Если запросы медленные из‑за отсутствующих индексов, неудачных планов, N+1 в приложении или бесконтрольных выборок без лимитов, вы просто размножите проблему на несколько серверов.
Часто проще и дешевле начать с альтернатив или сочетаний: кэш для горячих чтений, точечная оптимизация запросов и индексов, а иногда — вертикальное масштабирование primary.
Реплики стоит включать тогда, когда вы уверены, что упираетесь именно в масштабирование чтения, а не в качество запросов.
Реплики чтения (read replicas) — не «модная опция», а ответ на конкретные симптомы в работе базы данных.
Решение обычно созревает тогда, когда масштабирование чтения упирается в пределы одного primary: даже после оптимизации запросов и индексов чтение начинает мешать записи или просто «съедает» ресурсы.
Смотрите на картину целиком, а не на одну цифру:
Прежде чем добавлять PostgreSQL репликацию или MySQL репликацию, выясните, какие запросы самые тяжёлые:
Пороговые значения выбирайте от требований продукта: где допустимы слегка «неактуальные данные», а где нет.
Полезно отдельно алертить:
Регулярно тестируйте сценарии, где пользователь ожидает увидеть результат сразу: создание заказа, смена пароля, оплата.
Если такие запросы иногда попадают на реплику — вы увидите это раньше клиентов.
Когда лаг растёт, важно иметь простой «режим деградации»:
Маршрутизация чтений — это не «переключили часть SELECT на реплику и забыли». Главная цель — снять нагрузку с primary, не создавая скрытых багов из‑за задержки репликации и разной актуальности данных.
На реплики обычно безопасно уводить тяжёлые, но не критичные к свежести запросы: списки, каталоги, поисковую выдачу, отчёты, витрины «для просмотра».
Опасная зона — запросы, которые пользователь ожидает увидеть «сразу после действия»: проверка статуса платежа, наличие товара после резерва, права доступа сразу после изменения ролей.
Практическое правило: если чтение следует за записью в рамках одного пользовательского сценария, по умолчанию читайте с primary (или используйте механизм read-your-writes, если он у вас есть).
Частый и понятный подход:
Так вы снижаете риск «странных» багов: администратор терпимее к задержке в несколько секунд, чем клиент, который только что нажал «Оплатить».
Если есть пользователи в разных географиях, реплики рядом с ними уменьшают сетевую задержку.
Но между регионами задержка репликации обычно выше, поэтому критичные проверки лучше закреплять за primary (или за репликой в том же регионе, что и запись), а «просмотровые» страницы — отдавать локально.
Реплика может «упасть» не от CPU, а от тысяч коннектов. Используйте пул соединений, ограничивайте параллелизм тяжёлых отчётов, задавайте timeouts.
Иначе реплики станут новой точкой отказа.
Начните с одной реплики и измерьте эффект. Добавляйте реплики, когда упираетесь в CPU/IO или растёт время ответа на чтения.
Пересматривайте правила маршрутизации после крупных релизов: новые запросы часто незаметно становятся «тяжёлыми» и требуют отдельного маршрута.
Если вы быстро собираете сервис и нагрузка на чтение начинает расти раньше, чем вы ожидали, полезно заранее заложить в архитектуру разделение чтения/записи и политику консистентности.
Например, в TakProsto.AI (vibe‑coding платформа для российского рынка) приложения обычно строятся на React + backend на Go с PostgreSQL, и именно на таких стеках вопрос «куда отправлять SELECT после записи» всплывает довольно рано: в админке и отчётах реплики дают выигрыш, а в критичных пользовательских сценариях лучше закреплять чтение за primary. Плюс помогает то, что платформа поддерживает деплой, хостинг, снапшоты и откат — удобно тестировать правила маршрутизации и деградационные режимы без долгих инфраструктурных циклов.
Реплики чтения (read replicas) — не единственный способ разгрузить базу. Часто более быстрый и дешёвый эффект дают решения «до архитектуры»: кэширование, оптимизация запросов и правильная модель данных.
А иногда реплики стоит дополнять витринами или даже шардированием.
Если ваши чтения повторяются (карточки товара, профили, каталоги, публичные страницы), кэш почти всегда выигрывает у реплик: он снимает нагрузку с базы данных целиком и отдаёт ответы быстрее.
Кэш особенно хорош, когда требование к свежести данных умеренное: допустимы секунды/минуты, или есть понятный механизм инвалидации.
Сочетание с репликами выглядит так: «горячие» данные уходят в Redis или HTTP‑кэш, а всё остальное чтение распределяется по репликам. Это уменьшает число запросов к PostgreSQL/MySQL и смягчает проблему задержки репликации, потому что часть запросов вообще не попадает в контур репликации.
Перед тем как добавлять репликацию, проверьте очевидное: медленные запросы, отсутствие индексов, N+1, лишние JOIN’ы.
Один правильный индекс или переписанный запрос нередко даёт кратный прирост производительности базы данных без роста сложности поддержки.
Плюс: оптимизация улучшает и primary, и реплики — вы не масштабируете «дорогие» запросы, а делаете их дешевле.
Если основная боль — отчёты, аналитика, тяжёлые выборки и агрегации, реплики не всегда спасают: они лишь переносят нагрузку, но не меняют природу запросов.
Здесь помогают материализованные представления/витрины: заранее рассчитанные данные под конкретные отчёты. Их можно обновлять по расписанию или инкрементально, контролируя свежесть и стоимость пересчёта.
Реплики масштабируют чтение, но не решают ограничения записи и роста объёма данных. Когда данных слишком много, а один primary становится узким горлышком по записи или по размеру, приходит время обсуждать шардирование (разделение данных по нескольким узлам).
Это сложнее, но даёт горизонтальный рост.
Реплики чтения часто воспринимают как «страховку на случай аварии». Частично это правда: если primary недоступен, у вас может остаться хотя бы источник данных для чтения, а иногда — кандидат на повышение (promotion) в новый primary.
Но реплика не гарантирует восстановление данных и не заменяет полноценную стратегию резервного копирования.
Реплика повышает доступность чтений: при падении primary вы можете продолжать отдавать отчёты, каталоги, ленты и аналитические запросы (если приложение умеет переключаться на read‑only режим).
Но важные ограничения остаются:
Бэкап — это «снимок во времени» или журнал изменений, который позволяет откатиться на нужную точку (например, до удаления таблицы).
Реплика — это копия, которая старается быть максимально похожей на primary прямо сейчас.
Практически: реплики помогают пережить инцидент доступности, а бэкапы — инцидент целостности.
Заранее решите и задокументируйте:
Периодически проводите тренировки: поднятие из бэкапа, проверка RPO/RTO, прогон чек‑листа, обновление инструкции в /runbooks.
По безопасности разделяйте роли: отдельные учётки и права для чтения (только SELECT) и для администрирования. Это снижает ущерб от компрометации приложения и случайных действий, особенно когда реплик становится несколько.
Реплики чтения — не универсальная «таблетка», а инструмент для конкретной боли. Перед тем как усложнять архитектуру, пройдитесь по чек‑листу ниже: он помогает понять, решаете ли вы проблему масштабирования чтения, а не маскируете проблемы запросов или схемы.
Стабильные задержки на чтение, предсказуемая свежесть данных и управляемые расходы (инфраструктура + поддержка).
Начните с пилота на одной реплике и маршрутизации «безопасных» чтений. Затем масштабируйте по мере подтверждённого эффекта.
Если нужно заранее прикинуть бюджет и варианты развёртывания, посмотрите уровни и возможности на /pricing.
Реплика чтения (read replica) — это копия основной базы данных, которая обслуживает запросы только на чтение (обычно SELECT). Записи (INSERT/UPDATE/DELETE) идут в primary. Это позволяет разгрузить primary и масштабировать чтение горизонтально — добавляя новые реплики под рост запросов.
Когда чтений становится существенно больше, чем записей, primary начинает упираться в CPU/диск/число соединений, а задержки чтения растут (особенно на p95/p99). Реплики позволяют распределить SELECT по нескольким узлам и уменьшить конкуренцию чтений с транзакциями записи.
Обычно через реплики выносят:
JOIN/ORDER BY/AGG);Главное условие — допустима небольшая задержка актуальности данных.
Потому что реплика не ускоряет плохой запрос — она просто переносит его на другой сервер. Если узкое место в отсутствии индексов, N+1, широких выборках без лимитов или тяжёлых сортировках, реплики не устранят причину. Часто сначала выгоднее:
Репликация идёт потоком изменений: primary фиксирует операции (например, в PostgreSQL через WAL, в MySQL через binlog), а реплика воспроизводит их у себя. Поскольку это не мгновенно, появляется задержка репликации (lag): на реплике данные могут быть на секунды «старее», чем на primary.
При асинхронной репликации primary подтверждает запись сразу, а реплики догоняют позже — это быстрее и чаще используется.
При синхронной primary подтверждает запись только после подтверждения реплики(ик) — консистентность выше, но записи медленнее и сильнее зависят от сети/здоровья реплик.
На практике часто выбирают асинхронный режим и отдельно решают, какие чтения должны идти на primary.
Самый частый симптом — эффект «записал, но не вижу»: пользователь обновил профиль/оформил действие, получил «успешно», а затем страница показывает старые данные, потому что чтение ушло на отстающую реплику.
Практичные решения:
Не стоит полагаться на реплики там, где чтение «старого» значения дорого:
Для таких потоков безопаснее читать с primary или строить отдельные механизмы консистентности (например, read-your-writes).
Минимальный набор метрик и наблюдений:
Нет: реплика помогает с доступностью чтения и иногда может стать кандидатом на failover, но она не защищает от:
Для надёжности нужны и реплики, и полноценные бэкапы с регулярной проверкой восстановления.
SELECT;Если «болит» запись (блокировки, высокий WAL/binlog), реплики чтения проблему не решат.